为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【是否存算分离】
【StarRocks版本】例如:2.5.10
【集群规模】3fe(1 follower+2observer)+3be(单台fe与be混部)
【机器信息】48C/128G/万兆
【联系方式】社区群4-汤米
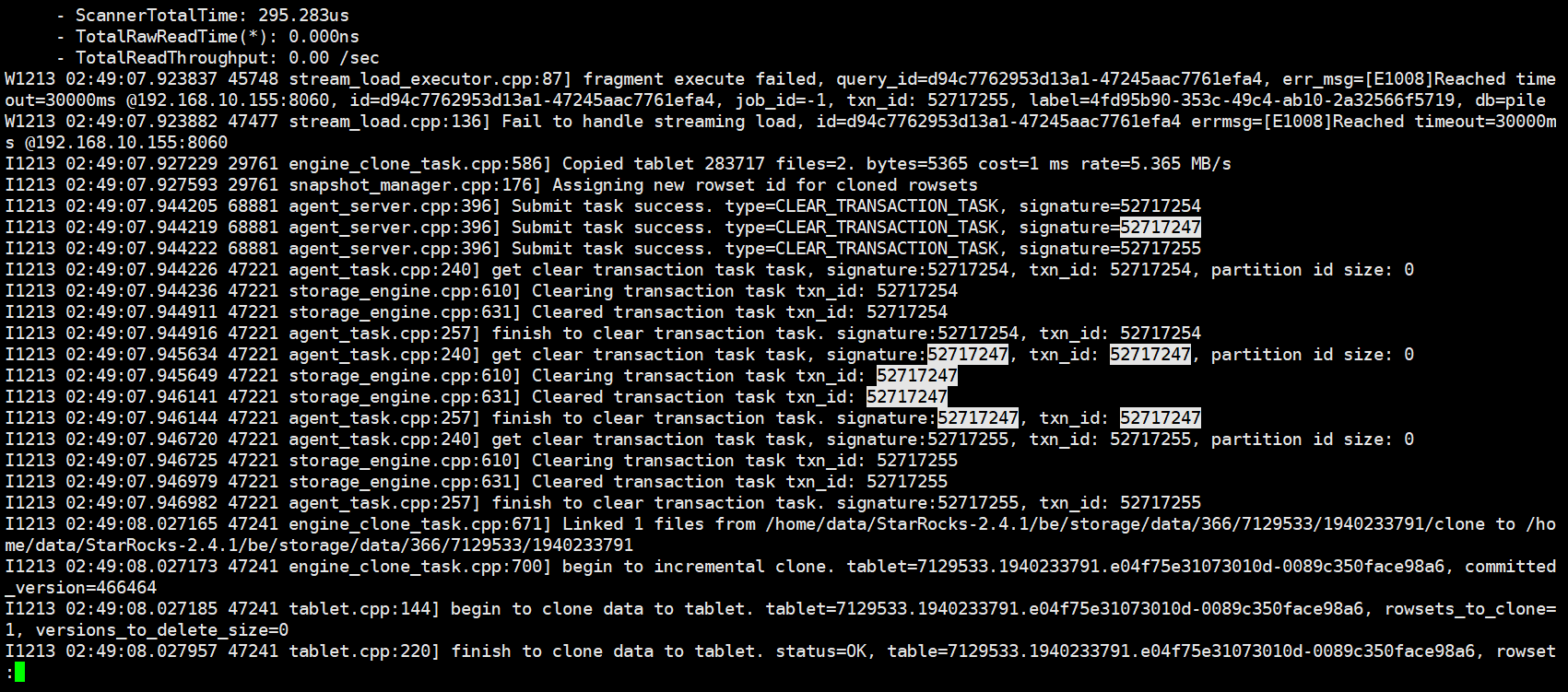
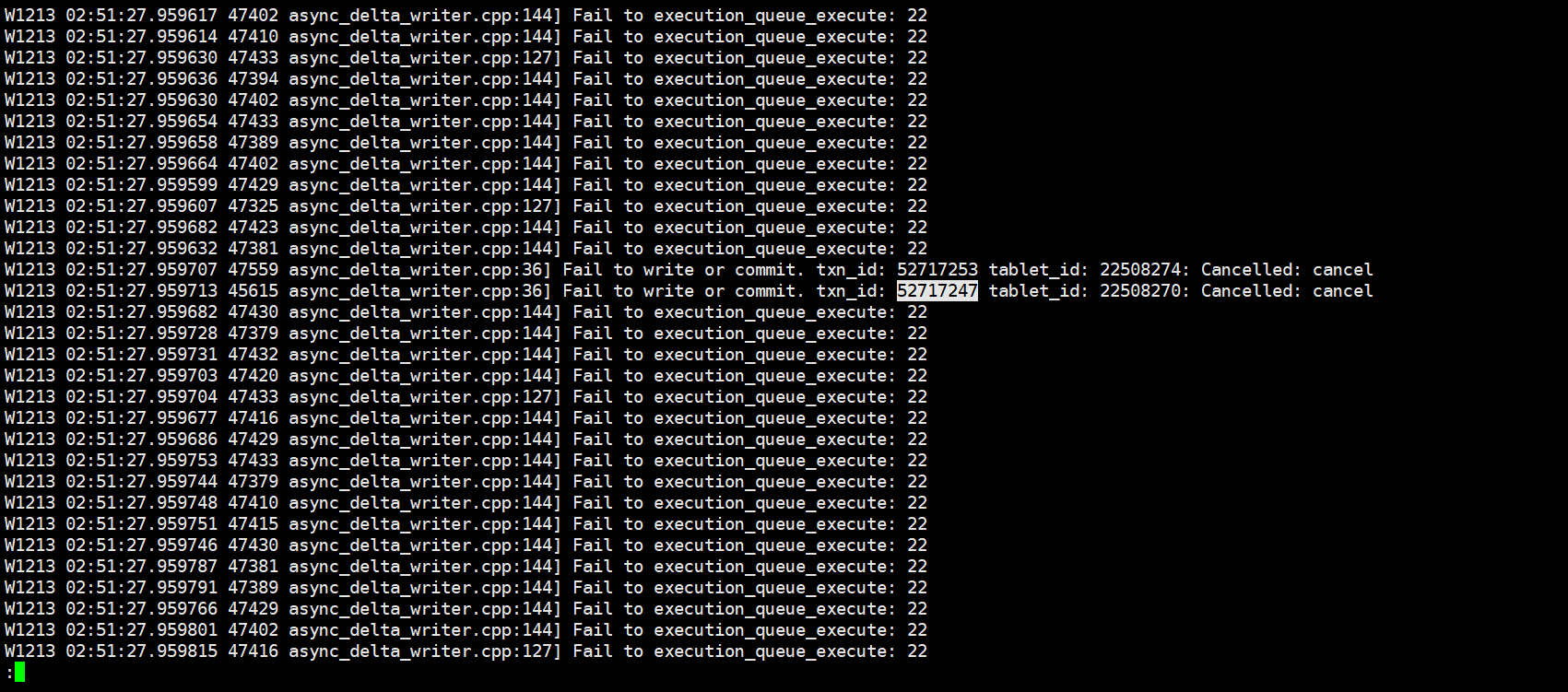
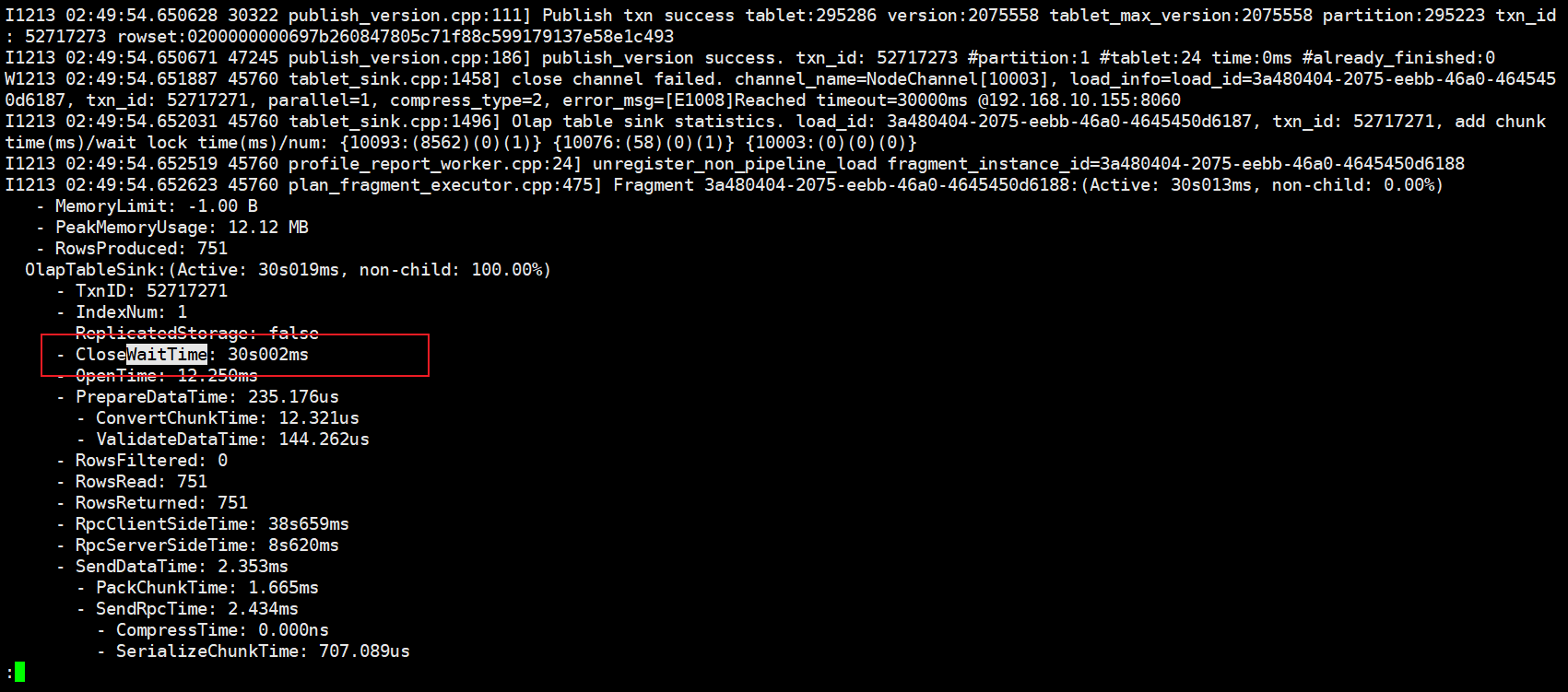
{“Status”:“Fail”,“BeginTxnTimeMs”:3,“Message”:"[E1008]Reached timeout=30000ms @192.168.10.155:8060",“NumberUnselectedRows”:0,“CommitAndPublishTimeMs”:0,"
Label":“6839f447-cf60-4cc4-8951-0991b2cc29bc”,“LoadBytes”:2187451,“StreamLoadPlanTimeMs”:13,“NumberTotalRows”:0,“WriteDataTimeMs”:48885,“TxnId”:52717247,
“LoadTimeMs”:48902,“ReadDataTimeMs”:7,“NumberLoadedRows”:0,“NumberFilteredRows”:0}
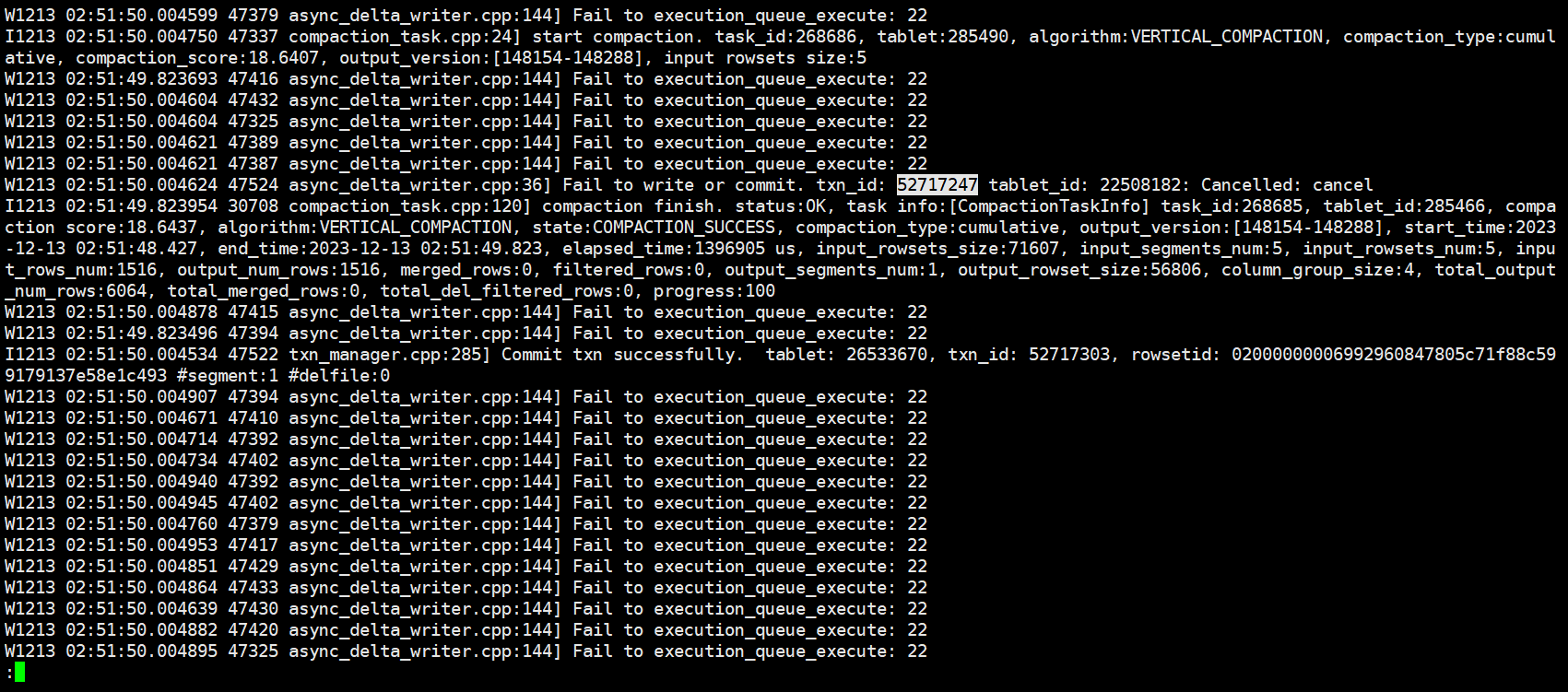
想知道如何定位该问题?目前看完了所有类似问题无效,集群状态正常,另外则个timeout参数是哪个官网找了并没有,求解答