
卡住时, 可以用gdb attach到进程上, set pagination off 后thread apply all bt看一下http线程都在做什么. 可以发出来看看.
可以打个pstack 看看,可能是与主键模型导入有关系,最近我们修复过类似问题。
连接的是Fe,转发到be
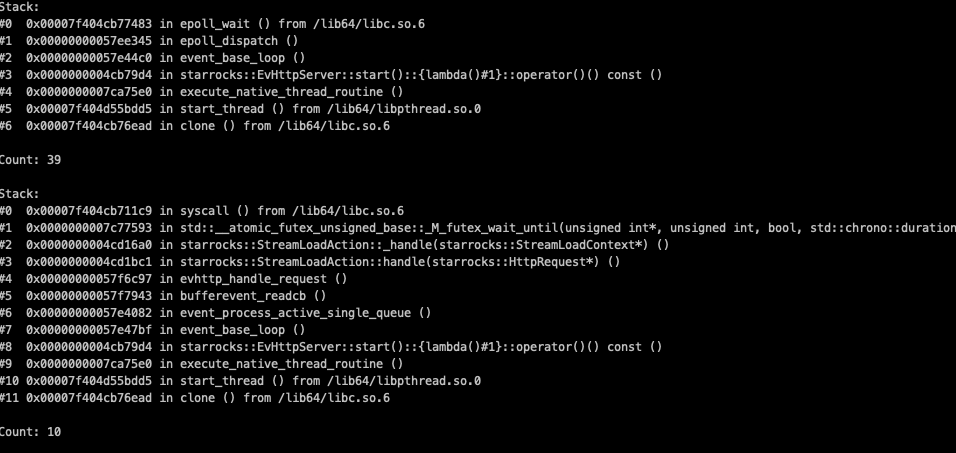
和主键模型没有关系,我就是用ssb的数据做导入(节点1个, 数据量10G),然后监测metric接口的响应时间。
看上去有10个线程卡在starrocks::StreamLoadAction::_handle这儿了, 调整过be_http_num_workers这个参数吗?
这个就是streamload的处理线程呀,be_http_num_workers这个默认48个,所以上面有39个(其中一个是我加的httpserver)还是空闲的。
还有空闲的http server线程, 按说metrics不应该卡, 可以手动发起一个GET :8040/metrics, 卡住时, pstack看一下处理/metrics的线程在哪儿卡住了.
头疼,我上面的pstack信息就是卡主的时候搞的。我上面的描述是有啥问题吗,感觉没看明白的样子。
你描述的没有问题, 按现在pstack上的信息, 38个线程idle, 10个在做streamload, 没看到metrics HTTP请求去到哪儿了, 所以可能没有捕捉到metrics卡住的现场
我能说我抓了好多次都是这样吗? 而且本来就只有10个并发的streamload请求,远小于be_http_num_workers定义的, 那么必然不是在http处理线程,而是在前面的socket的监听线程之类的上把。虽然我还是没找到,然后从抓包看,http请求已经到了这个节点。。。。确实就是返回慢,
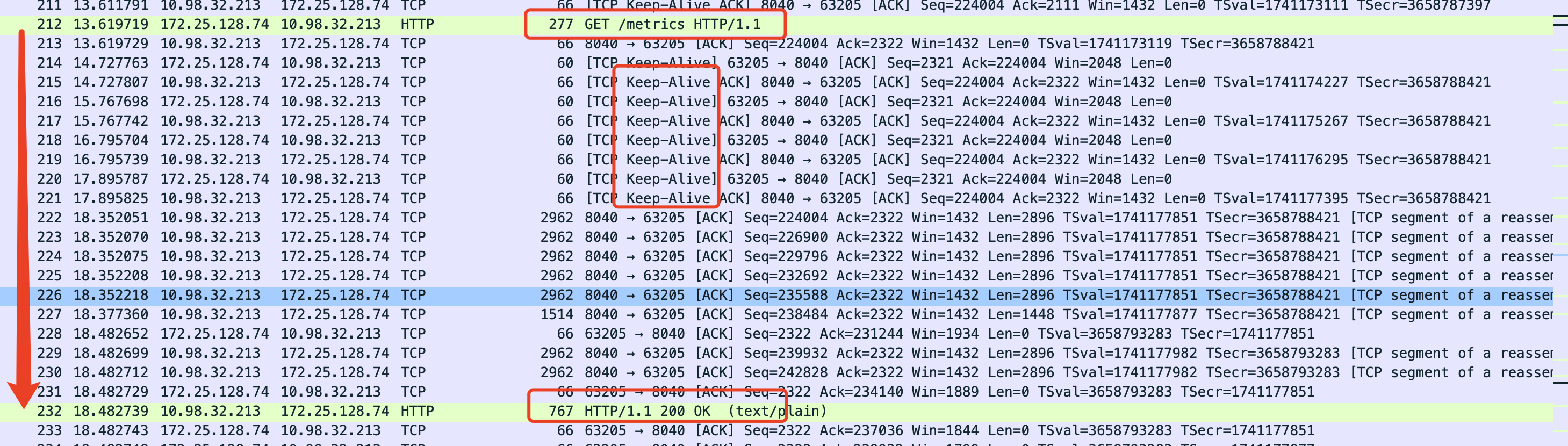
卡住的同时, 看一下cpu load, 网络io, tcp socket SendQ/RecvQ长度, 感觉您自己快到定位到问题根因了.
能详述一下你的集群配置吗?几个BE,BE的CPU/MEM,使用的BE版本,stream load重现的步骤. 帮助我们自己重现这个问题,谢谢
重现步骤很简单,版本我用的2.5.3, 一台机器,fe be混部,8c 32G的样子,然后官网ssb测试的步骤导入10G的数据(当然改了下表的副本数1)并发应该默认就是10。 然后导入过程,就每隔秒发起metric请求,就 能复现了。
好的, 谢谢! 我这边尝试复现一下
请问您测试时的网络拓扑是什么样的? 看上面截图里, 一个在10.x段, 一个在172.x段
172 的是我的客户端的postman,没关系吧,只是发个metrics请求而已。数据是在befe的混布节点上发起的,也就是10。
是这样操作后没复现吗?
没有复现, 我调整成20并发, ssb 100g, BE用4c,32G, 8c,32G都没有复现.
你可以尝试一下, 用我们的2.5.6版本能否一样复现?