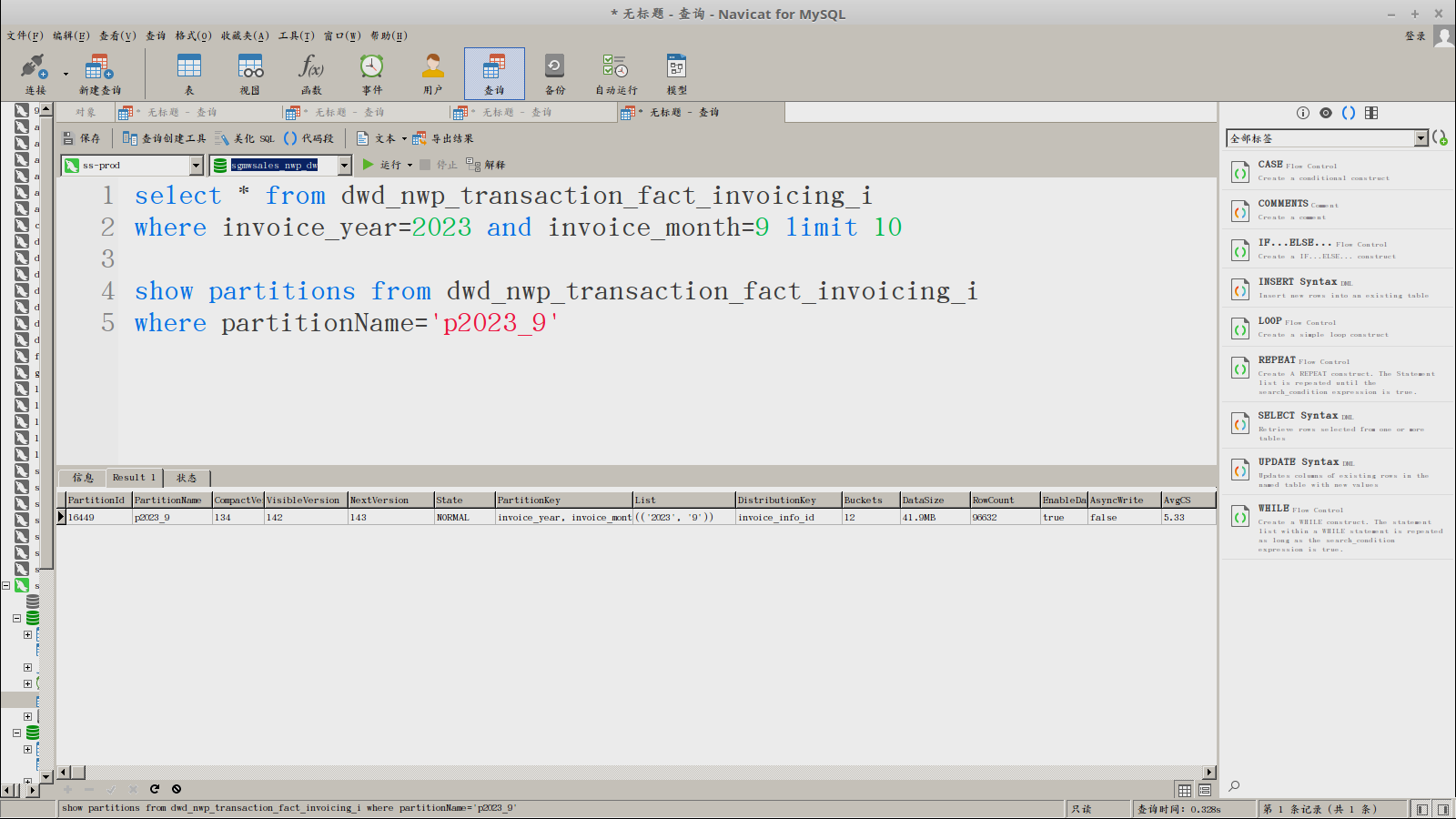
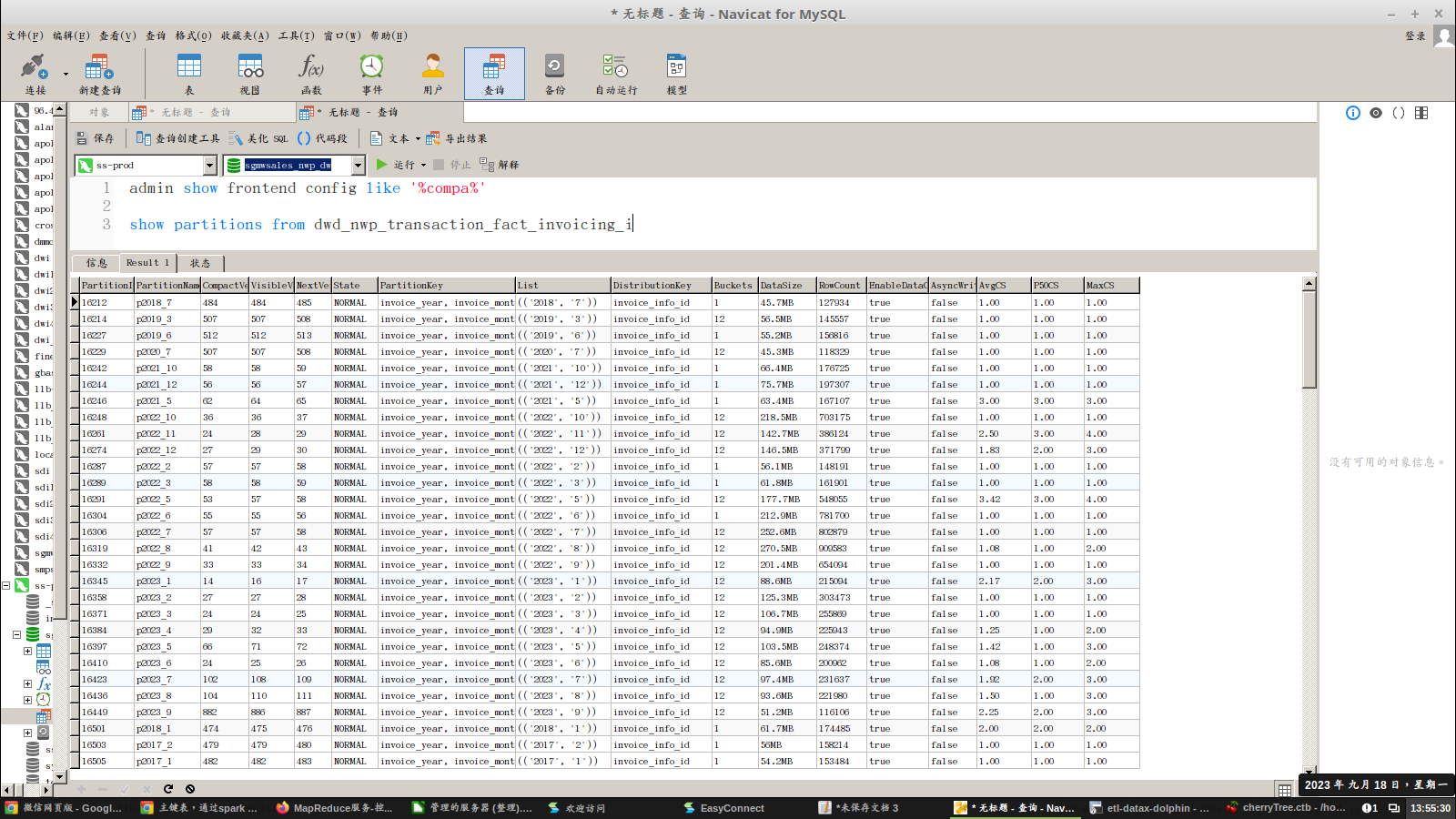
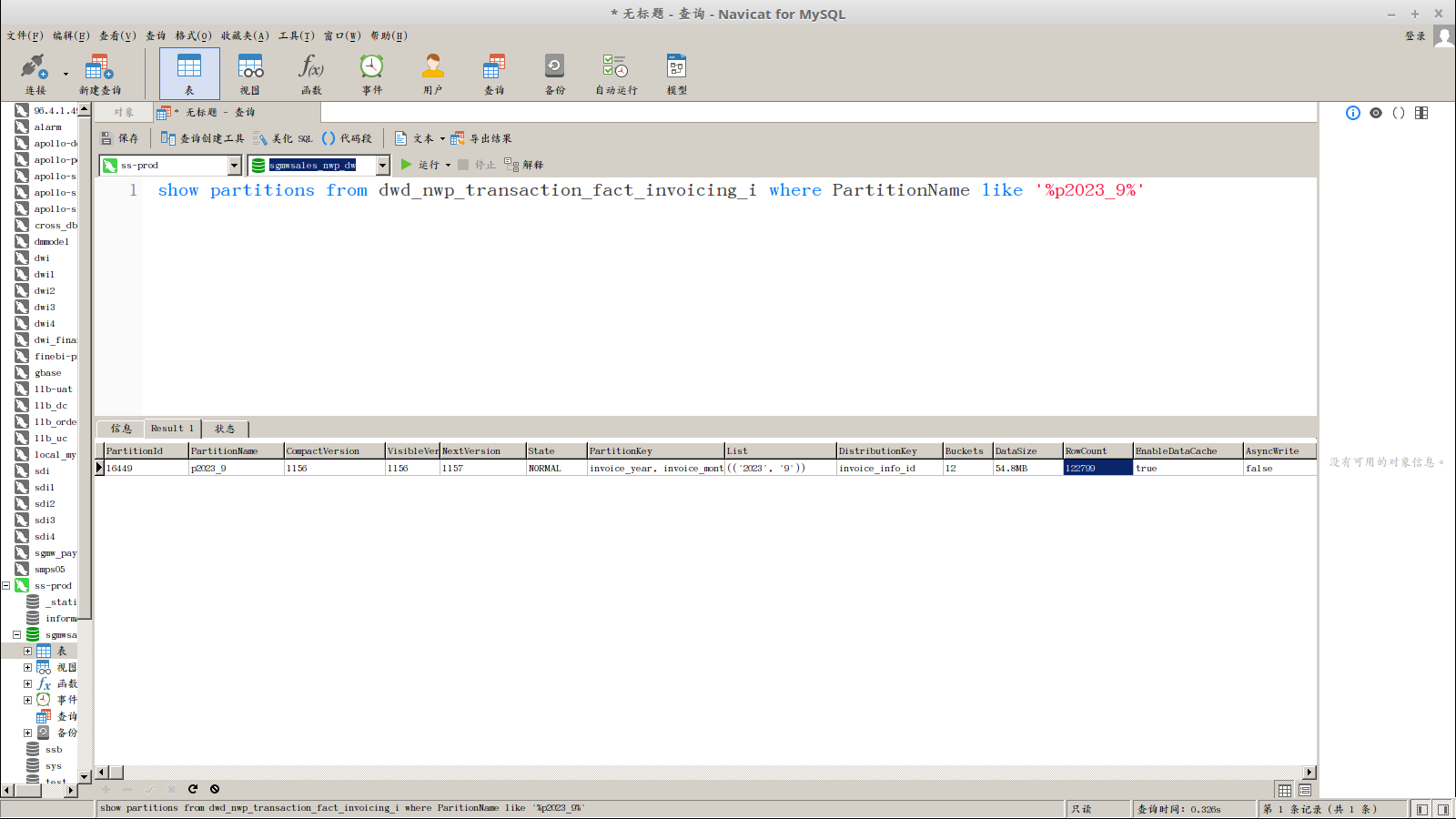
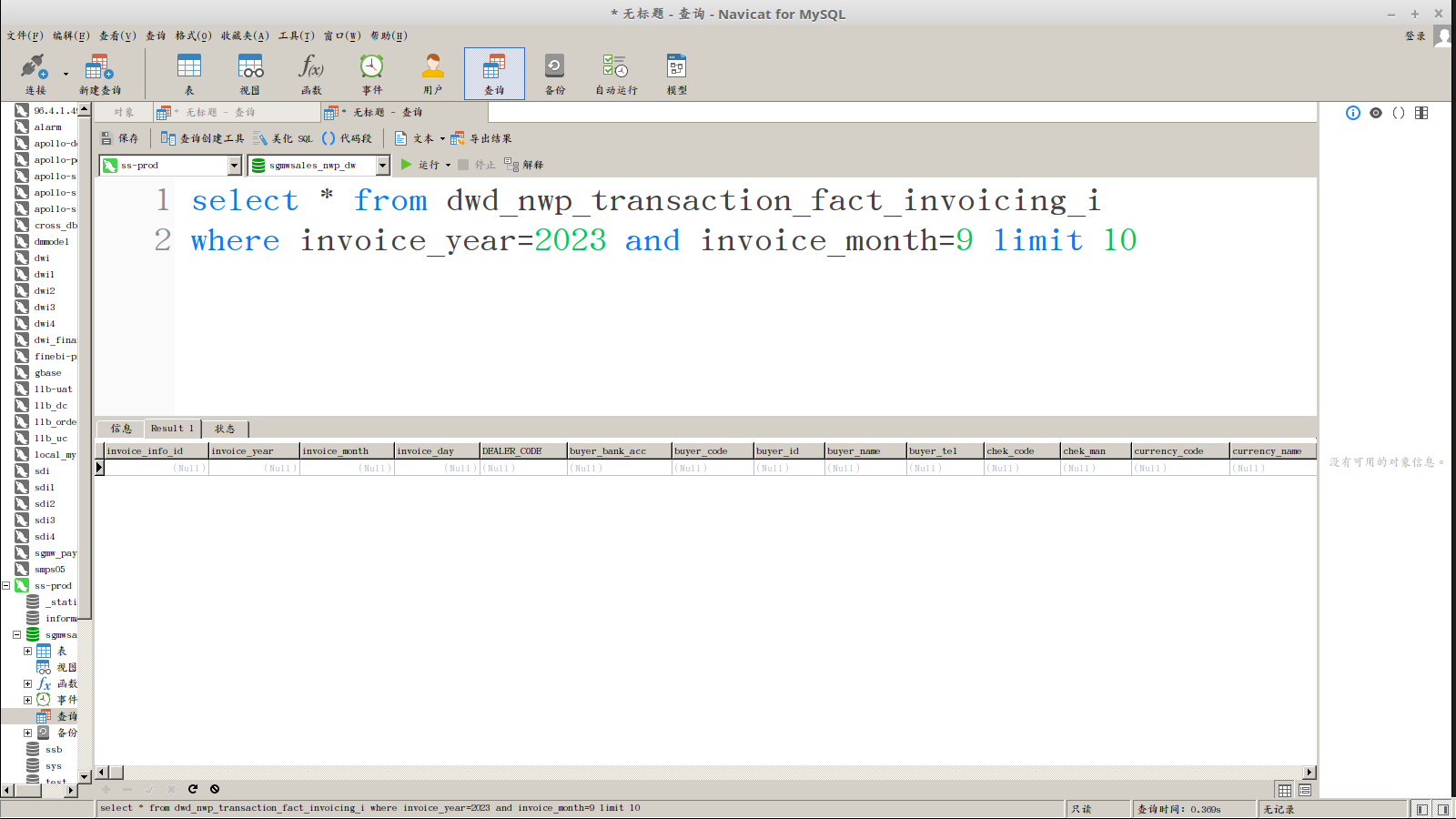
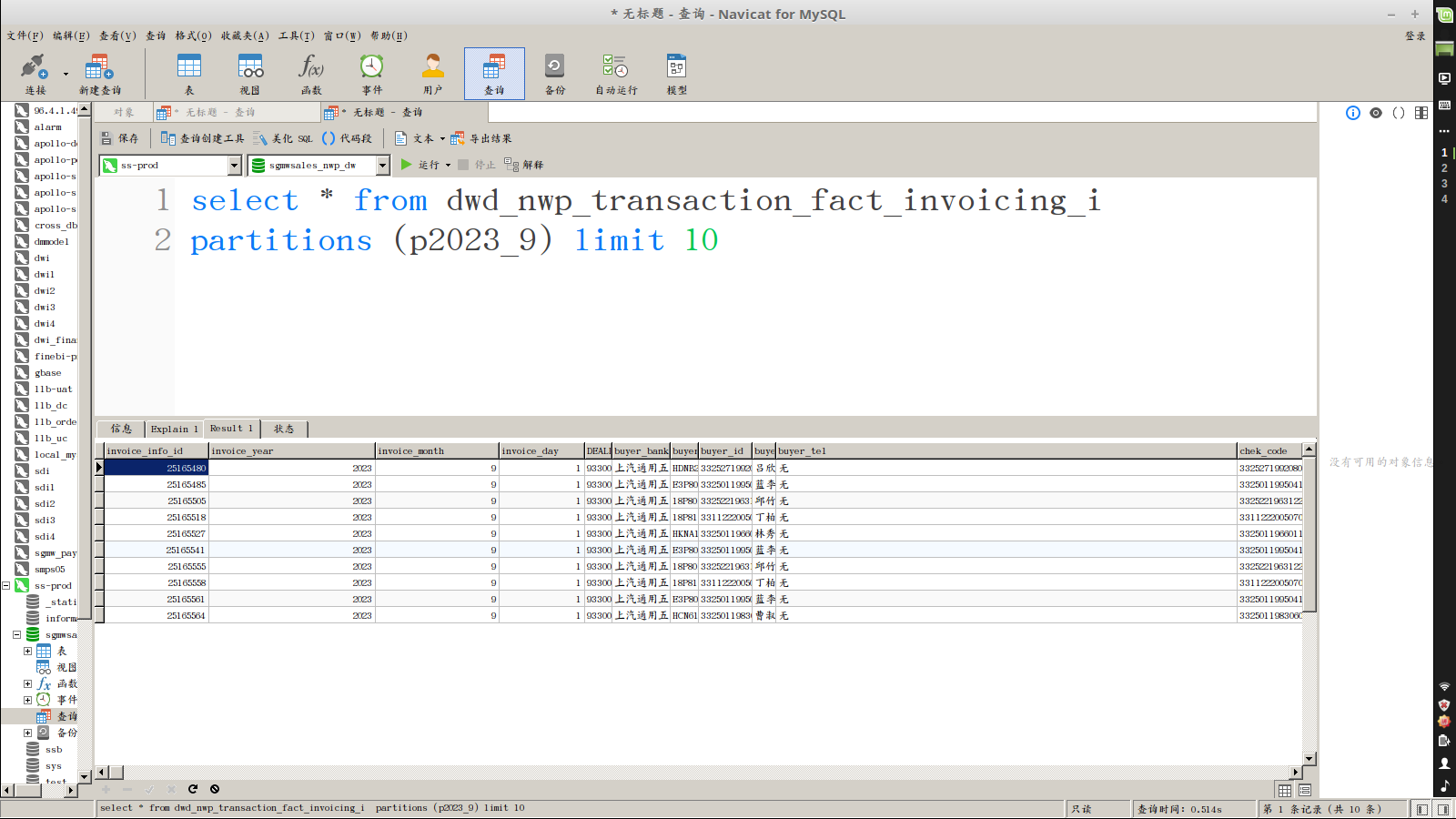
【背景】一张主键表,通过spark connector导入历史数据,通过分区键查询不出数据,但是通过其他时间字段却能查出数据
【业务影响】无
【StarRocks版本】3.1.2,存算分离模式
【集群规模】1fe+6be(独立部署)
【机器信息】256G/128C 万兆网卡
【表模型】主键模型
【导入方式】spark connector
【联系方式】timedifier@126.com
建表语句:
CREATE TABLE dwd_nwp_transaction_fact_invoicing_i (
invoice_info_id bigint(20) NOT NULL COMMENT “”,
invoice_year int(11) NOT NULL COMMENT “开票年”,
invoice_month int(11) NOT NULL COMMENT “开票月”,
invoice_day int(11) NOT NULL COMMENT “开票天”,
invoice_date datetime NOT NULL COMMENT “开票时间”,
…
) ENGINE=OLAP
PRIMARY KEY(invoice_info_id, invoice_year, invoice_month)
PARTITION BY (invoice_year,invoice_month)
DISTRIBUTED BY HASH(invoice_info_id)
PROPERTIES (
“replication_num” = “1”,
“datacache.partition_duration” = “1 months”,
“datacache.enable” = “true”,
“storage_volume” = “builtin_storage_volume”,
“enable_async_write_back” = “false”,
“enable_persistent_index” = “false”,
“compression” = “LZ4”
);
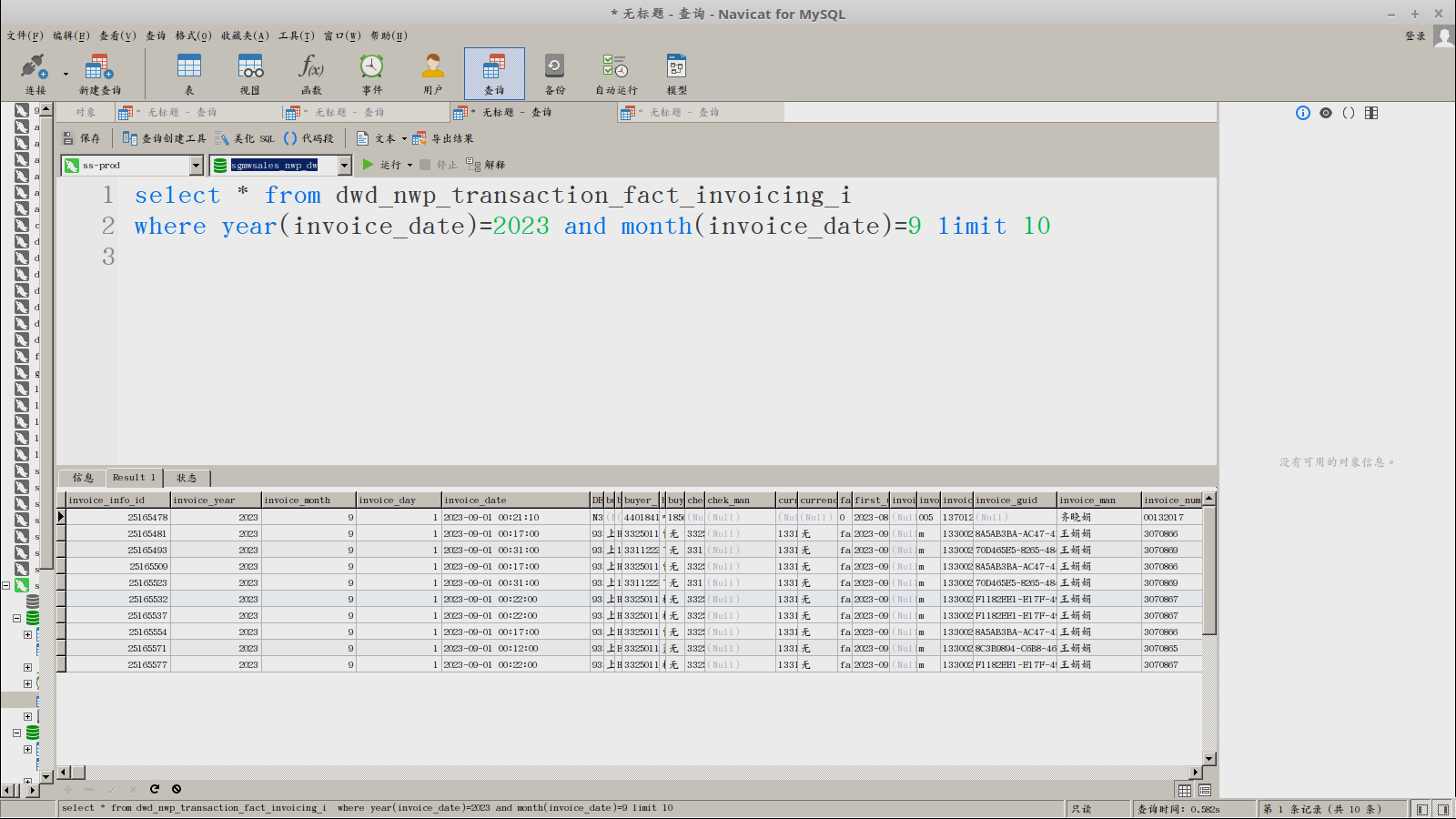
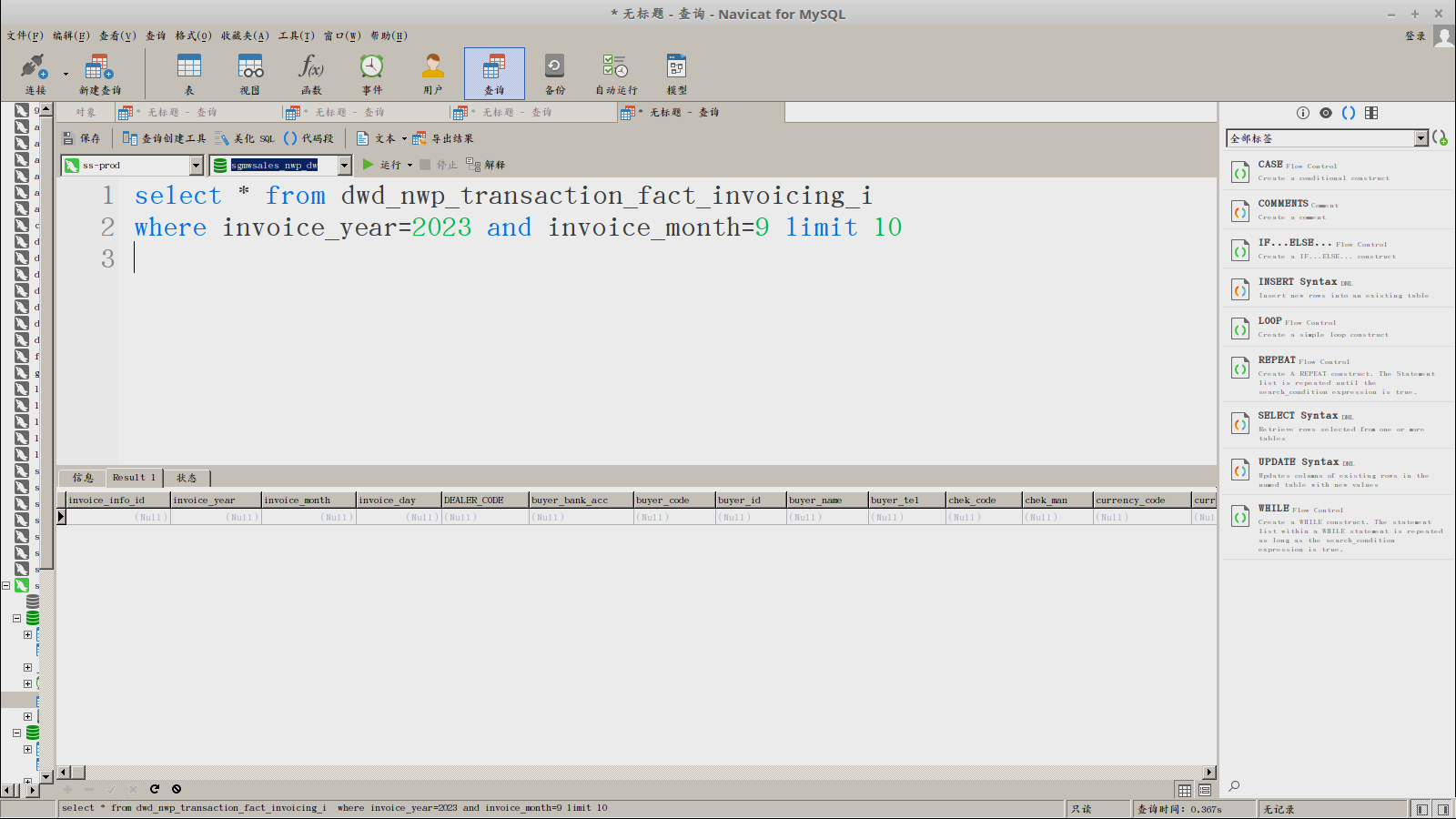
查不出数据:
select * from dwd_nwp_transaction_fact_invoicing_i
where invoice_year=2023.0 and invoice_month=9.0 limit 10
能查出数据:
select * from dwd_nwp_transaction_fact_invoicing_i
where year(invoice_date)=2023 and month(invoice_date)=9 limit 10