
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】一张300亿行的数据表,数据量650G,一张17亿行的数据,数据量150G,涉及两张表的视图嵌套join,希望能够完整执行完成
【背景】
【业务影响】执行相关查询报错mem limit
【StarRocks版本】例如:1.18.2
【集群规模】例如:1fe(1 follower+2observer)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:128C/100G/万兆
【联系方式】
【附件】
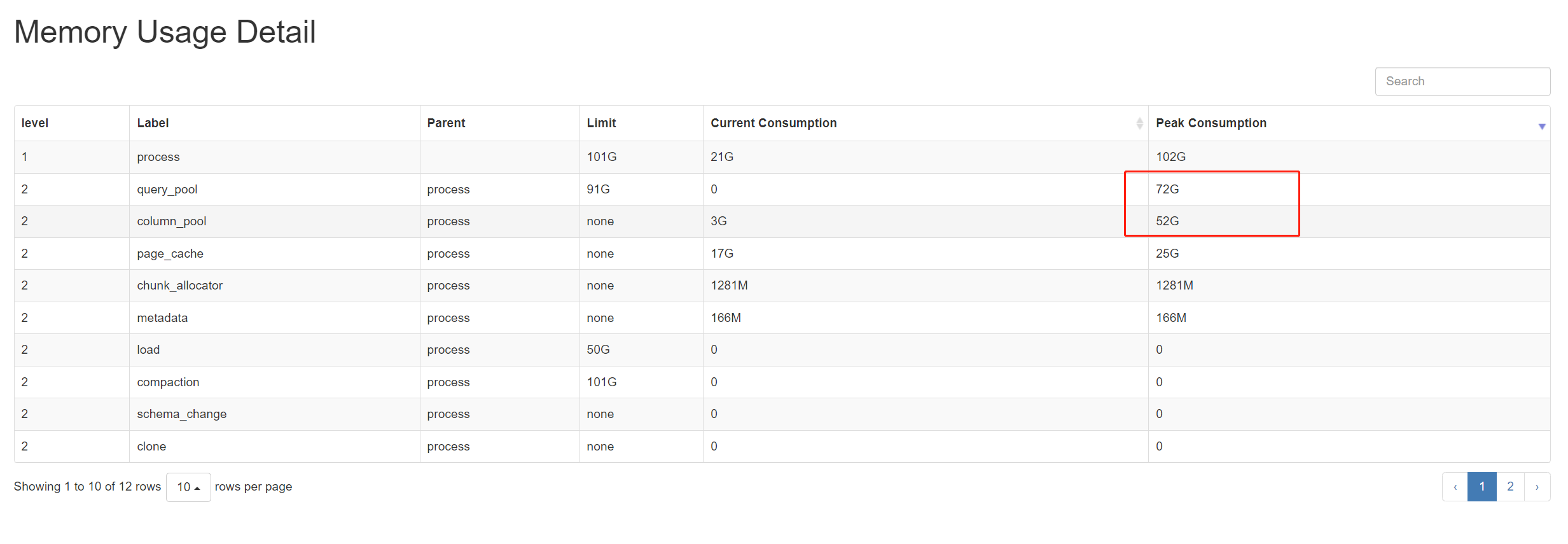
只有三个be?恐怕很难
1.18.2 无法使用 spill down 
1.18.2是帖子模版里面的版本
不好意思, 老了,眼花 
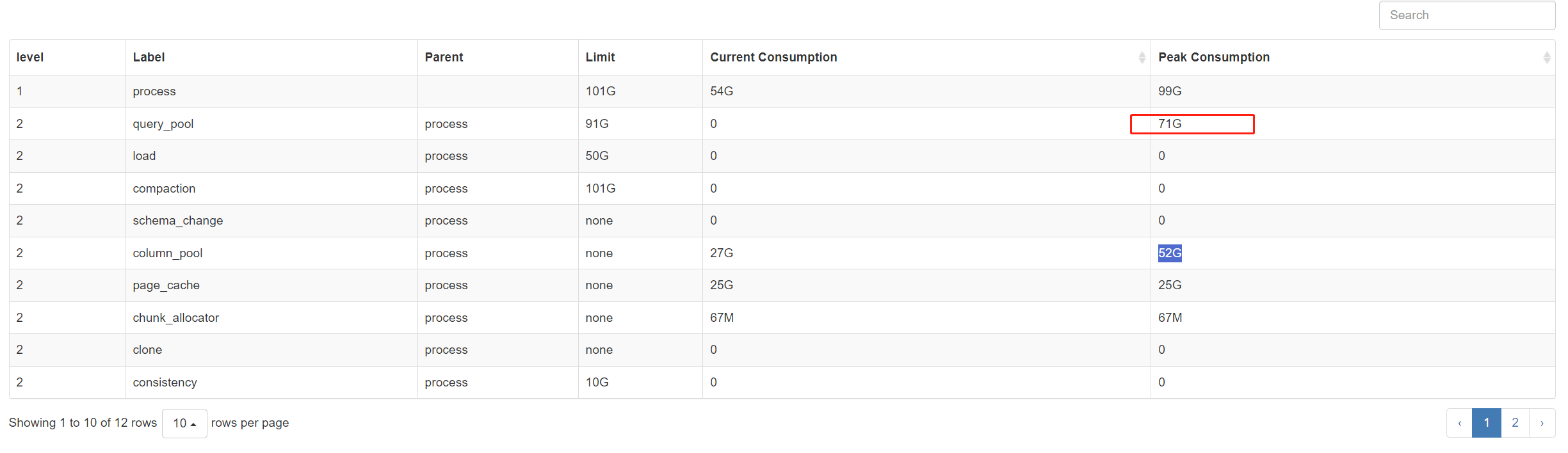
count其中某个列呢,可以执行出来吗
还想问下大家,我设置了block_cache_disk_size = 536870912000
block_cache_disk_path 缓存磁盘路径 ,但是看起来并没有生效,没有创建文件
存算分离还是存算一体呢,explain costs + sql 看下
另外把视图的创建语句贴下
@jingdan 我也遇到类似问题,也开了spill,有缓解,但是有些场景也是会报错。不知是否和并行的调度有关?一次性起了太多并行线程消耗太多内存? 要限制并行的话是需要调哪个参数呢? fragment_pool_thread_num_max 这个参数是针对整个集群的还是单次查询的呢? 还是应该调整这个pipeline_dop?