
StarRocks 存算分离集群采用了存储计算分离架构,特别为云存储设计。在存算分离的模式下,StarRocks 将数据存储在对象存储(例如 AWS S3、GCS、OSS、Azure Blob 以及 MinIO)或 HDFS 中,而本地盘作为热数据缓存,用以加速查询。本次我们演示HDFS和MinIO做数据存储,使用StarGo部署存算分离集群
一、MinIO部署
这里使用docker部署单机版MinIO(单机部署MinIO,不适用生产),其他部署方式可参考 https://min.io/download#/linux docker环境搭建此处省略
1.1 拉取MinIO最新镜像
docker pull minio/minio
1.2 启动容器
[root@node01~]docker run -p 9000:9000 -p 9090:9090 \
--name minio \
-d --restart=always \
-e "MINIO_ACCESS_KEY=admin" \ #自定义MINIO_ACCESS_KEY
-e "MINIO_SECRET_KEY=admin123456" \ #自定义MINIO_SECRET_KEY
-v /root/docker/minio/data:/data \
-v /root/docker/minio/config:/root/.minio \
minio/minio server\
/data --console-address ":9090" -address ":9000" #9000 服务端口; 9090 web端控制台端口(两个端口都可以自定义)
1.3 登录MinIO web端
使用自定义的 ACCESS_KEY,SECRET_KEY 登录MinIO web页面 : http://192.168.110.225:9090/login
1.3.1创建Buckets
1、点击Buckets —> Create Bucket
2、输入Bucket Name
创建完成后点击下方Create Bucket按钮保存所创建的桶
1.4 获取所需MinIO对象存储信息
根据官网文档https://docs.starrocks.io/zh/docs/deployment/shared_data/minio/#%E5%AD%98%E7%AE%97%E5%88%86%E7%A6%BB%E9%83%A8%E7%BD%B2-fe-%E9%85%8D%E7%BD%AE 获取所需MinIO对象存储信息
aws_s3_path:starrocks/ ( MinIO 存储空间路径)
aws_s3_region: us-west-1 ( MinIO 存储空间的地区;注:MinIO默认region是 us-west-1 )
aws_s3_endpoint: http://192.168.110.225:9000 ( MinIO 存储空间的连接地址)
aws_s3_access_key: admin ( MinIO 存储空间的 Access Key)
aws_s3_secret_key: admin123456 ( MinIO 存储空间的 Secret Key)
二、使用StarGo部署存算分离集群
我们使用 Linux 的 root 用户进行 3fe+3be 混合部署为例,来做完整的操作演示(这里使用HDFS和MinIO做数据存储)。
1、集群部署
第一步:文件准备
将 StarGo 和 StarRocks 安装包上传到服务器,例如 /root 目录。上传完成后解压 stargo,进入解压后的目录:
[root@starrocks ~]# ll -h
-rw-r--r-- 1 root root 57M Jun 1 20:59 stargo-v2.3.tar.gz
-rw-r--r-- 1 root root 2.2G Jun 1 20:41 StarRocks-3.1.4.tar.gz
[root@starrocks ~]# tar xvf stargo-v2.3.tar.gz
[root@starrocks ~]# cd stargo-v2.3
第二步:环境检测与调优
执行环境检测脚本,并对检测异常项按照脚本给出的提示进行调整,保证脚本中除"内存"项外的其他检查项均提示 success:
[root@starrocks stargo-v2.3]# ./env_check.sh
第三步:SSH免密
StarGo 是通过 SSH 的方式进行文件分发和命令执行的,因此即便单机下是"本机到本机",仍然需要进行免密的配置(同理,若是部署多台服务器的集群,我们也需要打通 stargo 所在节点到"所有需要分发文件的节点"的 SSH 免密),例如:
[root@starrocks stargo-v2.3]# ssh-keygen -t rsa
[root@starrocks stargo-v2.3]# ssh-copy-id root@192.168.110.170
#拷贝node01 starrocks用户家目录下.ssh文件夹至集群其他所有节点
[starrocks@node01 ~]$ scp -r /home/starrocks/.ssh/ 192.168.110.171:/home/starrocks/
[starrocks@node01 ~]$ scp -r /home/starrocks/.ssh/ 192.168.110.172:/home/starrocks/
第四步:目录创建
在部署前需要进行简单的目录规划,StarGo 需要我们手动创建好"外层"的文件夹,并保证文件夹为空(主要是要求其中不能有与即将部署的服务名相同的目录,以避免误覆盖写掉之前的集群)。例如,我们将程序部署在 /opt/starrocks 目录下,将数据保存在 /data/starrocks 目录中,那么我们就需要手动创建这两个目录:
[root@starrocks stargo-v2.3]# mkdir /opt/starrocks
[root@starrocks stargo-v2.3]# mkdir -p /data/starrocks
注意:若使用的为非 root 用户,在创建文件夹后,还应注意进行目录的授权。
第五步 HDFS
1.获取HDFS信息
这里省略部署HDFS步骤
根据官网文档https://docs.starrocks.io/zh/docs/deployment/shared_data/hdfs/#%E5%AD%98%E7%AE%97%E5%88%86%E7%A6%BB%E9%83%A8%E7%BD%B2-fe-%E9%85%8D%E7%BD%AE ,需要获取HDFS存储的URL
HDFS存储URL: hdfs://192.168.110.120:8020/user/starrocks/ # 在HDFS web页面创建目录 /user/starrocks; 这里端口使用的是HDFS配置在core.xml文件里面namenode的端口;
第六步:编写YAML文件
部署程序会需要我们配置程序的部署目录、数据目录、IP、端口、参数等等,stargo 通过解析我们编写的 YAML 文件来获取这些信息。deploy-template.yaml 简单改写出我们的单节点配置文件,例如:
1.使用HDFS做数据存储, yaml修改可参考下方示例:
deploy-hdfs.md (6.5 KB)
2.对象存储为MinIO , yaml修改可参考下方示例:
deploy-MinIO.md (6.8 KB)
第七步:指定安装包路径
StarGo 当前需要使用本地的 StarRocks 安装包(即 StarRocks 安装包需要放在 StarGo 程序所在的服务器上),我们通过 repo.yaml 文件来配置对应的路径与包名,例如本次我们使用 StarRocks-3.1.4 版本,安装包路径在 /root 下:
[root@starrocks stargo-v2.3]# vim repo.yaml
#该配置文件配置部署、升级/降级或扩容时需用的StarRocks二进制包路径及包名:
sr_path: /root/
sr_name: StarRocks-3.1.4.tar.gz
第八步:执行部署命令
StarGo 部署的过程中不会访问外网,只会使用我们配置的安装包离线部署,我们指定集群名称为 sr-c1,版本为我们指定的3.1.4,配置文件为上文的deploy-demo.yaml:
[root@starrocks stargo-v2.3]# ./stargo cluster deploy sr-c1 v3.1.4 deploy-demo.yaml
执行 deploy 命令后,StarGo 会先进行目录、端口、系统参数等的检查,若服务器配置较差,这一步耗时会略长(在stargo 2.3版本,这里添加了一个跳过检查的选项,若确认服务器配置已满足要求,当测试环境检测特别慢时可以按照提示跳过环境检查)。StarGo 会将所有操作的日志打印在控制台上,部署过程中不需要我们进行手动操作,等待部署完成后检查服务,确认 FE、BE、Broker 的进程均存在即可:
[root@starrocks stargo-v2.3]# ps -ef | egrep 'StarRocksFE|starrocks_be|BrokerBootstrap'
root 16434 1 4 22:06 ? 00:00:13 /opt/starrocks/fe/jdk/bin/java -Dlog4j2.formatMsgNoLookups=true -Xmx10240m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:/opt/starrocks/fe/log/fe.gc.log.20230606-220639 com.starrocks.StarRocksFE
root 17615 1 1 22:07 ? 00:00:02 /opt/starrocks/be/lib/starrocks_be
root 18307 1 0 22:07 ? 00:00:00 /opt/starrocks/apache_hdfs_broker/jdk/bin/java -Dlog4j2.formatMsgNoLookups=true -Xmx1024m -Dfile.encoding=UTF-8 com.starrocks.broker.hdfs.BrokerBootstrap
root 18568 13157 0 22:11 pts/1 00:00:00 grep -E --color=auto StarRocksFE|starrocks_be|BrokerBootstrap
第九步:访问集群
StarRocks 部署完成后,默认启用 root 用户,密码为空,使用 mysql-client 访问 FE 的 IP 及其 9030 查询端口,即可连接到 StarRocks 进行后续操作:
[root@starrocks ~]# mysql -h192.168.125.23 -P9030 -uroot
StarRocks 兼容 MySQL 语法,我们也可以使用 DBeaver、SQLYog、DataGrip、Navicat 等可视化工具,将 StarRocks 当作 MySQL(端口使用 9030)来进行连接和查询。
注意:
当修改了 StarRocks 集群的 root 密码,我们也需要修改 StarGo 的元文件。
例如我们修改 StarRocks 集群 root 用户的密码为 root,我们用 mysql-client 或可视化工具将 StarRocks 视为 MySQL 访问,IP 使用任意 FE 的 IP,端口为 9030,访问集群:
[root@starrocks ~]# mysql -h192.168.125.23 -P9030 -uroot
修改密码后退出:
mysql> set password = password('root');
mysql> exit
在部署时我们使用的 sr-c1.yaml 拓扑文件仅用于集群部署,在部署完成后该文件可删除,StarGo 会在"工作目录"为每个集群生成对应的拓扑文件 meta.yaml 用于集群管理,集群密码信息就是需要到该文件中配置。我们切换目录到当前 Linux 用户的家目录,以当前的 root 用户为例:
[root@starrocks stargo-v2.3]# cd ##该命令表示切换到家目录,root用户家目录为'/root',其他用户为'/home/用户名'
[root@starrocks ~]# ll -a ##展示当前目录文件列表,并显示隐藏文件
total 1650892
dr-xr-x---. 8 root root 4096 Jan 14 20:10 .
dr-xr-xr-x. 19 root root 250 Jan 14 14:03 ..
drwxr-xr-x. 2 root root 6 Nov 20 2021 .m2
drwx------ 2 root root 80 Jan 14 14:08 .ssh
drwxr-xr-x 5 root root 48 Jan 14 15:01 .stargo
…………………………………………
可以看到有一个 .stargo 目录,该目录就是 StarGo 的**“本地工作目录”**,进入目录并查看:
[root@starrocks ~]# cd .stargo/
[root@starrocks .stargo]# ll
total 4
drwxr-xr-x 3 root root 19 Jan 14 19:31 cluster ##该目录保存stargo管理的所有集群的yaml拓扑文件。其下层文件夹的名称即为各个集群的集群名称,其中保存集群对应的yaml文件。不可手动清理!!!
drwxr-xr-x 4 root root 106 Jan 14 15:02 download ##该目录保存从配置目录中获取的StarRocks安装包、JDK包及二者解压后的文件,需手动清理。当前这里实现不够友好,后续版本考虑优化。
drwxr-xr-x 2 root root 4096 Jan 14 15:08 tmp ##该目录保存临时的配置文件,可手动清理。
切换至目标目录,为 meta.yaml 配置用户名和密码信息:
[root@starrocks .stargo]# cd cluster/sr-c1/
[root@starrocks sr-c1]# vim meta.yaml
clusterinfo:
user: root
version: v3.1.4
create_date: "2023-06-01 12:30:48"
meta_path: /root/.stargo/cluster/sr-c1
private_key: /root/.ssh/id_rsa
sr_user: "root" ##添加用户名root,该项只能配置为root,其他用户权限不足
sr_password: "root" ##添加密码,例如上文修改为的root
global:
user: root
ssh_port: 22
server_configs:
…………
保存退出后,就可继续使用 StarGo 进行集群的管理。
第十步:stargo 常用命令
停止集群服务:
[root@starrocks stargo-v2.3]# ./stargo cluster stop sr-c1
再次启动集群服务:
[root@starrocks stargo-v2.3]# ./stargo cluster start sr-c1
查看集群状态:
[root@starrocks stargo-v2.3]# ./stargo cluster status sr-c1
三、使用StarRocks存算分离集群
1. 基于HDFS部署
1.1 创建默认存储卷
为 HDFS 存储创建存储卷 def_volume ,并将其设置为默认存储卷
CREATE STORAGE VOLUME def_volume
TYPE = HDFS
LOCATIONS = ("hdfs://192.168.110.120:8020/user/starrocks/");
SET def_volume AS DEFAULT STORAGE VOLUME;
1.2 创建数据库和云原生表
CREATE DATABASE cloud_db;
USE cloud_db;
CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD",
region_num TINYINT COMMENT "range [-128, 127]",
num_plate SMALLINT COMMENT "range [-32768, 32767] "
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
"storage_volume" = "def_volume",
"datacache.enable" = "true",
"datacache.partition_duration" = "1 MONTH",
"enable_async_write_back" = "false"
);
2. 基于MinIO部署
2.1 创建默认存储卷
使用 Access Key 以及 Secret Key 认证为 MinIO 存储空间 starrocks bucket 创建存储卷 def_volume ,并将其设置为默认存储卷
CREATE STORAGE VOLUME def_volume
TYPE = S3
LOCATIONS = ("s3://starrocks/")
PROPERTIES
(
"enabled" = "true",
"aws.s3.region" = "us-west-1",
"aws.s3.endpoint" = "http://192.168.110.225:9000",
"aws.s3.access_key" = "admin",
"aws.s3.secret_key" = "admin123456"
);
SET def_volume AS DEFAULT STORAGE VOLUME;
2.2 创建数据库和云原生表
CREATE DATABASE cloud_db;
USE cloud_db;
CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD",
region_num TINYINT COMMENT "range [-128, 127]",
num_plate SMALLINT COMMENT "range [-32768, 32767] "
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
"storage_volume" = "def_volume",
"datacache.enable" = "true",
"datacache.partition_duration" = "1 MONTH",
"enable_async_write_back" = "false"
);
3. 创建云原生表建表失败
在建表后客户端出现 ‘Create tablet failed’ 错误提示。此时需要根据 be 日志 (be.INFO) 来查看具体的失败原因,一般来说,造成该问题的主要原因有以下几种:
-
对象存储配置错误,例如 aws_s3_path、endpoint、认证信息等配置错误
-
对象存储服务异常等
注意: StarRocks 存算分离集群暂不支持同步物化视图。
4.查看表信息
StarRocks 存算分离模式下,数据会被持久化写入后端对象存储(S3、HDFS 等),在 3.1.4 以及之后的版本中,表内数据被按照 Partition 进一步组织成为子目录,可以通过如下命令来查看表内数据的存储路径(其中 cloud_db 是 database name):
4.1 数据存储在HDFS中

可以看到存算分离集群中表的
Type 为 CLOUD_NATIVE 。
StoragePath 字段展示了该表在 HDFS 上的存储路径。通过该路径+ /partitionId可以访问:
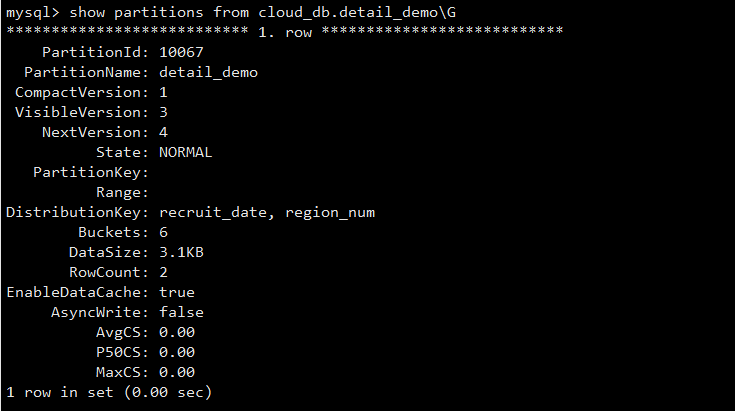

其中 data/ 存储 Segment 数据文件,而 meta/ 存储 Tablet 元数据信息
4.2 数据存储在MinIO中

可以看到存算分离集群中表的 Type 为 CLOUD_NATIVE 。
StoragePath 字段展示了该表在 S3上的存储路径。
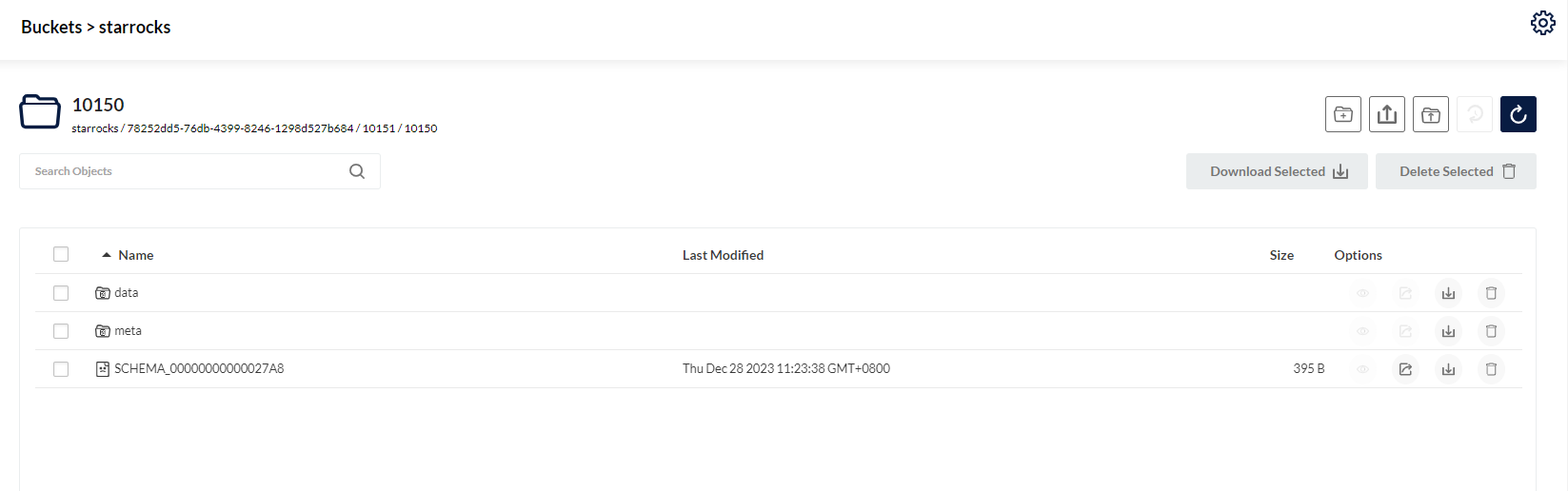
其中 data/ 存储 Segment 数据文件,而 meta/ 存储 Tablet 元数据信息