
【详述】StarRocks有3个fe节点和3个be节点,其中1个be节点的磁盘接近用满,另外2个be节点的磁盘则剩余很多,状态正常,3个fe节点状态也正常。
【背景】前一晚逐个给be做过服务器规格变更(升内存,降CPU)。
操作顺序是:stop be --> 变更be服务器规格 --> start be,待变更规格后的be正常接入到集群后,依次再变更其他be节点的服务器规格。
【业务影响】由于其中1个be的磁盘满了,导致数据同步中断,导不进数据到StarRocks。
【StarRocks版本】v3.0.4
【集群规模】3 fe(1 leader + 2 follower)+ 3 be
【机器信息】3个be均是: 4vCPU+32G内存
【附件】
– be.Warning日志截图:
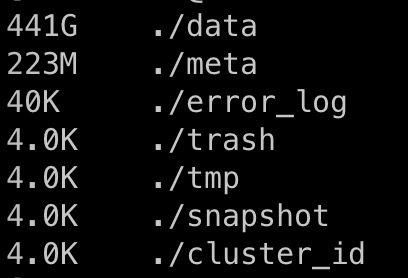
– 用满磁盘的be的磁盘使用情况:
– 另外两个未用满磁盘的be磁盘使用情况:
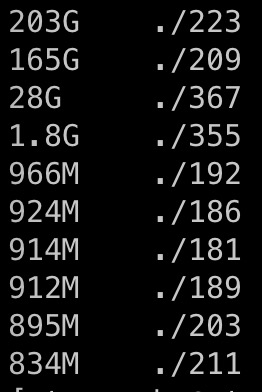
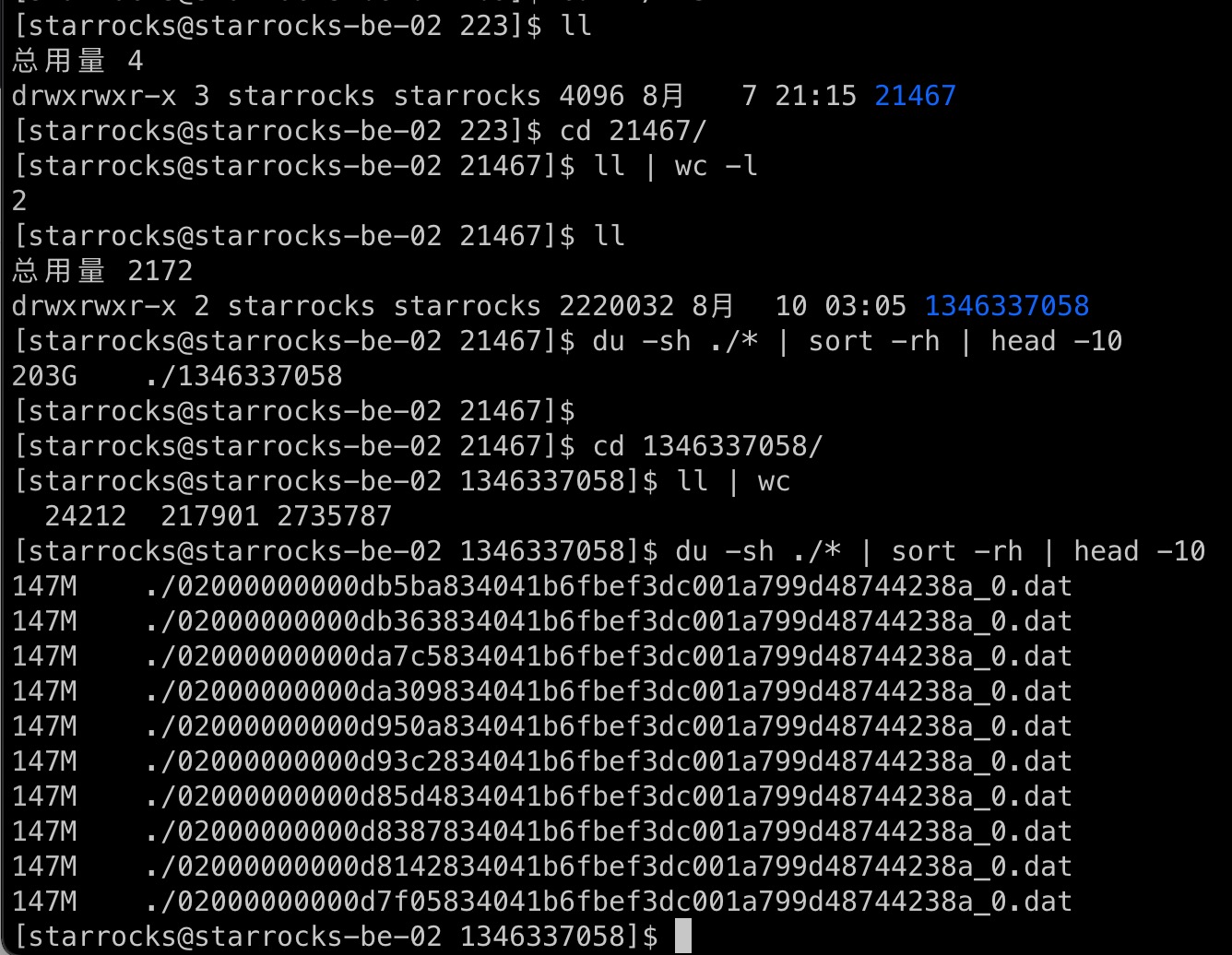
– 用满磁盘的be的 storage 目录里面的分布占用大小:
– 补充下表结构的配置信息:
ENGINE=OLAP
PRIMARY KEY(sid, created_at, id)
PARTITION BY date_trunc(‘month’, created_at)
DISTRIBUTED BY HASH(sid)
PROPERTIES (
“replication_num” = “3”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”,
“enable_persistent_index” = “true”,
“replicated_storage” = “true”,
“compression” = “LZ4”
);
 只是有时候比例不大
只是有时候比例不大