为了更快的定位您的问题,请提供以下信息,谢谢
【版本】3.0.2
【集群配置】3FE + 8BE(32C 128G NVMe SSD 3.5T *2)
【详述】
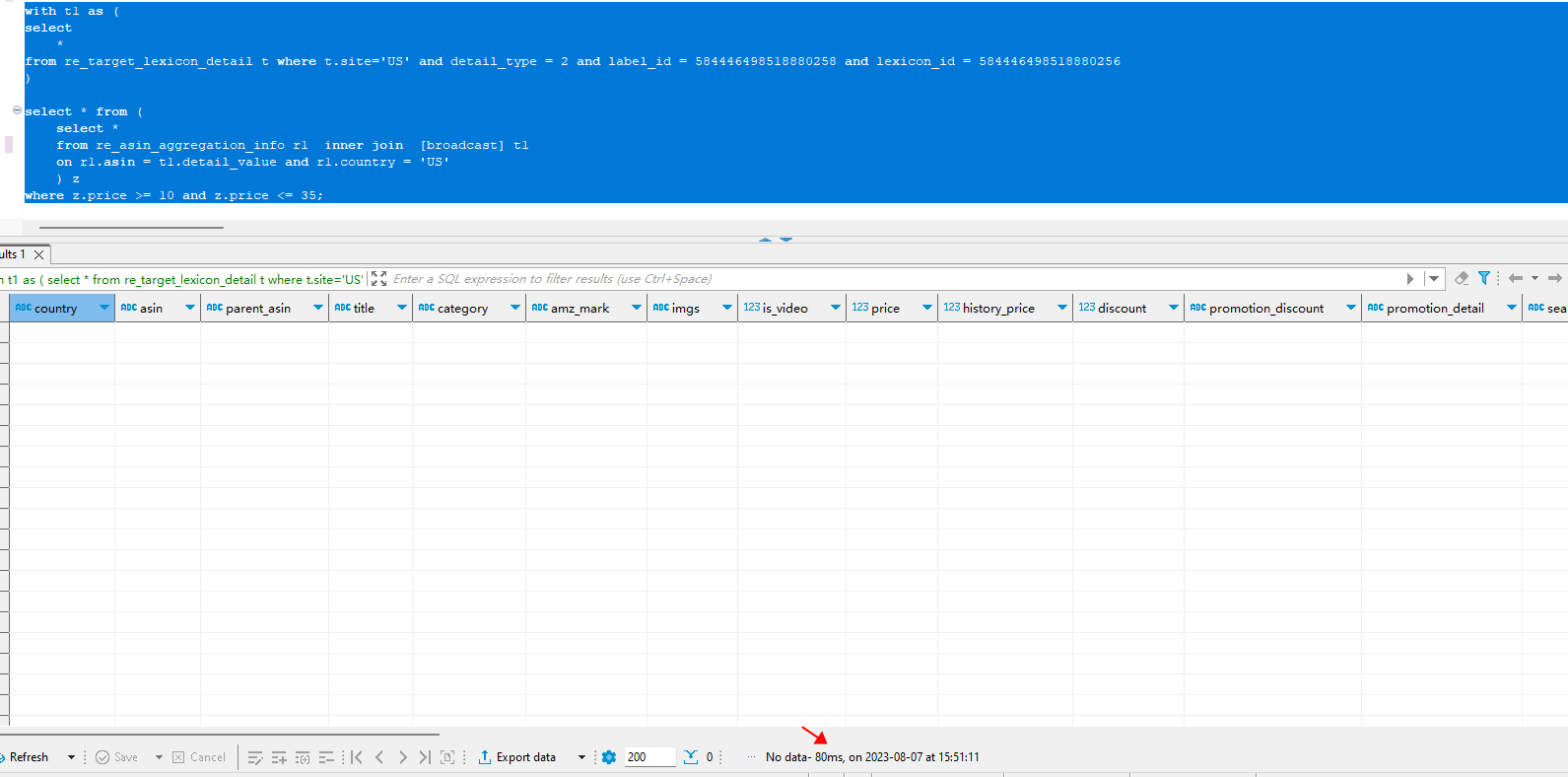
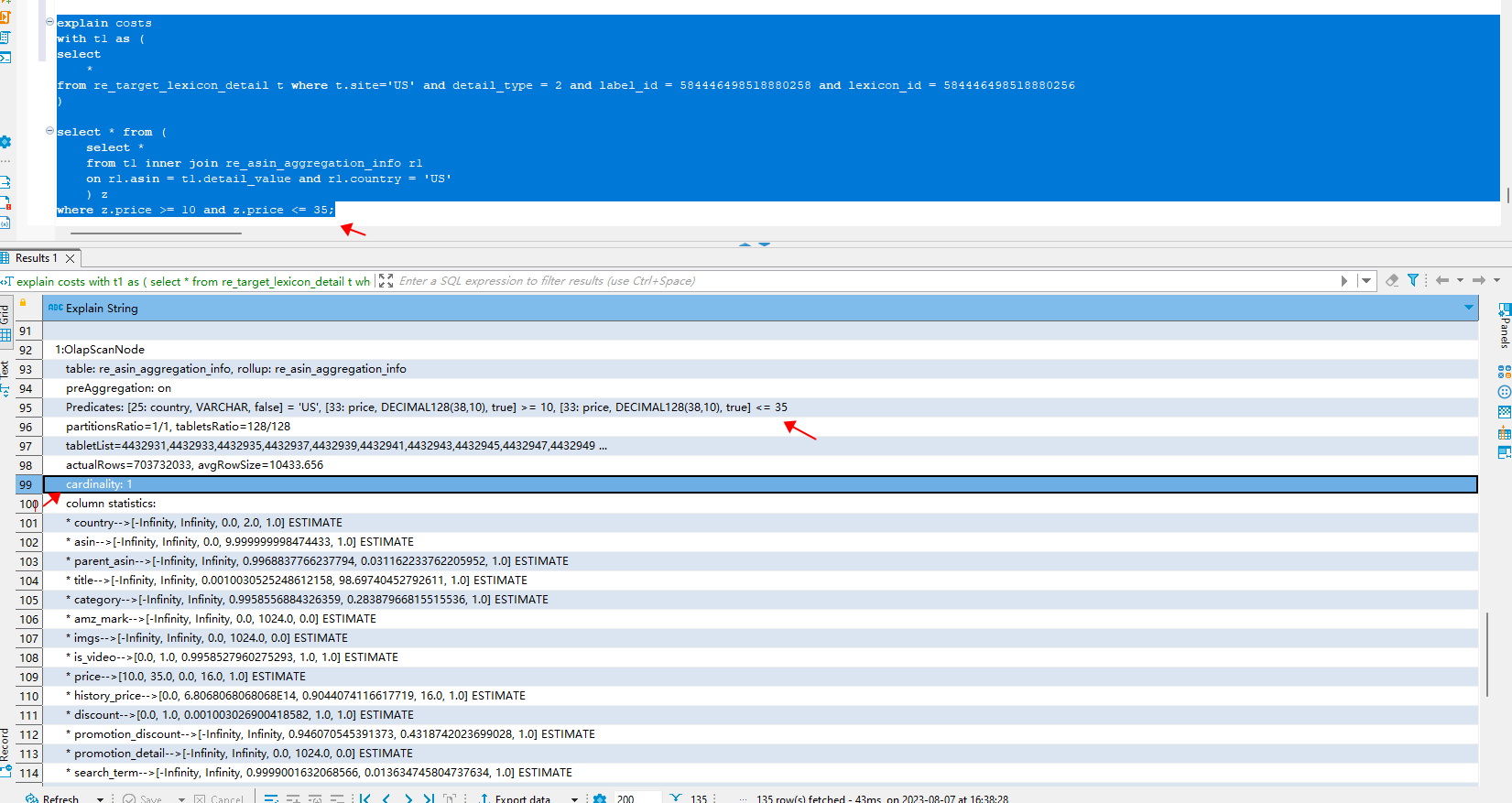
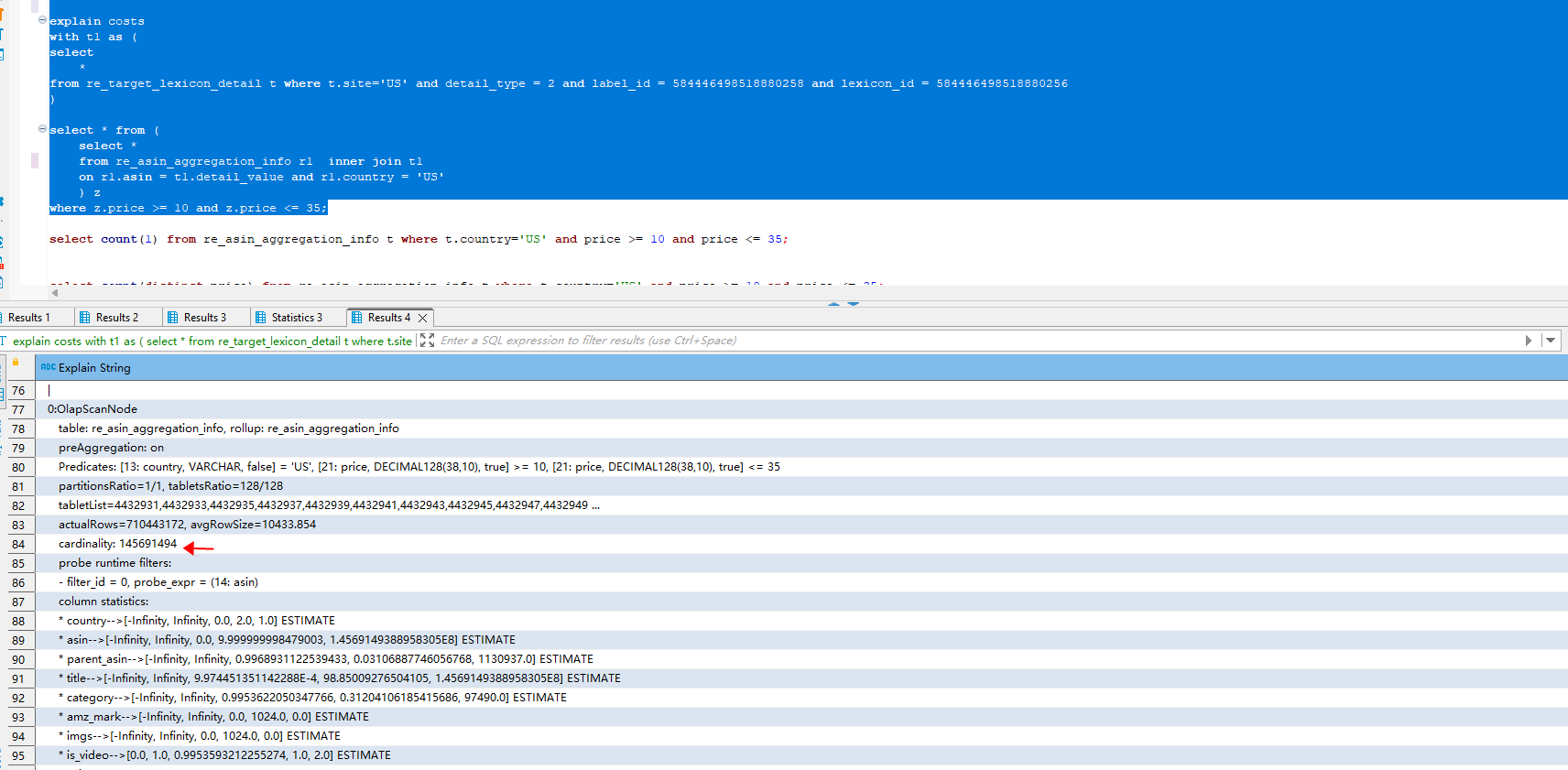
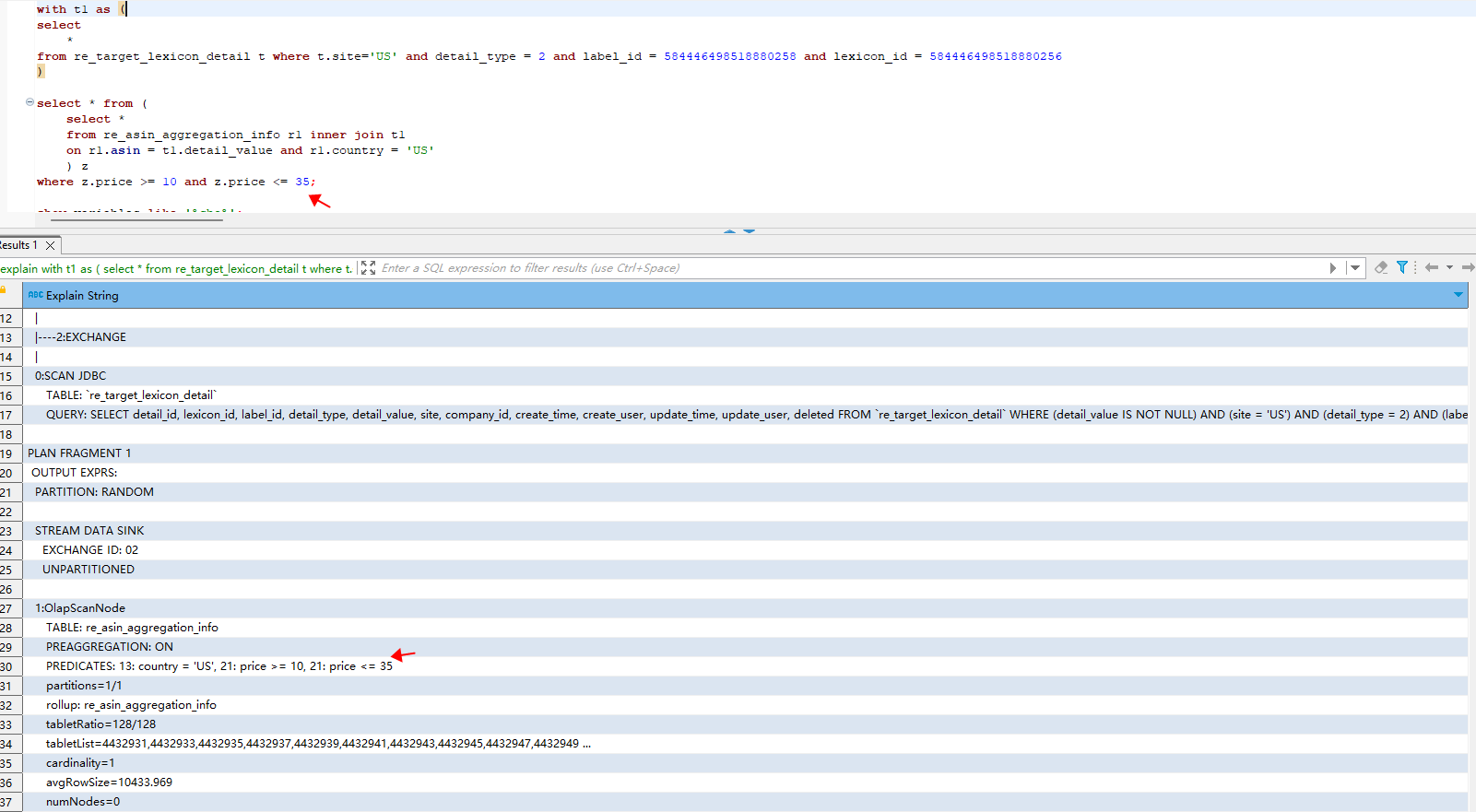
一个sql查询不加过滤条件,查询结果毫秒级别出来,没有数据,在这个sql的基础上加上一个大表的过滤条件后,查询时间显著变长,结果同样是没数据,查看explain 发现过滤条件被谓词下推了,导致查询性能退化,是否有参数能将谓词下推给禁止掉,不要先下推过滤后再join, 而是先join 后再过滤条件
– 不带过滤条件,146ms 就能查出数据
with t1 as (
select
*
from re_target_lexicon_detail t where t.site=‘US’ and detail_type = 2 and label_id = 584446498518880258 and lexicon_id = 584446498518880256
)
select *
from re_asin_aggregation_info r1 inner join t1
on r1.asin = t1.detail_value and r1.country = ‘US’
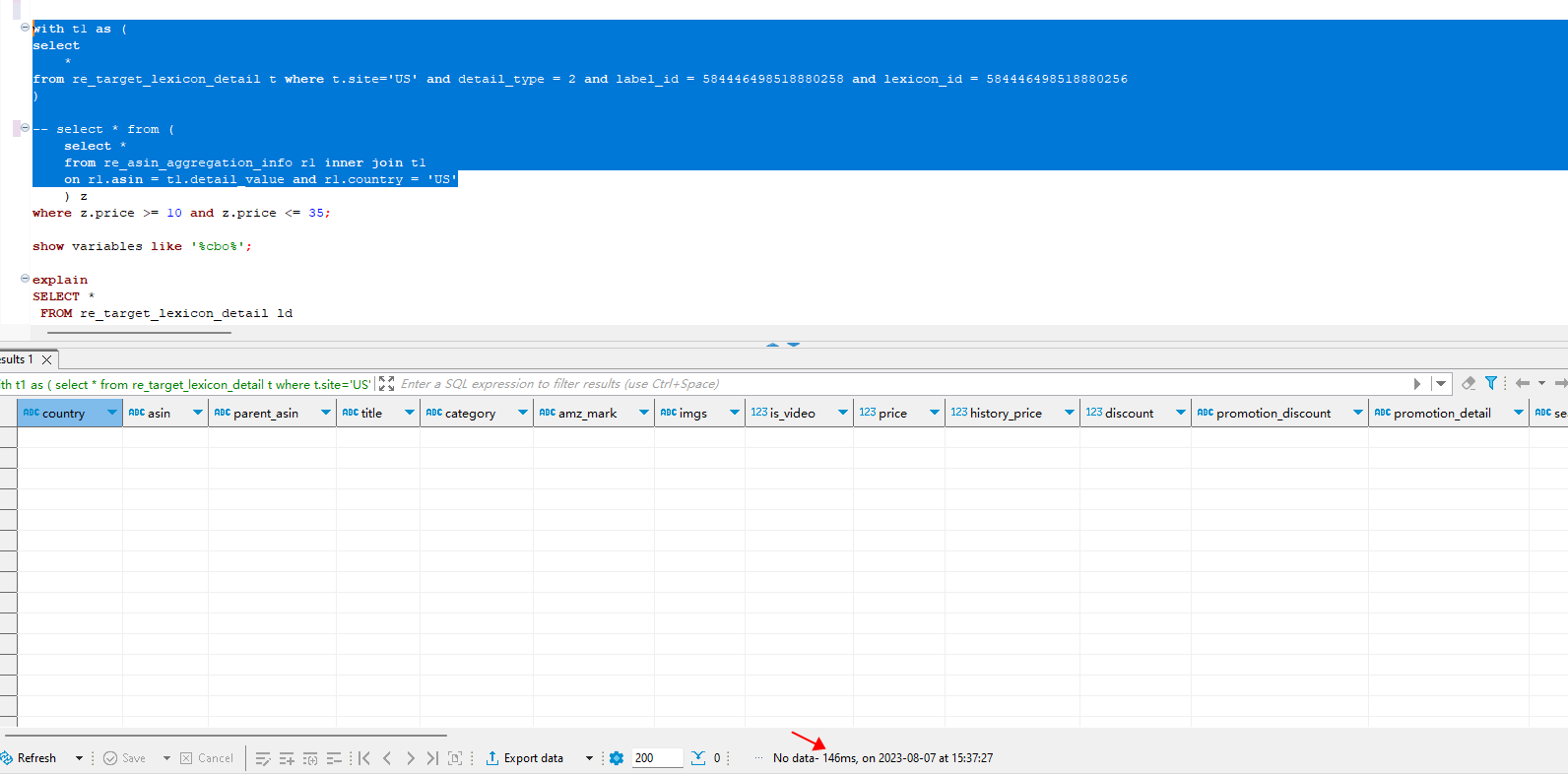
– 使用过滤条件的sql, 直接查询报 exceed memory limit 的错误,加上 set enable_spill=true;
set spill_mode=“force”; 后需要跑10min 以上才能出结果,结果也是没有数据
with t1 as (
select
*
from re_target_lexicon_detail t where t.site=‘US’ and detail_type = 2 and label_id = 584446498518880258 and lexicon_id = 584446498518880256
)
select * from (
select *
from re_asin_aggregation_info r1 inner join t1
on r1.asin = t1.detail_value and r1.country = ‘US’
) z
where z.price >= 10 and z.price <= 35;
慢查询的相关信息如下:
query_dump_file (13.8 KB) explain.txt (1.9 KB) explain_costs.txt (9.4 KB) profile.txt (48.0 KB)