
【详述】问题详细描述
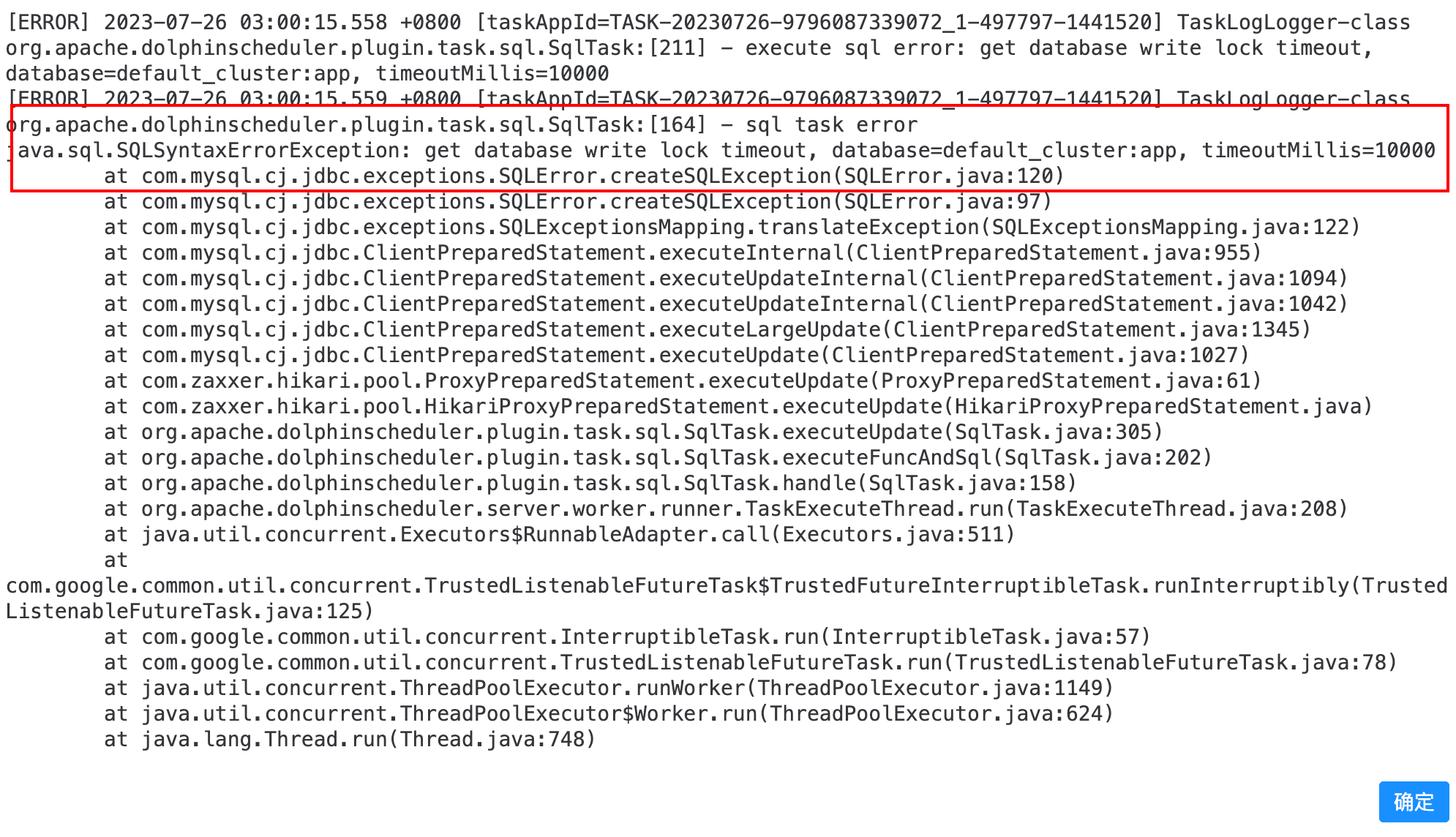
使用dolphinscheduler jdbc方式和python连接starrocks,写数据时,报execute sql error: get database write lock timeout, database=default_cluster:app, timeoutMillis=10000,这个错误应该是最近才出现的,我调了参数:txn_commit_rpc_timeout_ms=30000,也不生效
【背景】做过哪些操作?
【业务影响】
数据写入失败
【StarRocks版本】2.3.10
【集群规模】3fe(3 follower)+ 3be
【机器信息】CPU虚拟核/内存/网卡,16C/64G/万兆
【表模型】UNIQUE模型
【导入或者导出方式】python,jdbc(insert into)
【联系方式】社区群5-老张
【附件】
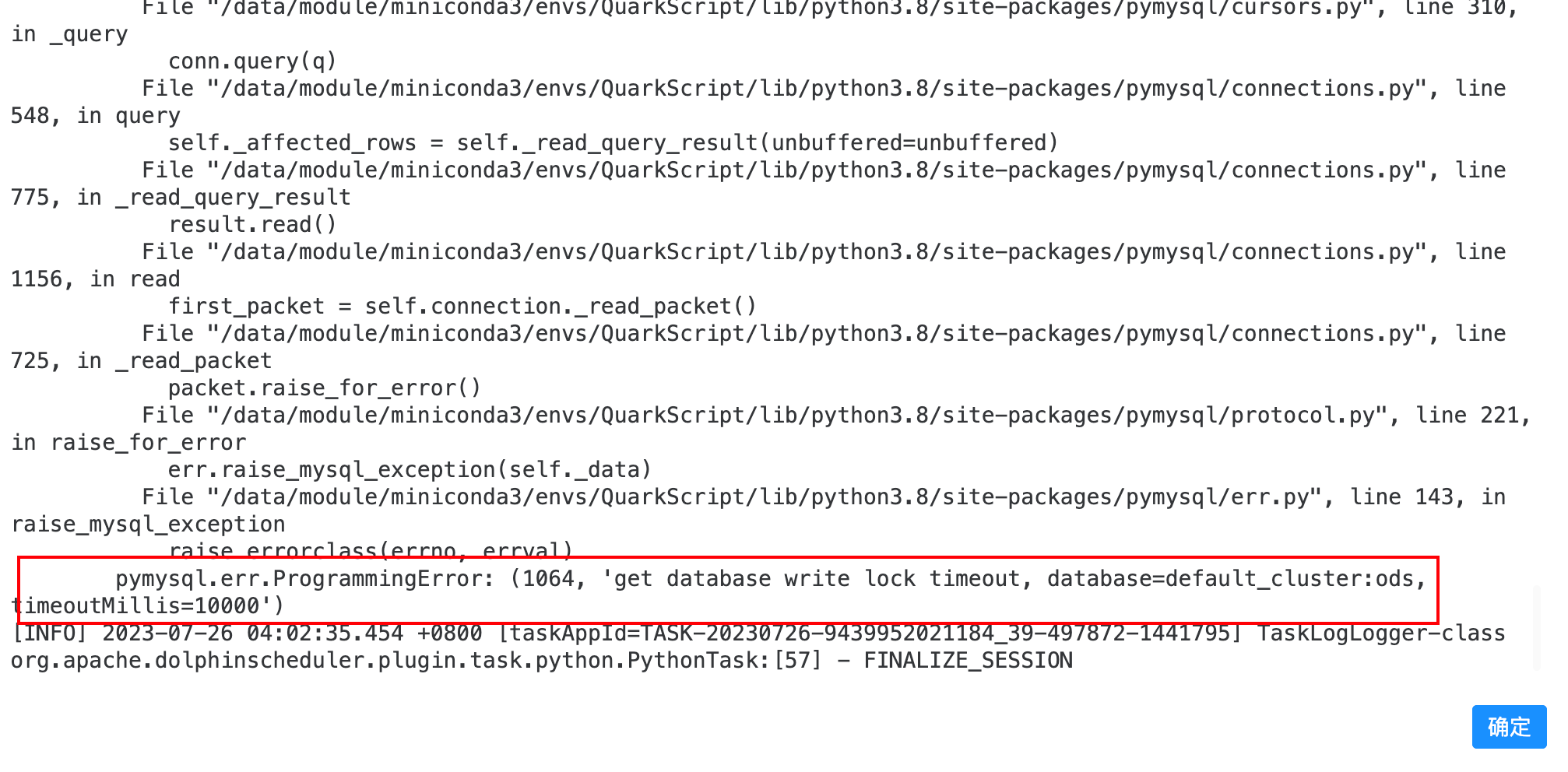
补充下:fe.log中有大量的此类日志:2023-07-26 00:00:17,127 WARN (starrocks-mysql-nio-pool-8018|409382) [Database.logTryLockFailureEvent():157] try db lock failed. type: writeLock, current
2023-07-26 00:00:17,127 WARN (starrocks-mysql-nio-pool-8018|409382) [StmtExecutor.handleDMLStmt():1270] handle insert stmt fail: insert_501a52ca-2b04-11ee-9fbd-06322d653dc1
com.starrocks.common.UserException: get database write lock timeout, database=default_cluster:ods, timeoutMillis=10000
at com.starrocks.transaction.GlobalTransactionMgr.commitAndPublishTransaction(GlobalTransactionMgr.java:348) ~[starrocks-fe.jar:?]
at com.starrocks.transaction.GlobalTransactionMgr.commitAndPublishTransaction(GlobalTransactionMgr.java:337) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.handleDMLStmt(StmtExecutor.java:1248) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.execute(StmtExecutor.java:447) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.handleQuery(ConnectProcessor.java:325) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.dispatch(ConnectProcessor.java:443) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.processOnce(ConnectProcessor.java:706) ~[starrocks-fe.jar:?]
at com.starrocks.mysql.nio.ReadListener.lambda$handleEvent$0(ReadListener.java:55) ~[starrocks-fe.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_341]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_341]
at java.lang.Thread.run(Thread.java:750) [?:1.8.0_341]