
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【StarRocks版本】例如:1.18.2
【集群规模】例如:1fe+4be
【附件】
- fe.log/beINFO/相应截图
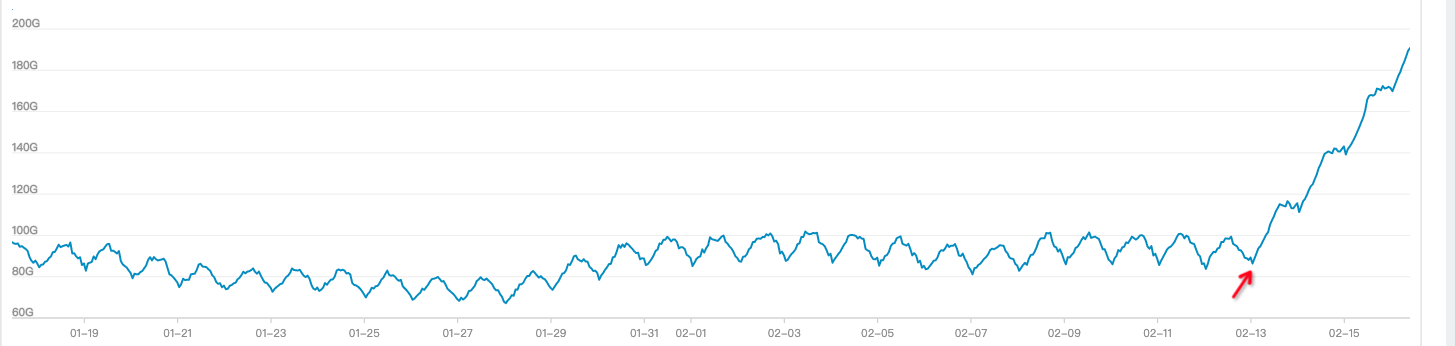
fe 所用磁盘在2月13日后突增

看 meta/bdb 目录发现一直在新增 .jdb 文件

fe.warn.log 显示了如下的异常:
2023-02-16 00:00:34,021 ERROR (leaderCheckpointer|75) [Checkpoint.runAfterCatalogReady():106] Exception when generate new image file
java.lang.IllegalStateException: InfoSchemaDb id shouldn’t larger than 10000, please restart your FE server
at com.google.common.base.Preconditions.checkState(Preconditions.java:510) ~[spark-dpp-1.0.0.jar:?]
at com.starrocks.server.LocalMetastore.loadCluster(LocalMetastore.java:3598) ~[starrocks-fe.jar:?]
at com.starrocks.server.GlobalStateMgr.loadImage(GlobalStateMgr.java:1131) ~[starrocks-fe.jar:?]
at com.starrocks.master.Checkpoint.runAfterCatalogReady(Checkpoint.java:87) [starrocks-fe.jar:?]
at com.starrocks.common.util.MasterDaemon.runOneCycle(MasterDaemon.java:61) [starrocks-fe.jar:?]
at com.starrocks.common.util.Daemon.run(Daemon.java:115) [starrocks-fe.jar:?]