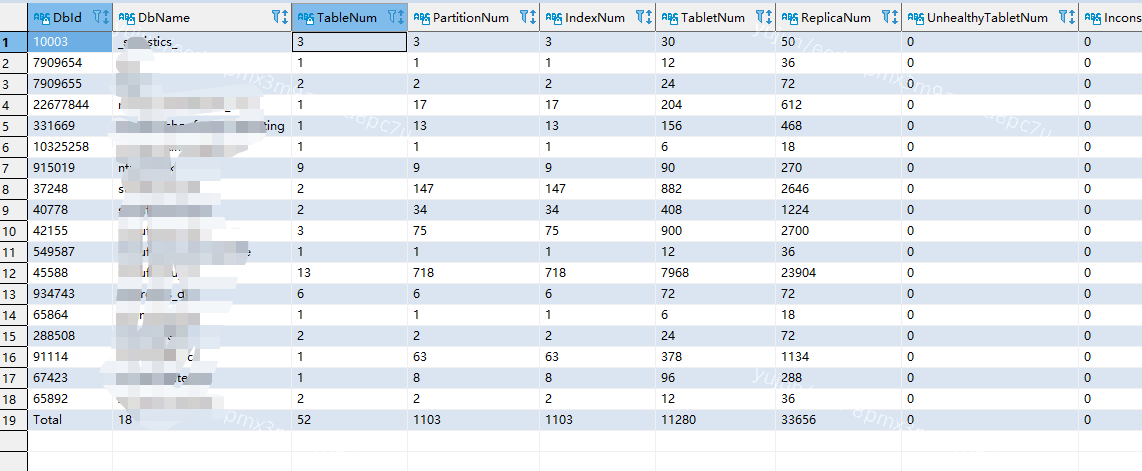
【详述】3fe+3be fe节点经常因为oom掉线,掉线后无法正常重启,需要踢出集群后重新加入。集群没有高负载,只是通过stream load同步数据,具体信息见日志
【背景】小版本升级 从2.4.1升级到2.4.2
【业务影响】
【StarRocks版本】例如:2.4.2
【集群规模】例如:3fe +3be
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
内存信息
total used free shared buff/cache available
Mem: 7551 1957 1556 0 4037 5304
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
fe日志.txt (143.6 KB)feconf.txt (1.1 KB)