为了更快的定位您的问题,请提供以下信息,谢谢
【详述】查询一个大sql,前几次查询都可以。突然再次查询报错
【背景】查询sql:
select
tt.day,
tt.oper_name as app_id,
t1.
type as app_type,t2.id as user_id,
t2.name as user_name,
t2.company_id as company_id,
t3.name as company_name,
tt.title as api_title,
tt.oper_url as api_url,
tt.status as api_status,
count(distinct tt.oper_param) as cnt
from
(select
tt1.day,
tt1.oper_name,
tt1.oper_param,
tt2.title,
tt2.oper_url,
tt2.status
from (select distinct day,oper_name,trace_id,oper_param from hive_catalog_glue.prod_ods.cdw_user_oper_log_day where operator_type = 3 and oper_name!=’’ and day>=‘2023-11-01’ and day<‘2023-12-01’ ) tt1
inner join (select day,trace_id,title,oper_url,status from hive_catalog_glue.prod_ods.cdw_user_oper_log_day where operator_type = 4 and day>=‘2023-11-01’ and day<‘2023-12-01’) tt2 on tt1.trace_id = tt2.trace_id and tt1.day = tt2.day
)
tt
left join jdbc_rds.
cdw-cloud.c_user_app t1 on tt.oper_name=t1.app_idleft join jdbc_rds.
cdw-cloud.c_user t2 on t1.c_user_id=t2.idleft join jdbc_rds.
cdw-cloud.c_user_company t3 on t2.company_id=t3.idgroup by
tt.day,
tt.oper_name ,
t1.
type,t2.id,
t2.name,
t2.company_id,
t3.name,
tt.title,
tt.oper_url,
tt.status
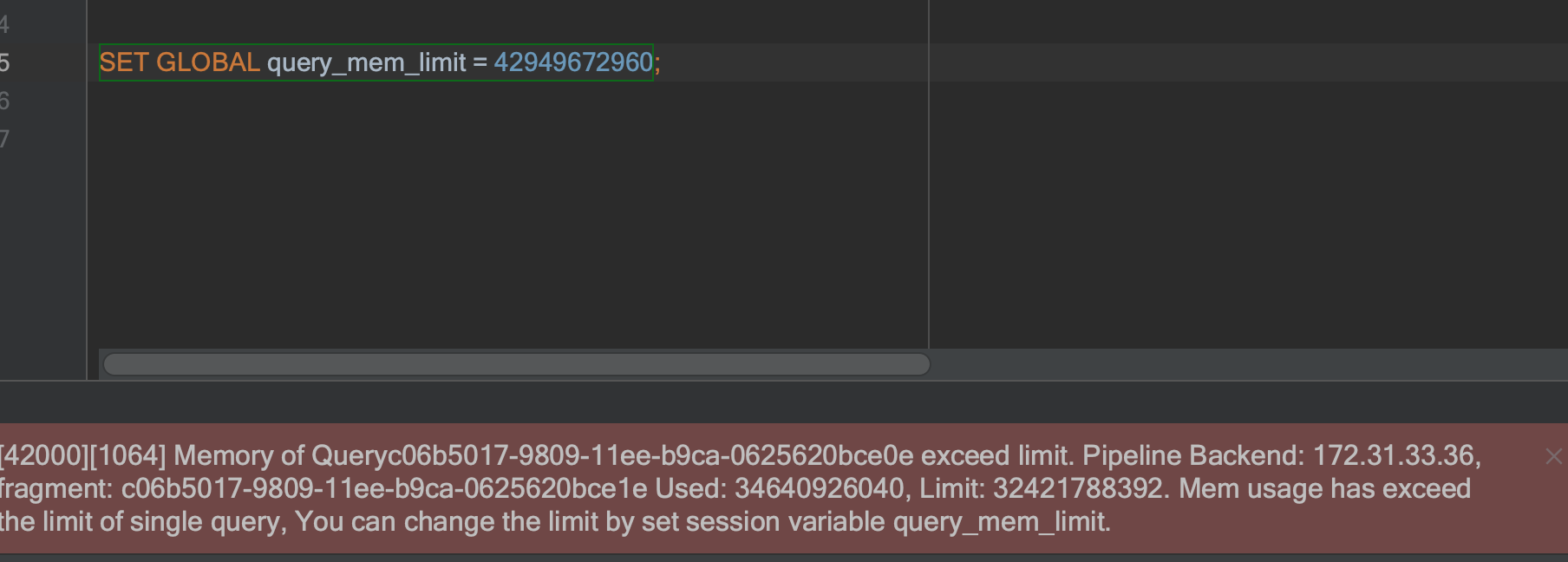
【业务影响】小查询可用 大查询不可用
【是否存算分离】数据湖查询
【StarRocks版本】3.1.2
【集群规模】1fe 3be
【机器信息】16core 64G
【联系方式】543503137@qq.com
【附件】
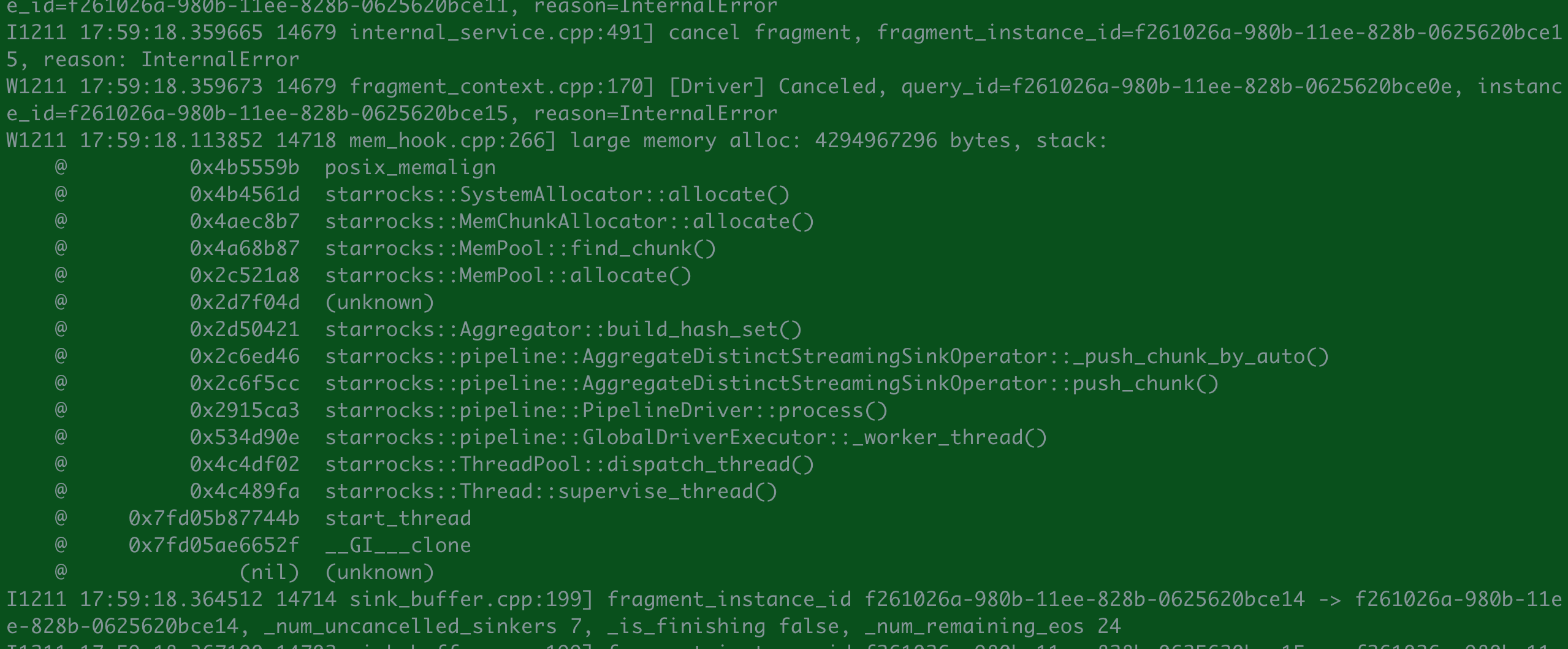
- fe.log/beINFO/相应截图
- 查询报错: