【详述】一个大查询导致BE节点内存上涨后10多分钟才能降下来,造成其他写入失败,主键索引可用内存超过限制错误.
【背景】大表做join 关联内存上涨后下不来
【业务影响】
【StarRocks版本】2.2.6
【集群规模】例如:3fe(3 follower)+54be(fe与be分开部署)
【机器信息】CPU虚拟核/内存/网卡,例如:16C/54G/万兆
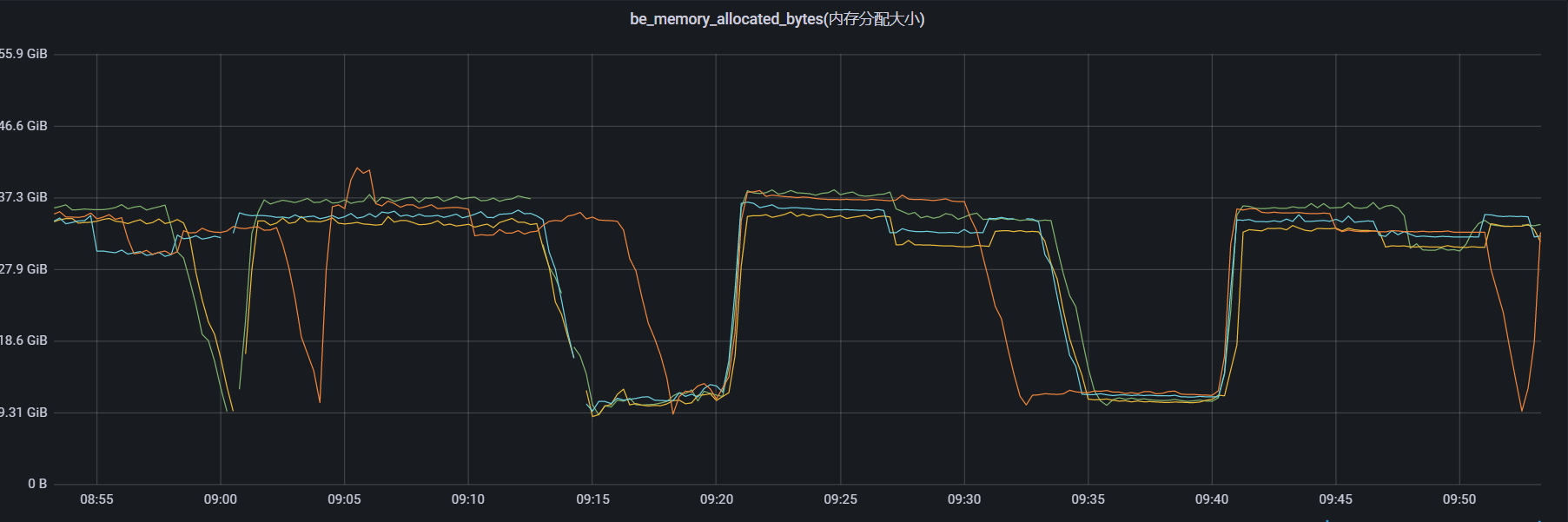
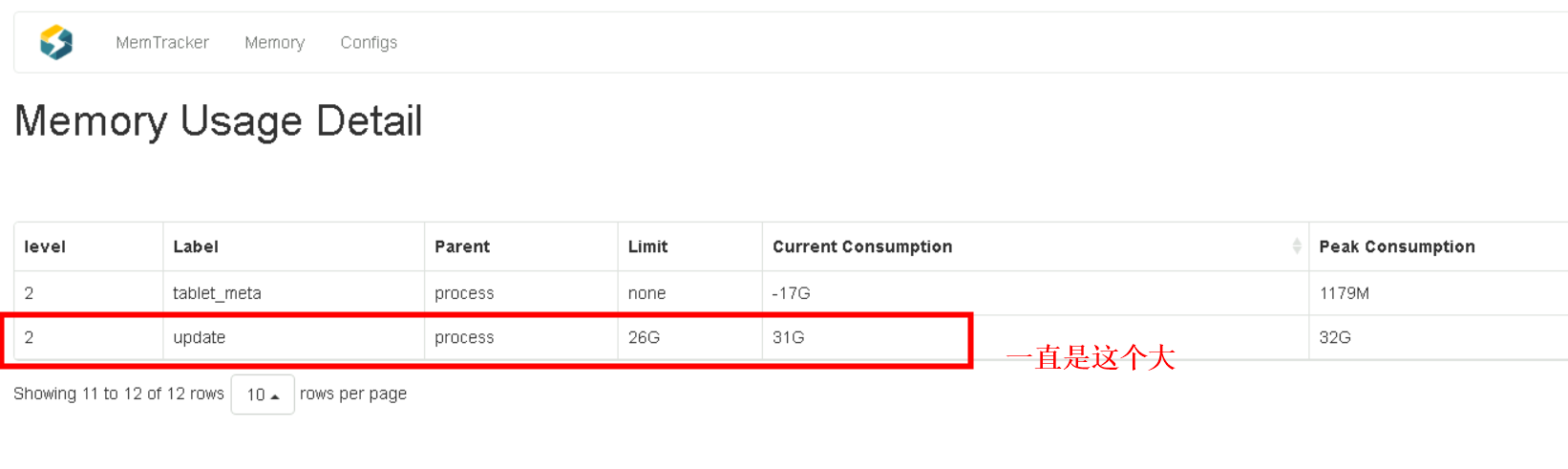
这个内存释放很慢

【详述】一个大查询导致BE节点内存上涨后10多分钟才能降下来,造成其他写入失败,主键索引可用内存超过限制错误.
【背景】大表做join 关联内存上涨后下不来
【业务影响】
【StarRocks版本】2.2.6
【集群规模】例如:3fe(3 follower)+54be(fe与be分开部署)
【机器信息】CPU虚拟核/内存/网卡,例如:16C/54G/万兆
看监控主要是主键模型使用的内存,sr 2.3.0 版本起,StarRocks 支持配置enable_persistent_index参数, 设置后同时使用磁盘和内存存储主键索引,避免主键索引占用过大内存空间。通常情况下,持久化主键索引后,主键索引所占内存为之前的 1/10。您可以在建表时,在 PROPERTIES 中配置该参数,取值范围为 true 或者 false (默认值)。 建议您升级到2.3最新版本。 大表join占用内存较高时,可以看下是否可以将两个表设计为colocate join。parallel_fragment_exec_instance_num , exec_mem_limit 并行和内存上限可以调低
之前没事,今天发现有个别的表导入数据的时候,可能是数据原因跨了很多分区,而且每个tablet很大,每个都超过1G了,加载了大量的tablet,不是说只用key列放入内存吗?怎么就是在Stremload的时候会去加载对应分区里面的tablet呢?是类似于Mysql一样重建主键索引吗?造成update 那个label 瞬间上去了
主键模型在导入数据时,如果导入的数据只在一个tablet里面, 是会只加载这个tablet的主键索引, 不过一般导入几条数据,随机分配到partition下所有tablet, 概率上做不到正好分配到一个tablet里, 肯定是partition下所有的tablet的主键索引都会加载到内存。当跨多个分区时,需要加载到内存中的主键索引变多。 主键索引占用内存估算方式请参考: 数据模型 @ Data_model @ StarRocks Docs
实际占用的是tablet的大小,不是索引的大小,显示的占用内存大小和tablet的大小一样,为什么会把整个tablet都加载到内存中呢?这点有点不明白。因为我们这里有些场景确实是会跨很多分区,但是就算是这样,主键索引也没有那么大啊,然而是加载的tablet到内存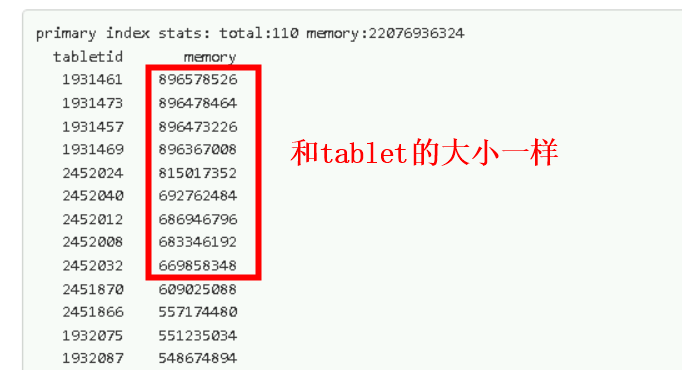
主键模型使用内存过高的话(update),可以升级到2.4,然后使用persistent_index,可以解决这个问题
