
【详述】StarRocks2.5.5 K8s版本启动后频繁刷Invalid port 0日志
【背景】在K8s集群中采用helm安装
【业务影响】
【StarRocks版本】例如:2.5.5
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/256G/万兆
【联系方式】weijiasheng@189.cn,谢谢
【附件】

进程可以启动成功是吧,fe的网络配置是什么?BTW,3个fe节点的话建议是1leader + 2follower
是全新部署吗?
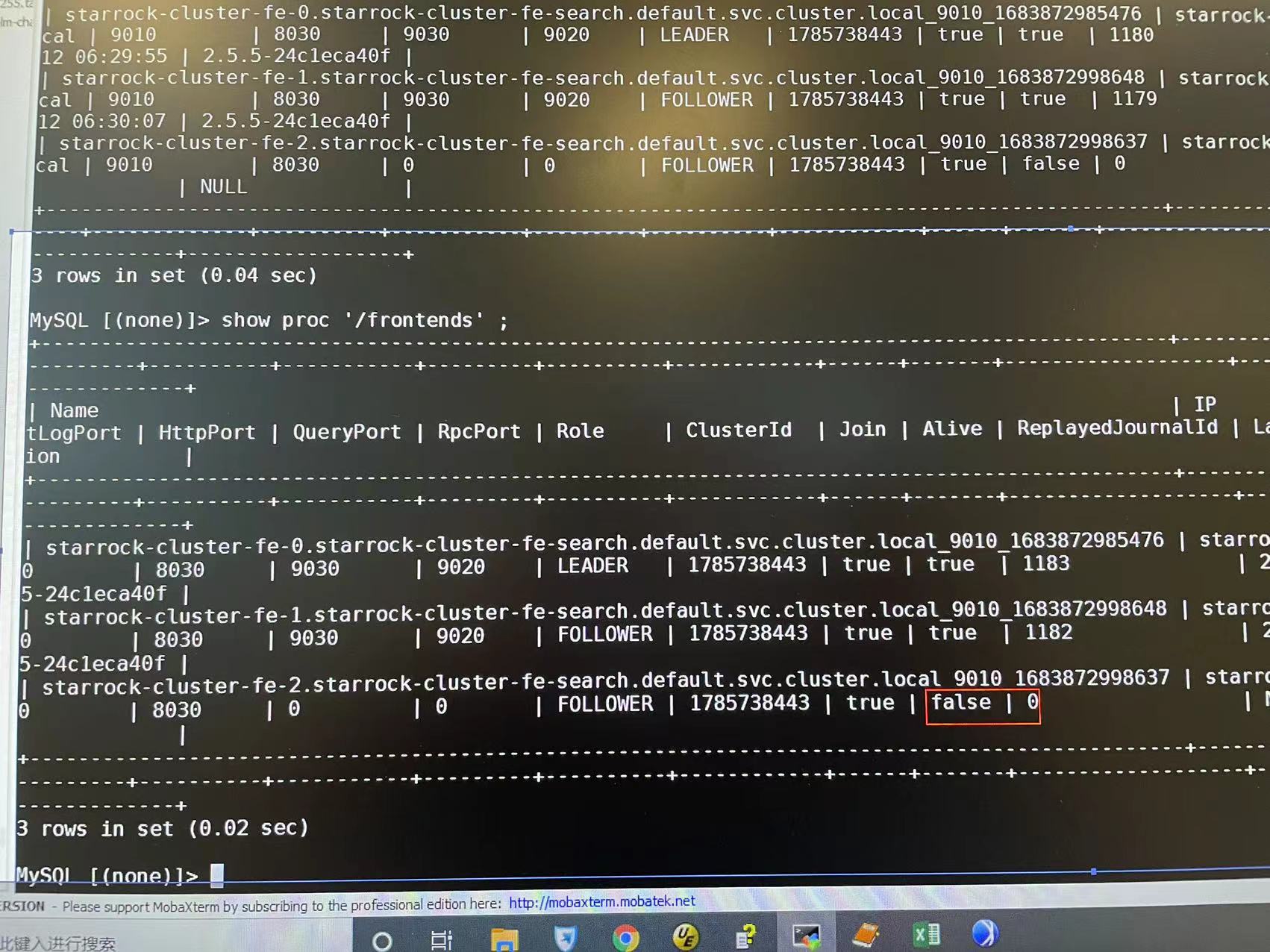
show frontends的输出可以文字贴出来, 能看得全.
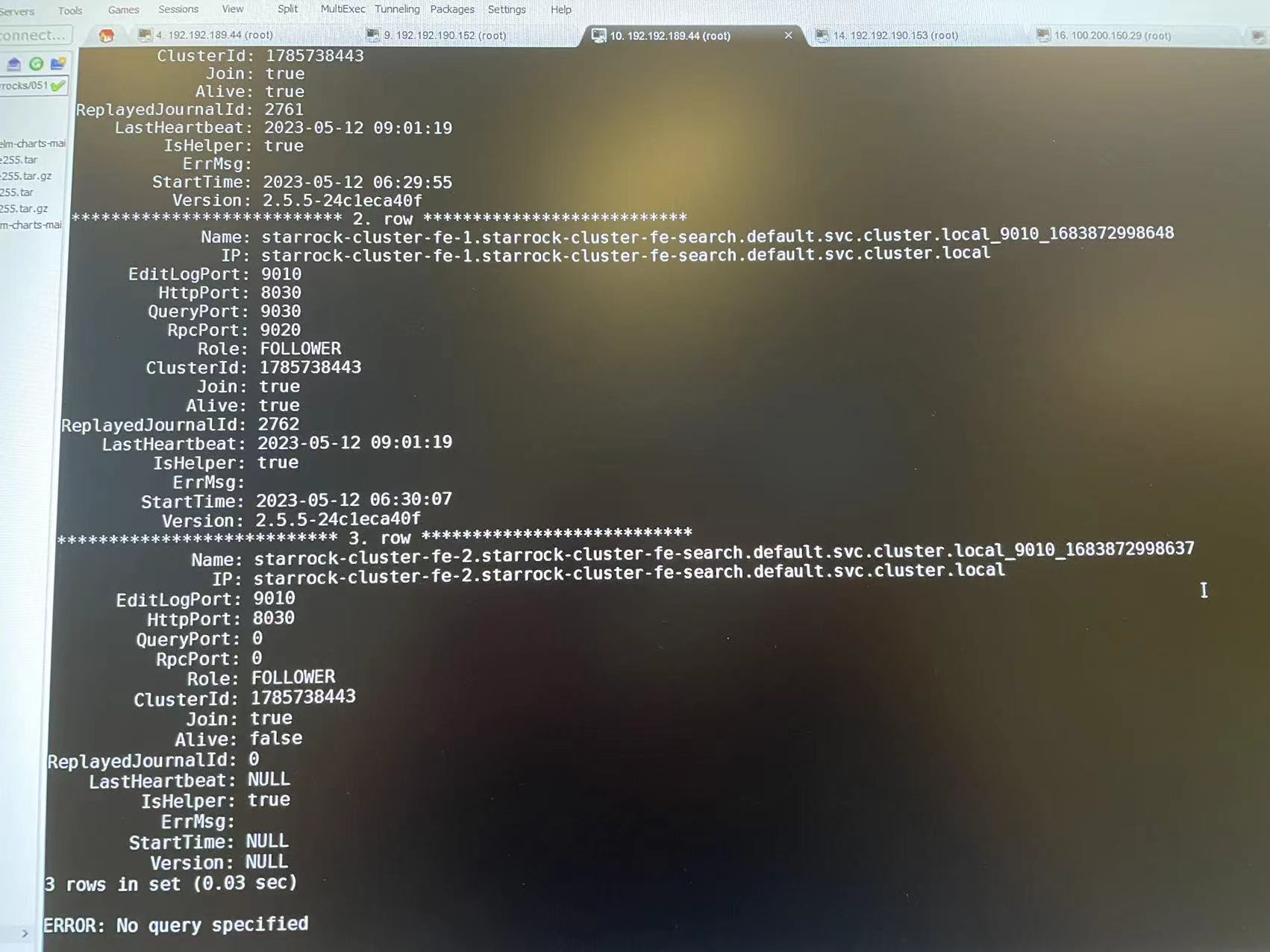
看上面, FE-2好像认为自己的LEADER. 应该是有问题的, 可以尝试把fe/meta/目录下所有数据删除, 再重建这个POD, 试试看能不能加回到FE集群里.
感觉像是starrockscluster集群之前用过, 删除重建了, 但之前FE的PVC数据没有清理, 导致节点以之前的残留meta数据启动, 状态不一致.
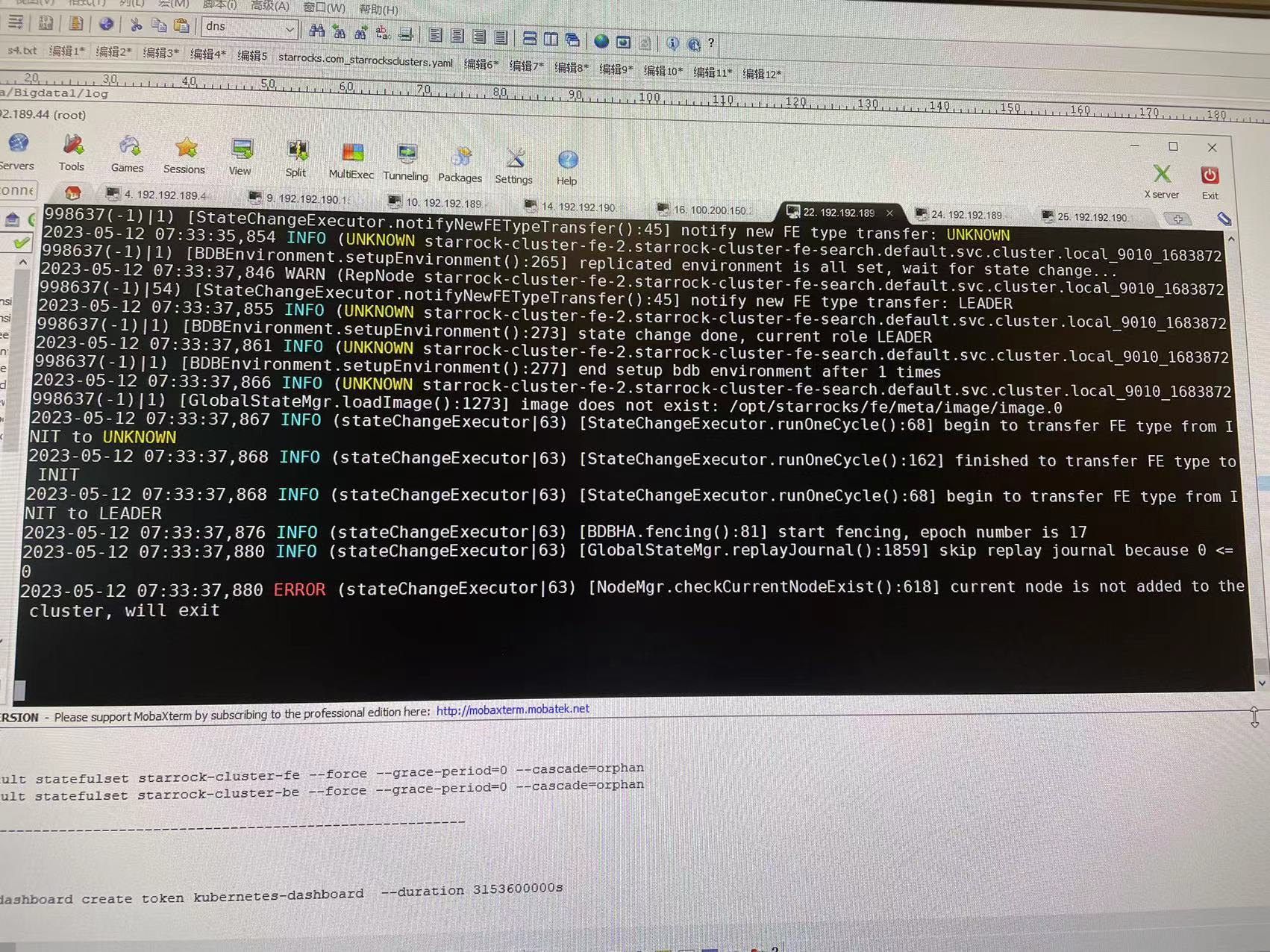
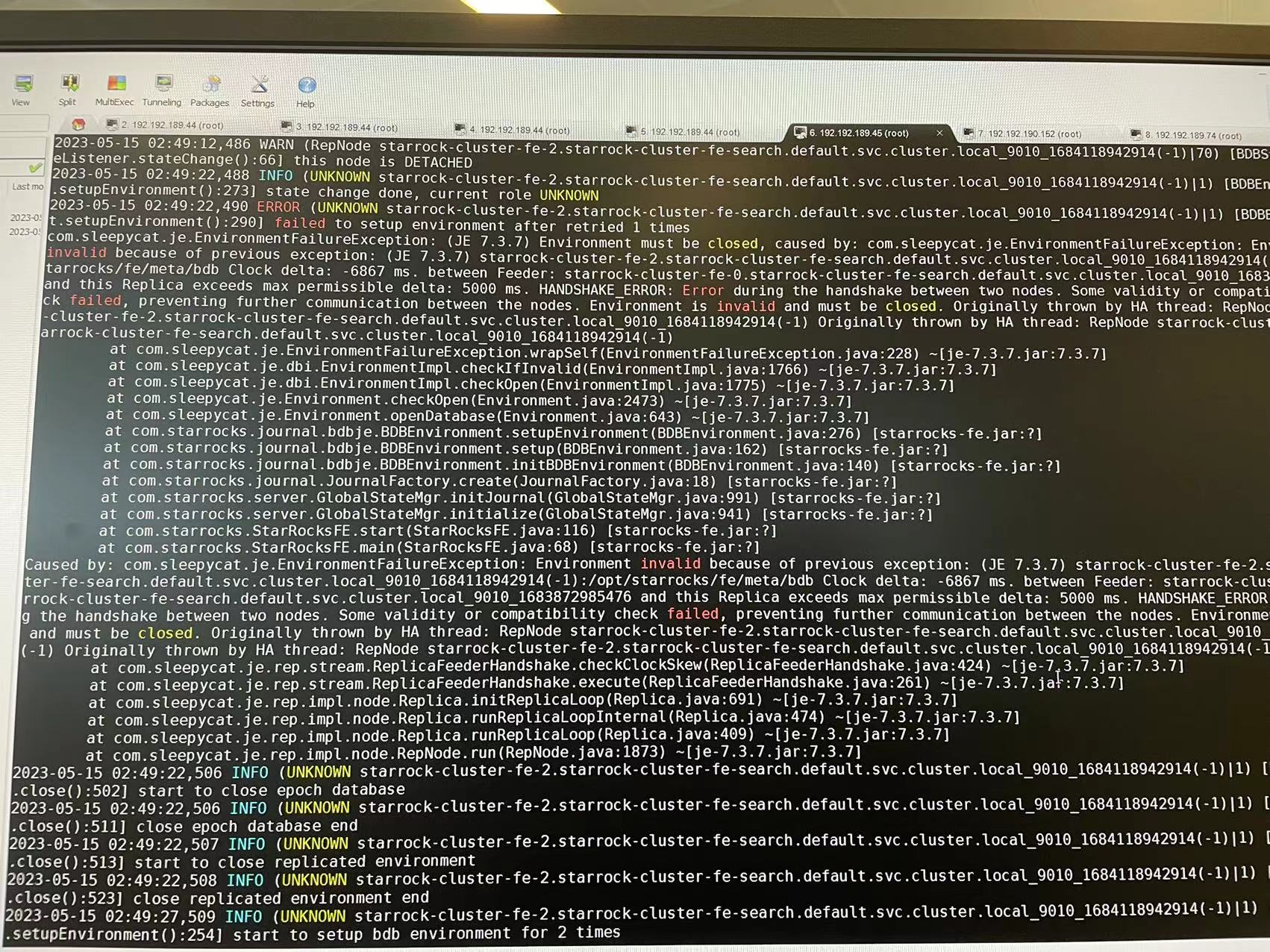
需要发一下fe-0的fe.log和fe-1的fe.log看看
可以重新发一下show frontends输出. 日志里当前的LEADER是fe-2, 与之前发的截图不一致.
可以mysql单独连接到每个FE节点, show frontends看一下, 看上去像是FE脑裂了, 三个FE不在同一个集群里.
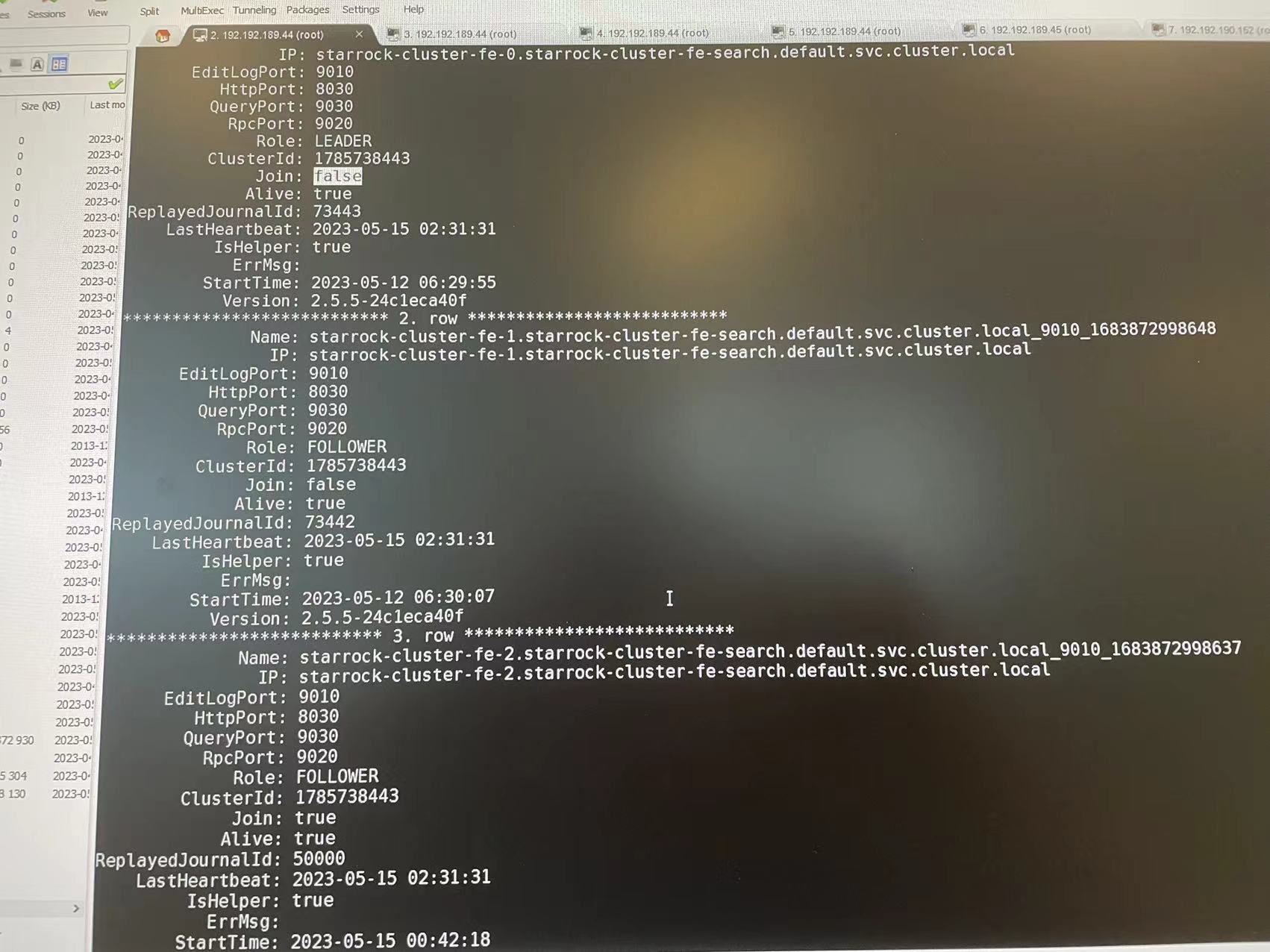
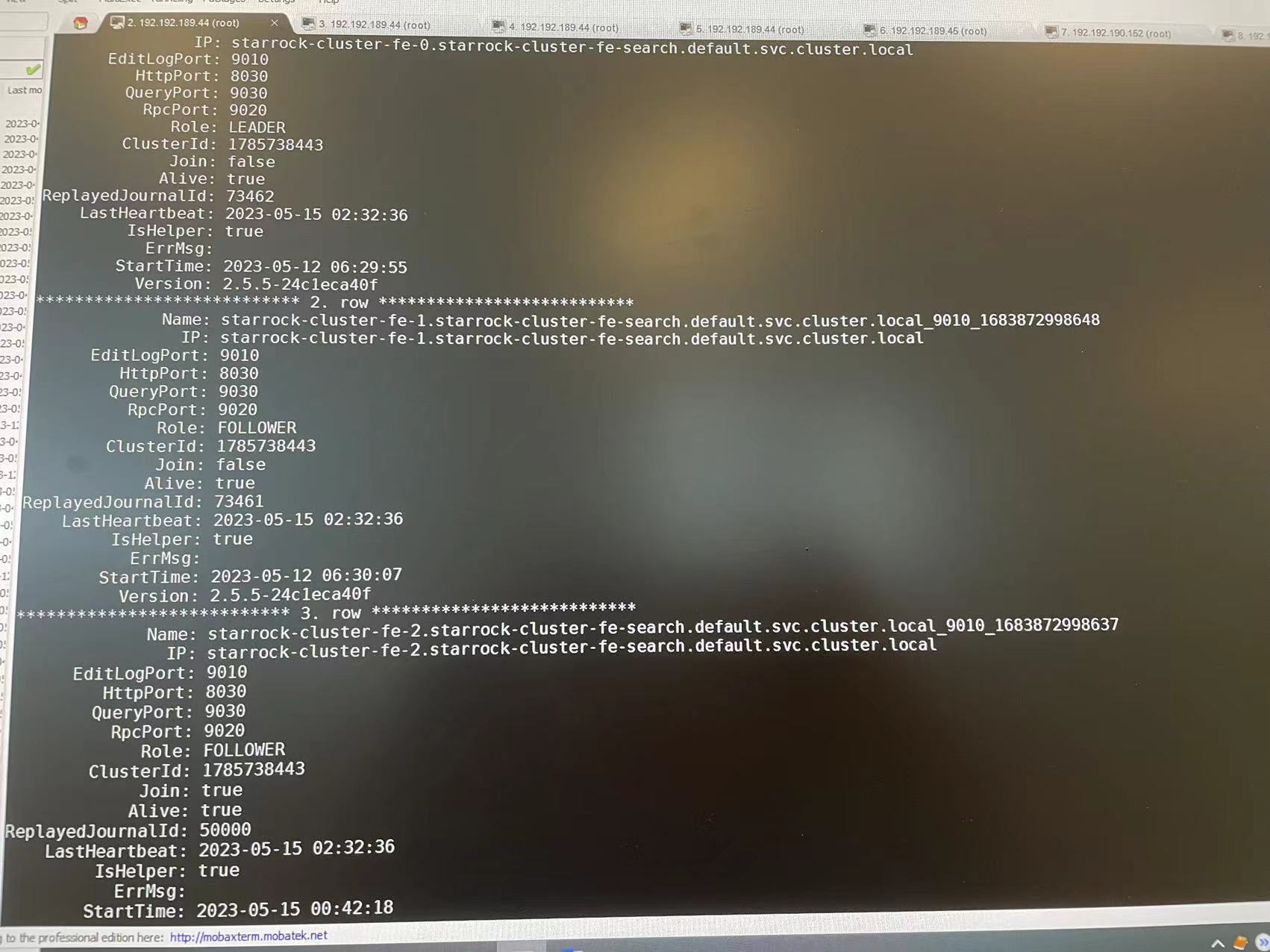
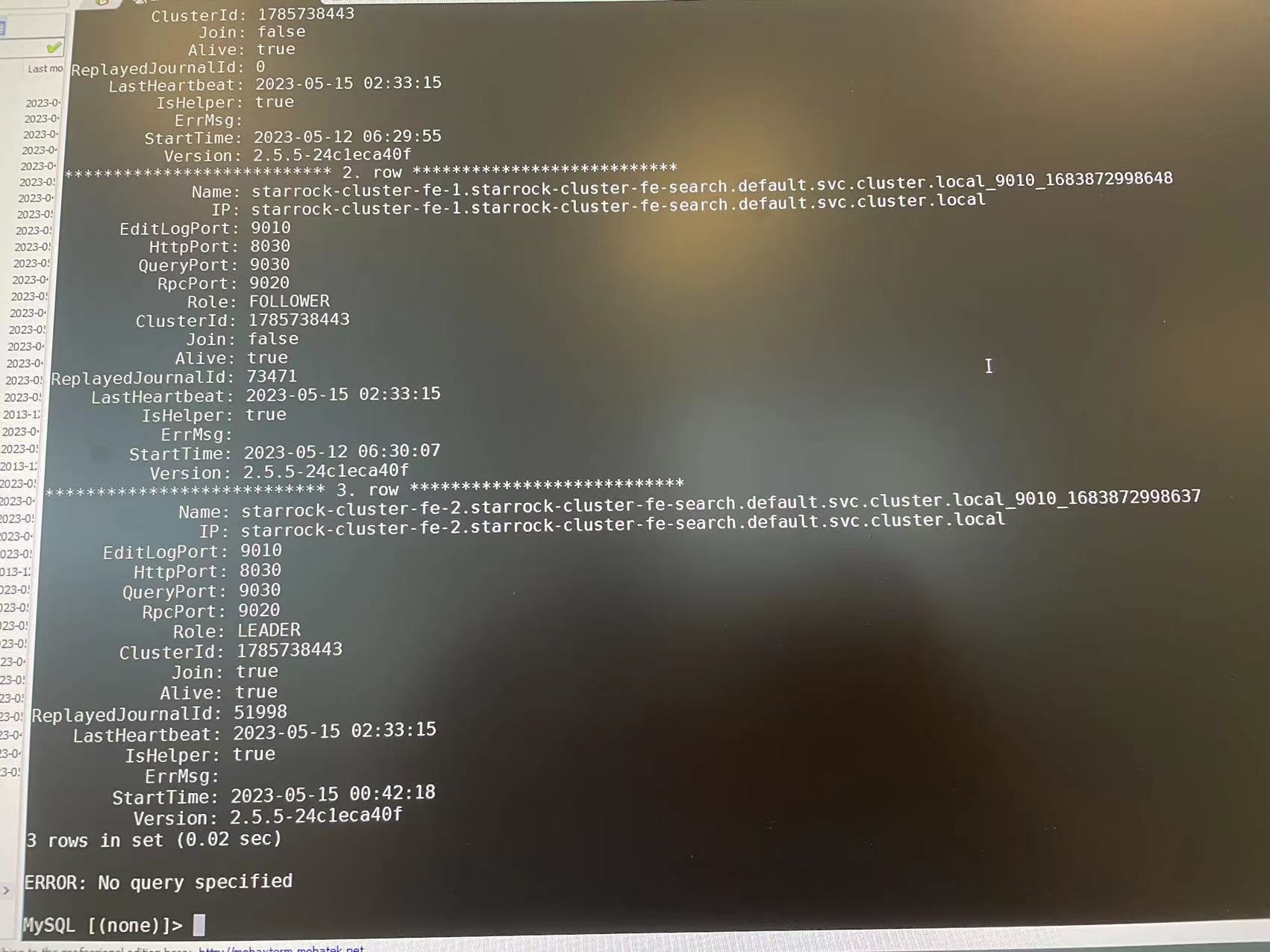
从各个FE的show frontends信息上来看, 是脑裂了.
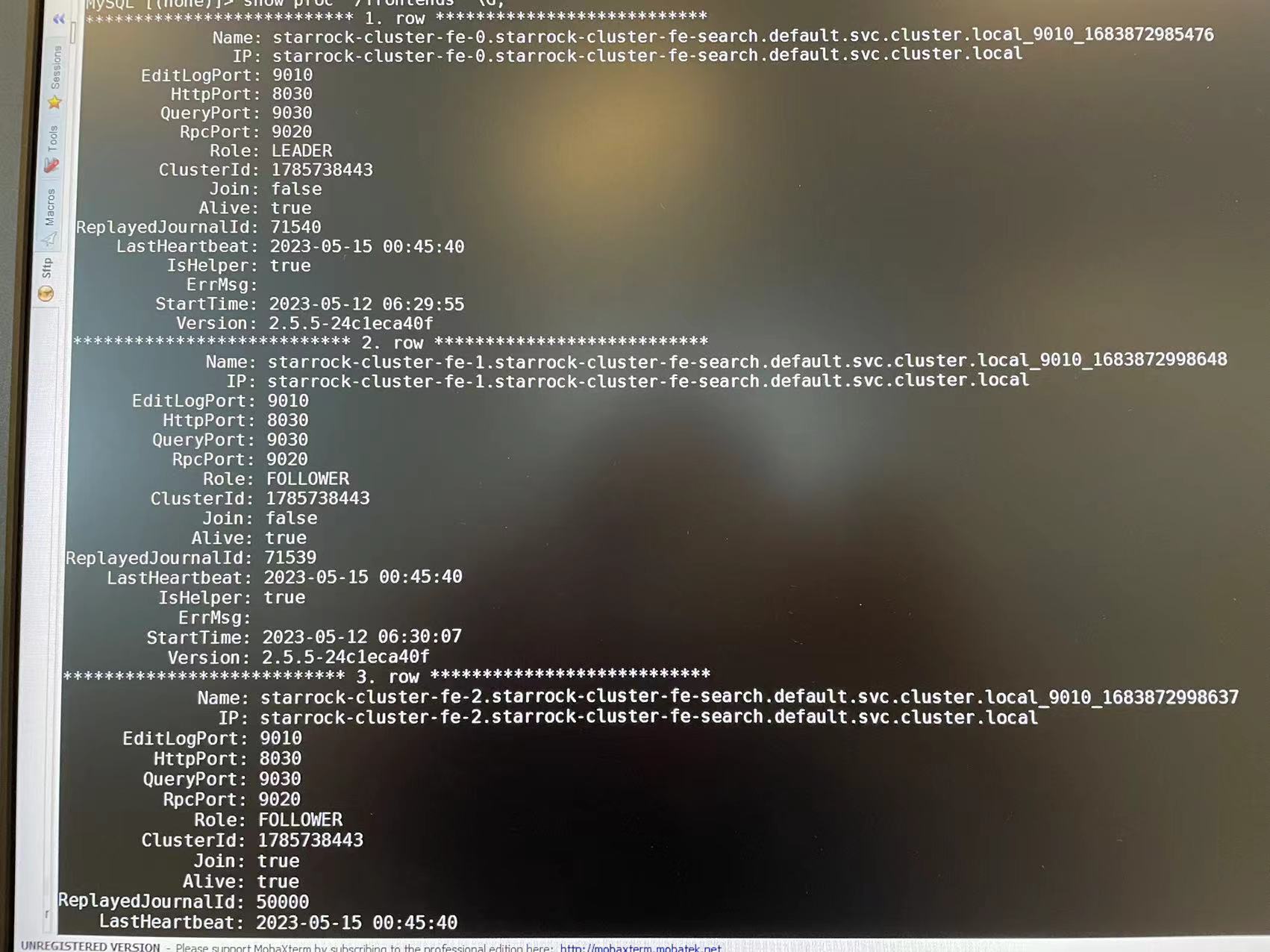
那请问下Join字段和Helper字段的含义是什么吗?
join表示是否成功加入集群, helper表示该节点是否可以做为help节点, 帮助未加入集群的节点获取集群信息加入到集群中.
脑裂问题,我找到问题了,应该是时间同步问题引起了,目前3台fe的状态都是一样的,mysql也能正常建表查询了,但是fe的日志还是频繁刷Receive packet header failed,请问正常吗?应该怎么处理
这个可以忽略, 是k8s上我们配置POD alive probe导致的. 后续会改成探测http port.
参见https://github.com/StarRocks/starrocks-kubernetes-operator/issues/47