【详述】问题详细描述
近期发现,fe节点的内存每天都在不断增长(leader节点差不多1G/日的速度),无论是fe leader还是follower都在不断增长
【背景】做过哪些操作?
最近新上了几个kafka的routine load task任务
【业务影响】
目前fe内存有限,如果涨到配置的阈值就要手动重启fe,影响线上的任务查询;
【是否存算分离】
否
【StarRocks版本】
2.3.16
【集群规模】
3fe + 4be,分开部署
【机器信息】
fe:8c/16g,be:16c/64g
【联系方式】
社区群15-老张
【附件】
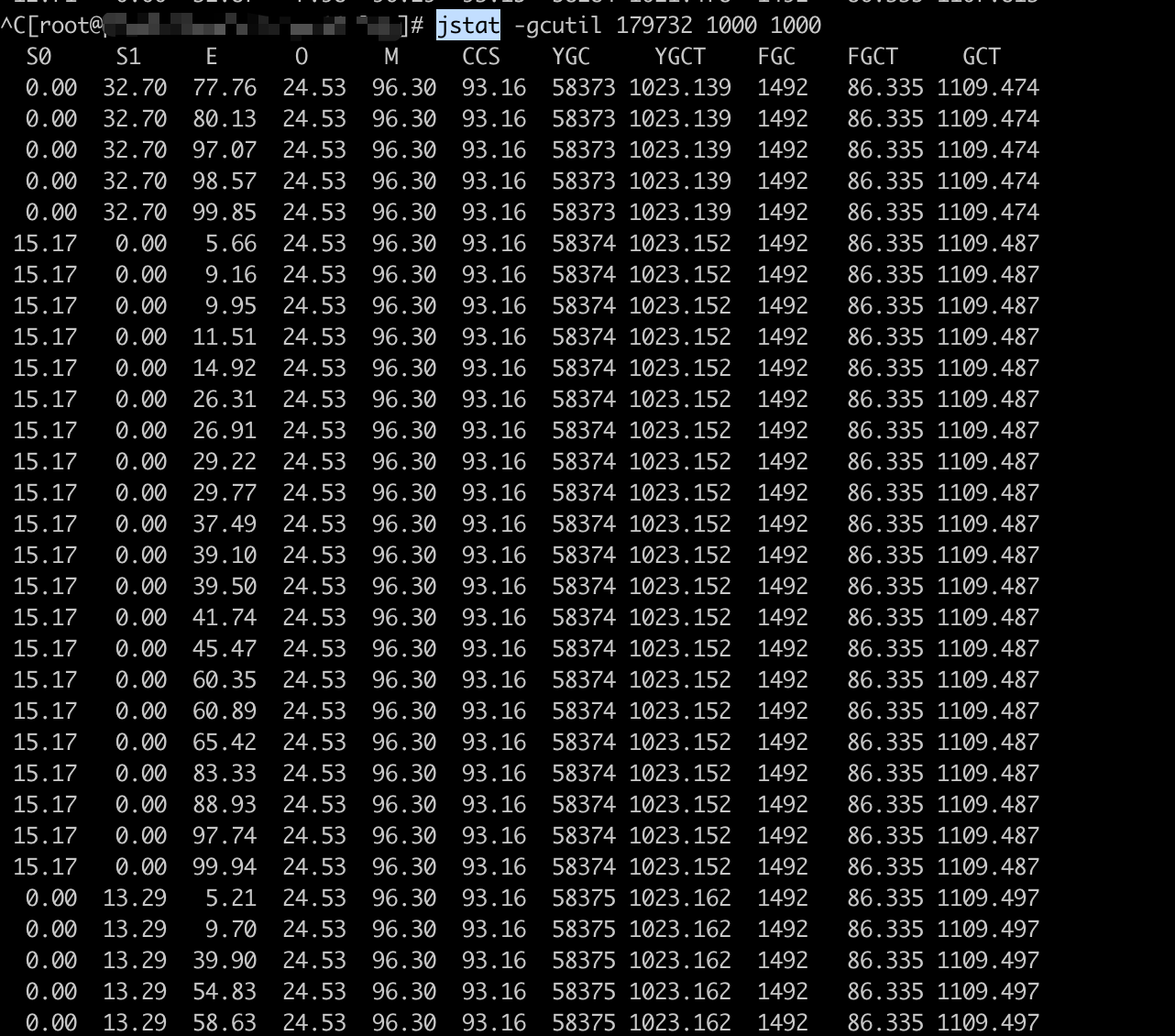
- fe pid jstat:
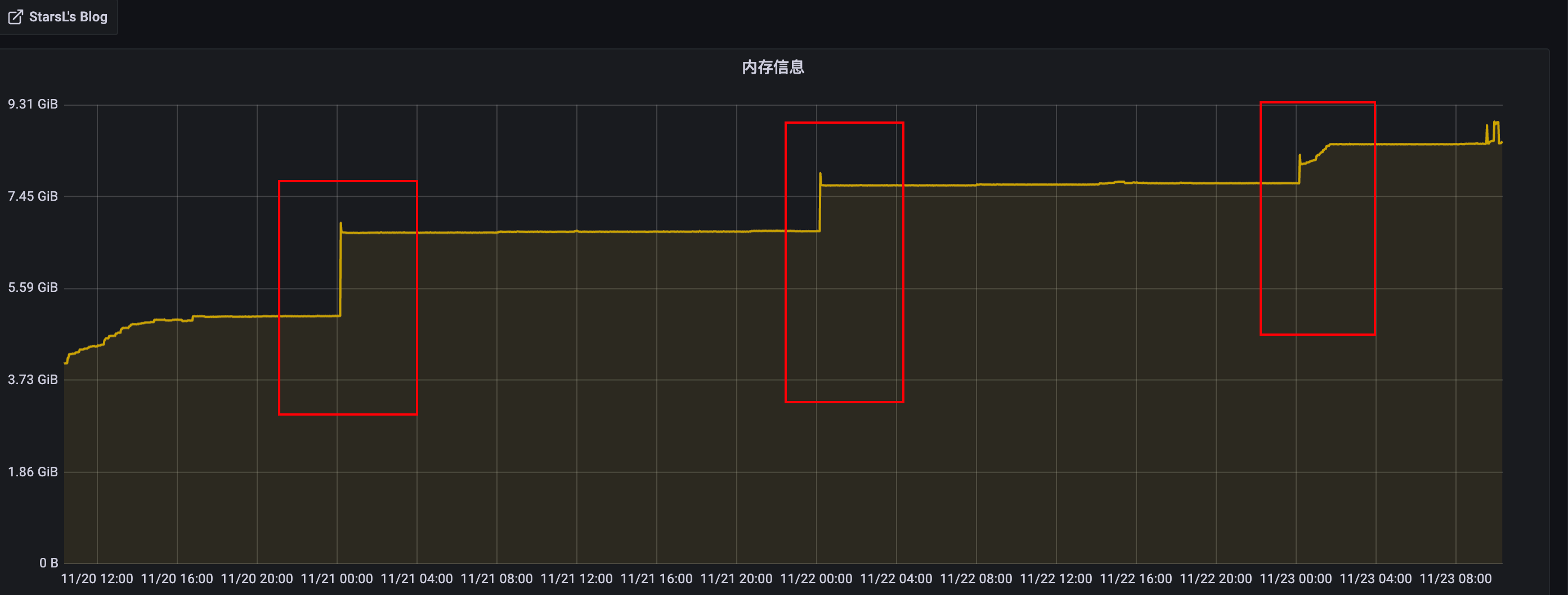
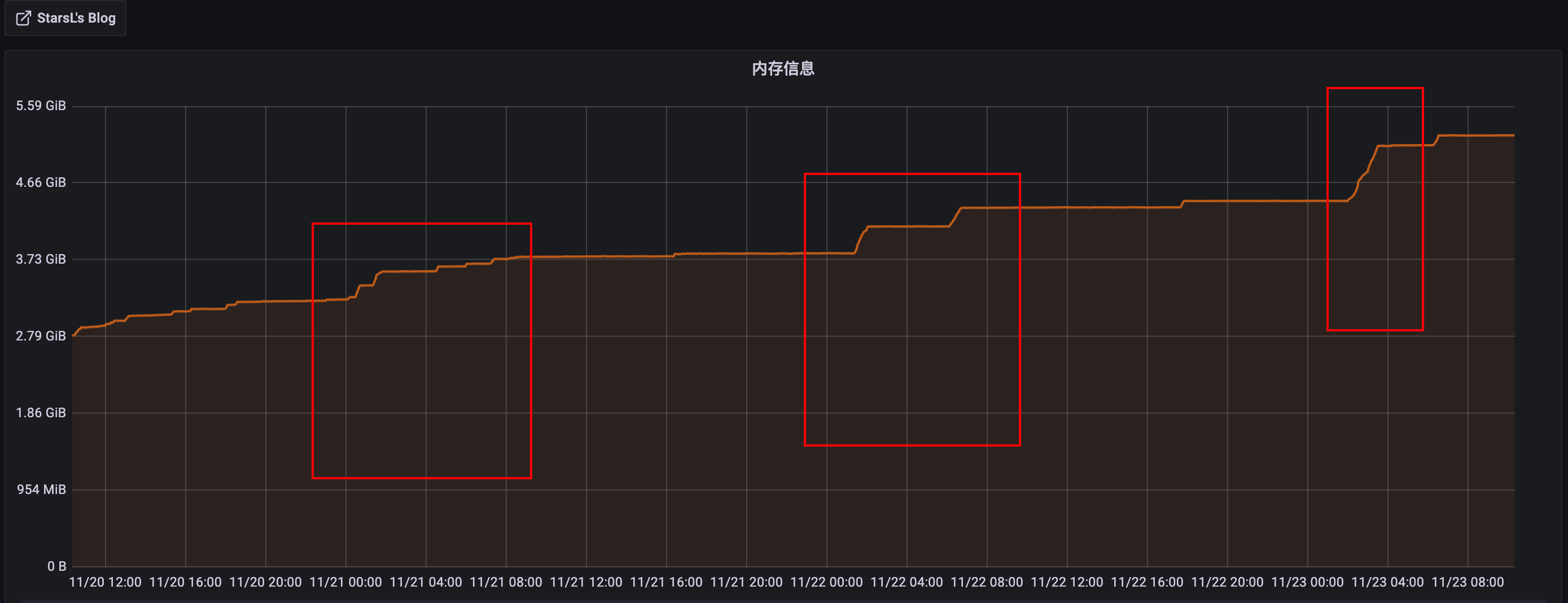
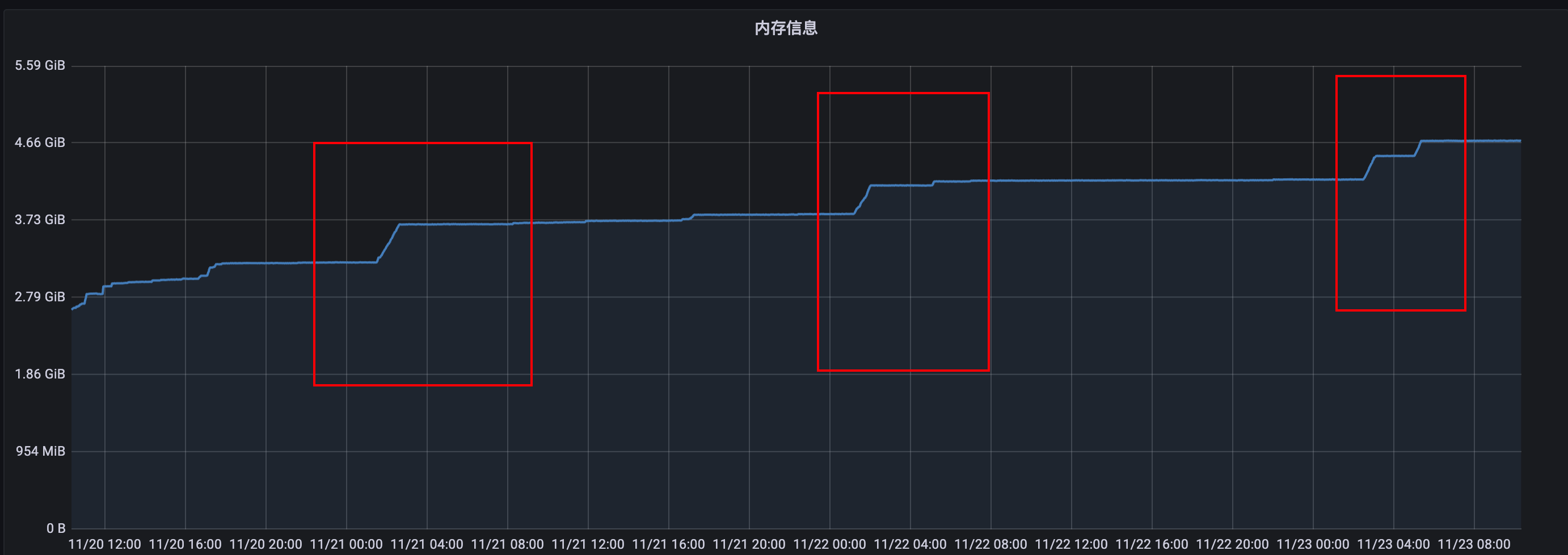
- grafana内存增长截图:
leader节点:
follower节点:
几个节点呈断崖式趋势增长