【详述】20并发压测同一sql,发现在scan步骤非常耗时,不知道瓶颈是不是在IO上,从profile里看到IOTaskWaitTime时间非常长,不知道这个指标是什么含义
【背景】
【业务影响】
【StarRocks版本】例如:2.5.5
【集群规模】例如:3fe(3 followerr)+3be(fe与be混部)
【机器信息】64C/128G/万兆
【联系方式】
【附件】
- 慢查询:Untitled-7.yml (42.9 KB)
- Profile信息
- 并行度:1
- pipeline是否开启:开启
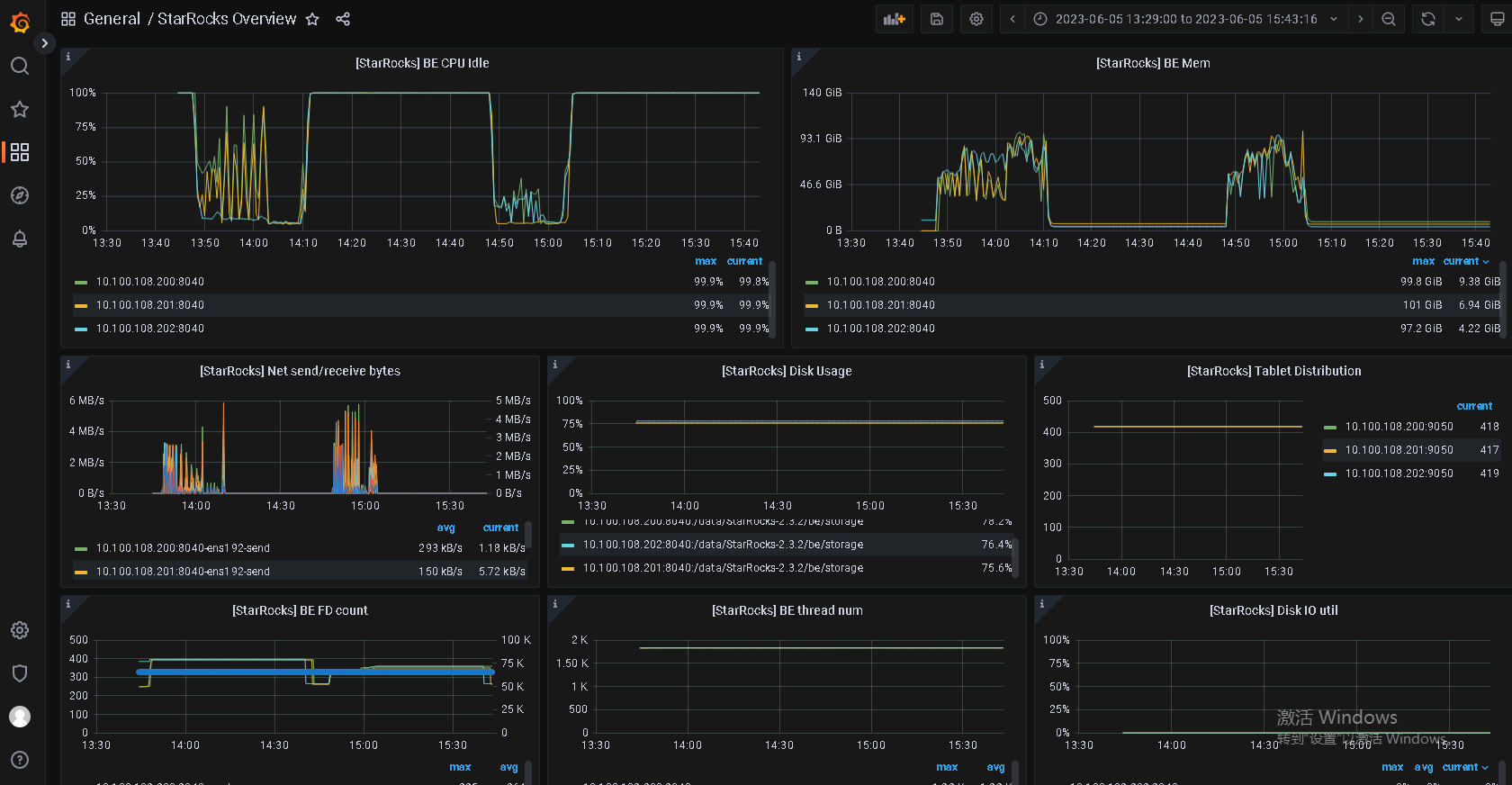
- be节点cpu和内存使用率截图