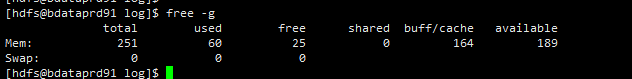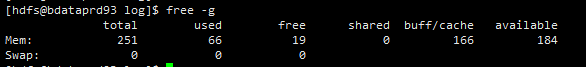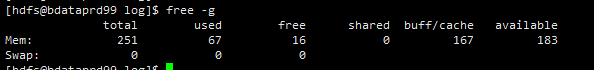为了更快的定位您的问题,请提供以下信息,谢谢
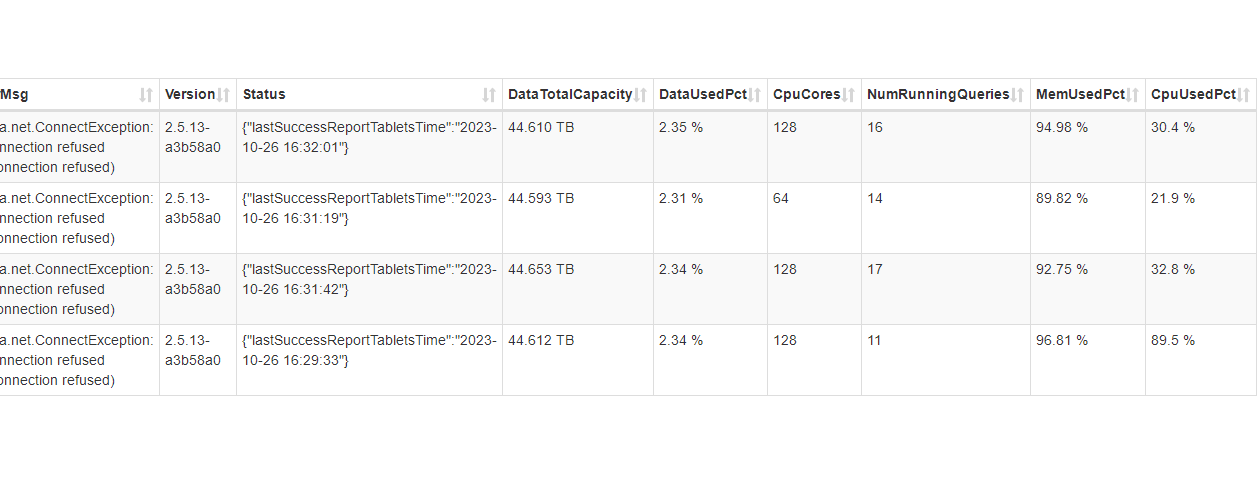
【详述】今天查询导致集群be节点全部OMM了,不知道怎么回事,麻烦技术老师们定位一下
【背景】做过哪些操作?查询
【业务影响】集群be全挂,影响BI查询
【StarRocks版本】2.5.13
【集群规模】3fe(1 master+2follower)+4be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:128C/256G/万兆
【联系方式】社区群13-麦咪,谢谢
【附件】
be (2).out (3.4 KB) be (3).out (35.8 KB) be (4).out (609 字节) be.out (4.5 KB)