
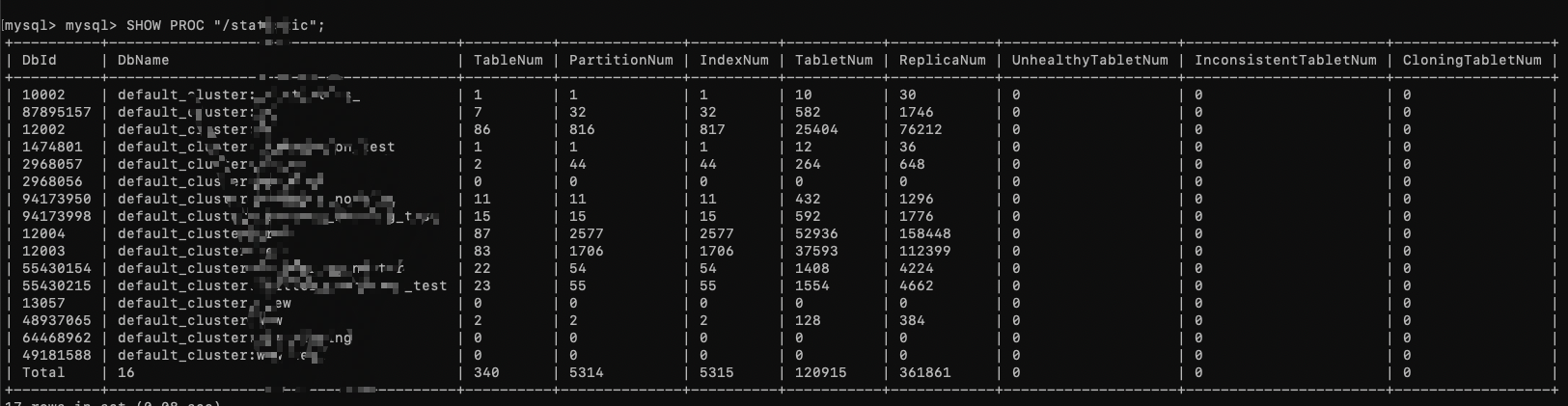
主键模型表有没有使用索引落盘的功能?SHOW PROC “/statistic”;看下集群有没有不健康副本数?导入频率高不高?通过监控看下compaction score值高不高?
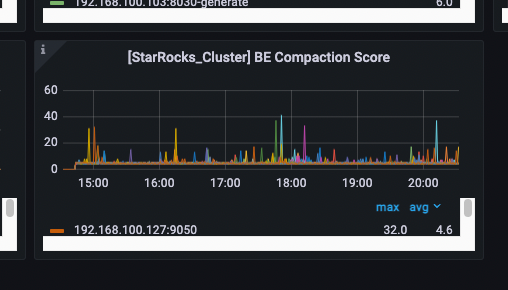
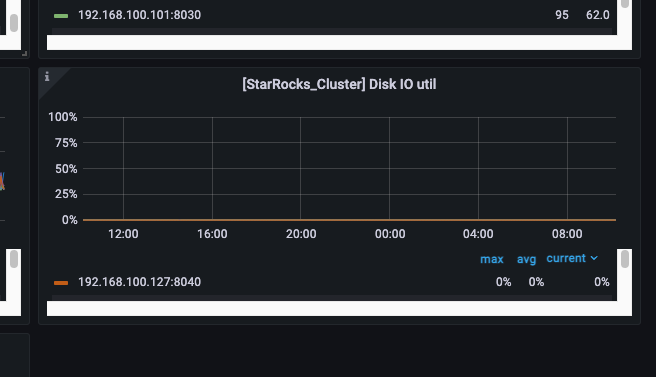
磁盘IO的监控您方便发下吗?有没有观察升级前后磁盘IO的情况?
磁盘是NVME 的ssd 基本没有IO
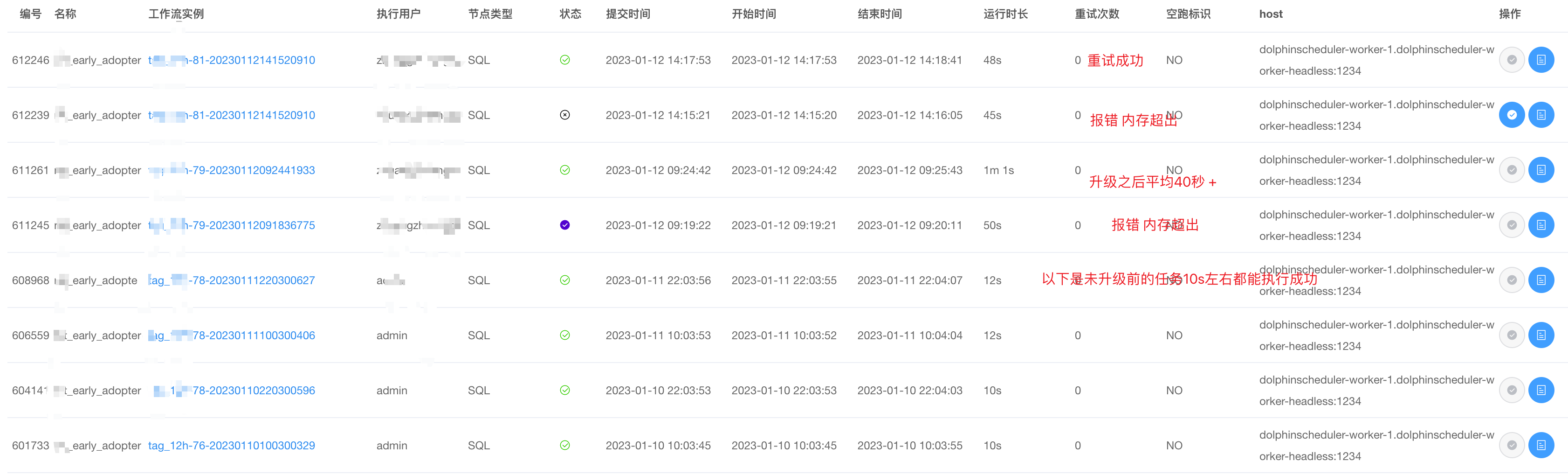
截止到当前依旧很高,集群中大的数仓任务已经无法正常运行了
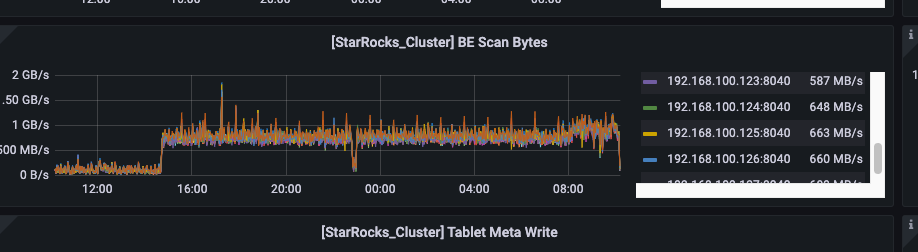
计划回退到2.2.10 这个版本有类似的情况吗
我是从2.1.12升级到 2.3.7,是否能直接回退2.2.10 ?
观察出现问题的时间点是fe升级重启之后,be先升级的 be单独升级完好像没有这个情况
麻烦看下集群现在pipeline有没有开启,2.3默认是开启的,如果开着的话你先关掉再观察看看
执行:
set global enable_pipeline_engine=false;
admin set frontend config (“enable_statistic_collect”=“false”);
之后看起来恢复了,不过目前还是比升级前要高,而且稳定性貌似不如2.1.12,之前版本能跑出来的大查询,新版本无法执行成功,报内存超出限制
大查询的sql一致吗?报超出内存限制是把pipeline关掉之后吗?
是的,同样的任务 ,现在关掉pipe line 执行依旧不成功。
不成功的原因是啥,超时了?
超内存。 能执行成功的大SQL执行速度也明显变慢
ERROR 1064 (HY000): Memory of process exceed limit. try consume:11862016 Used: 74235454456, Limit: 115274475785. Mem usage has exceed the limit of BE
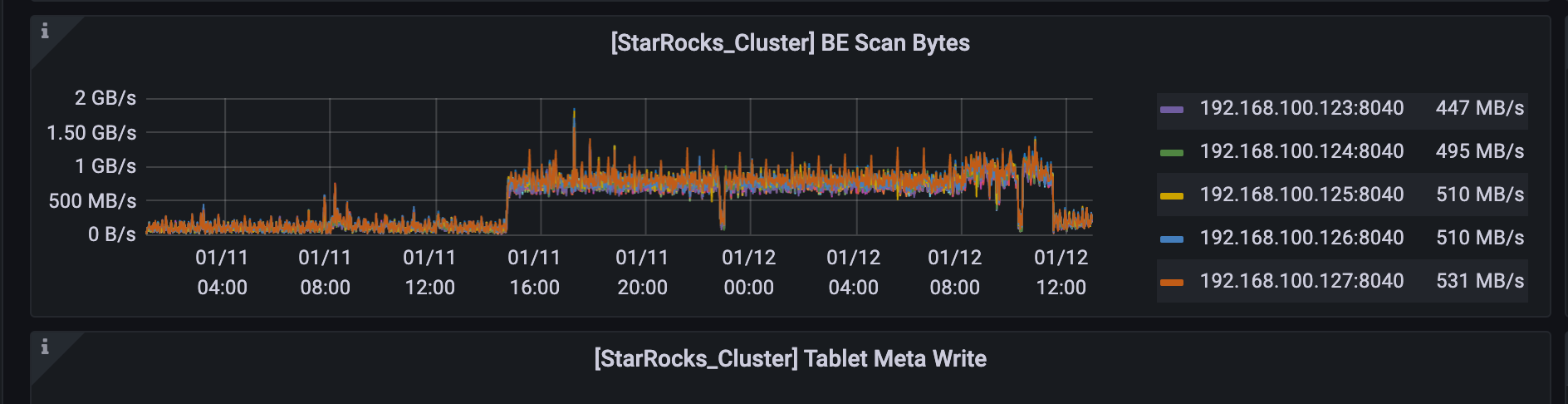
比如下面这个任务的执行时长:由10s 变成 40s + 而且有一定概率报超内存 (11号下午升级到2.3.7, 12日早晨关闭pipeline)
同一个sql能麻烦您跑下开启pipeline和关闭pipeline的profile看下吗?10s和40s+那个sql也可以,需要根据profile看下差异点在哪里
fe queries 的页面里 好像只有成功的SQL ,找不到失败的SQL,而且现在不太方便开pipeline ,这是线上环境开启pipeline 应该还会出现 scan byte 过高,会影响使用
而且我发现 现在大查询运行的时候 只有一个或者两个be的内存会使用特别高,然后一直到limit 被kill
之前这种查询运行的时候,集群共12 个be 内存都会同步上升,现在内存使用都在个别节点上,执行策略不太对感觉
目前计划降级到2.2.10 观察下
是升级集群前后同样的sql吗?查询历史数据(非升级后导入数据的表)也会有这种情况的发生吗?您观察到的这个现象是打开pipeline的时候?
如果您这边还没有进行集群回退的话可以麻烦您做下这些操作发下截图看看吗?
show variables like ‘parallel_fragment_exec_instance_num’;
show variables like ‘pipeline_dop’;
还有be机器的核数: show backends \G;里面可以看到CPU cores
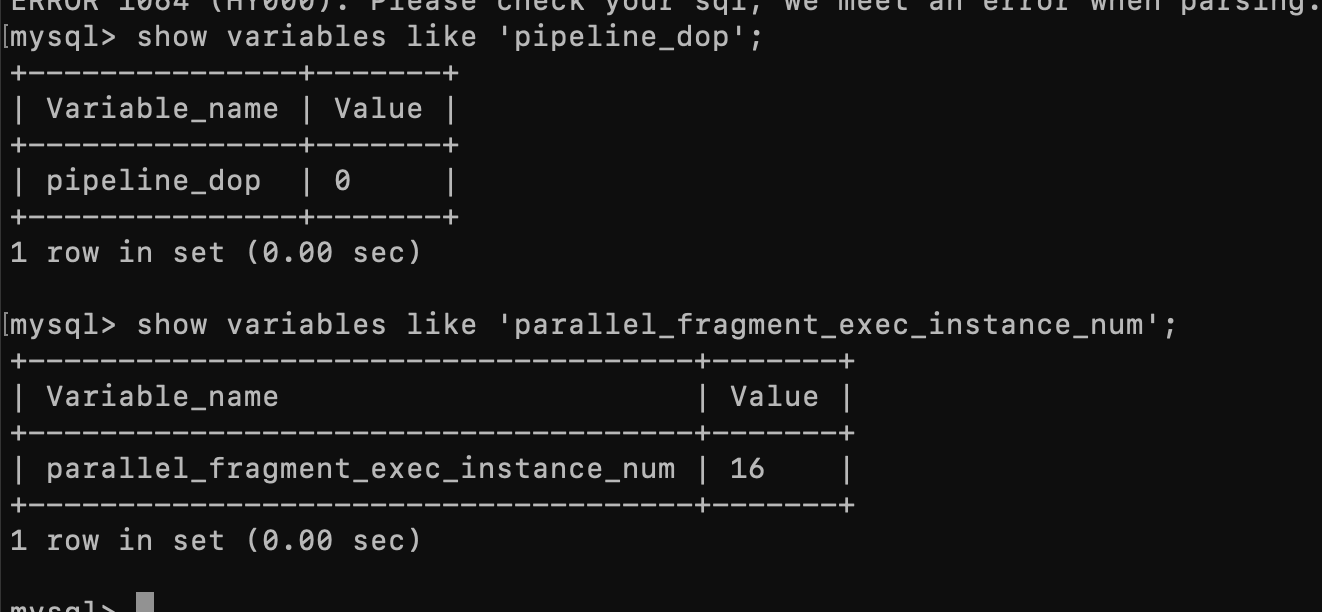
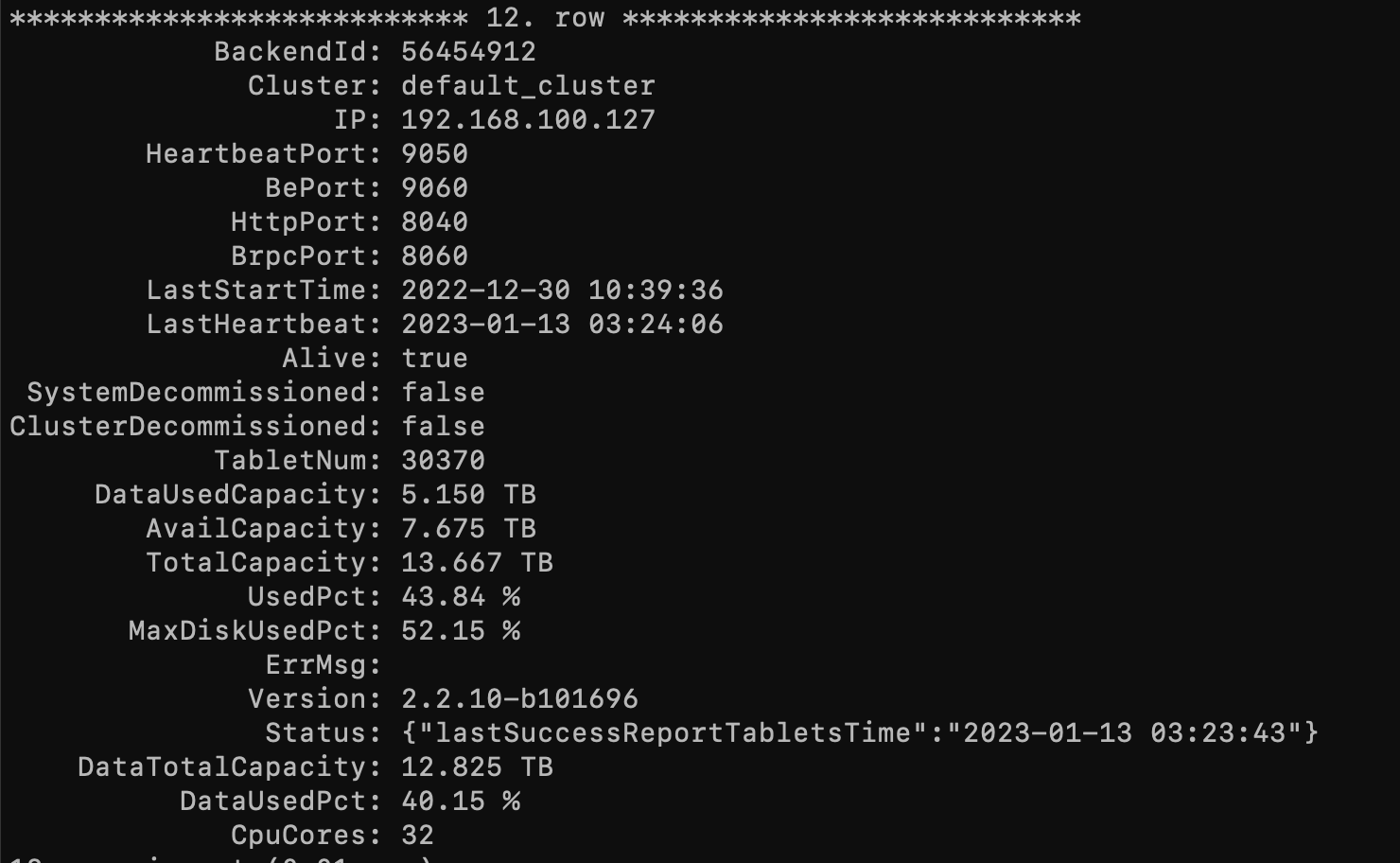
好的收到,请问您这边parallel_fragment_exec_instance_num一直设置的16吗?有更改过吗?能请您帮忙提供几个变慢的sql看看吗?
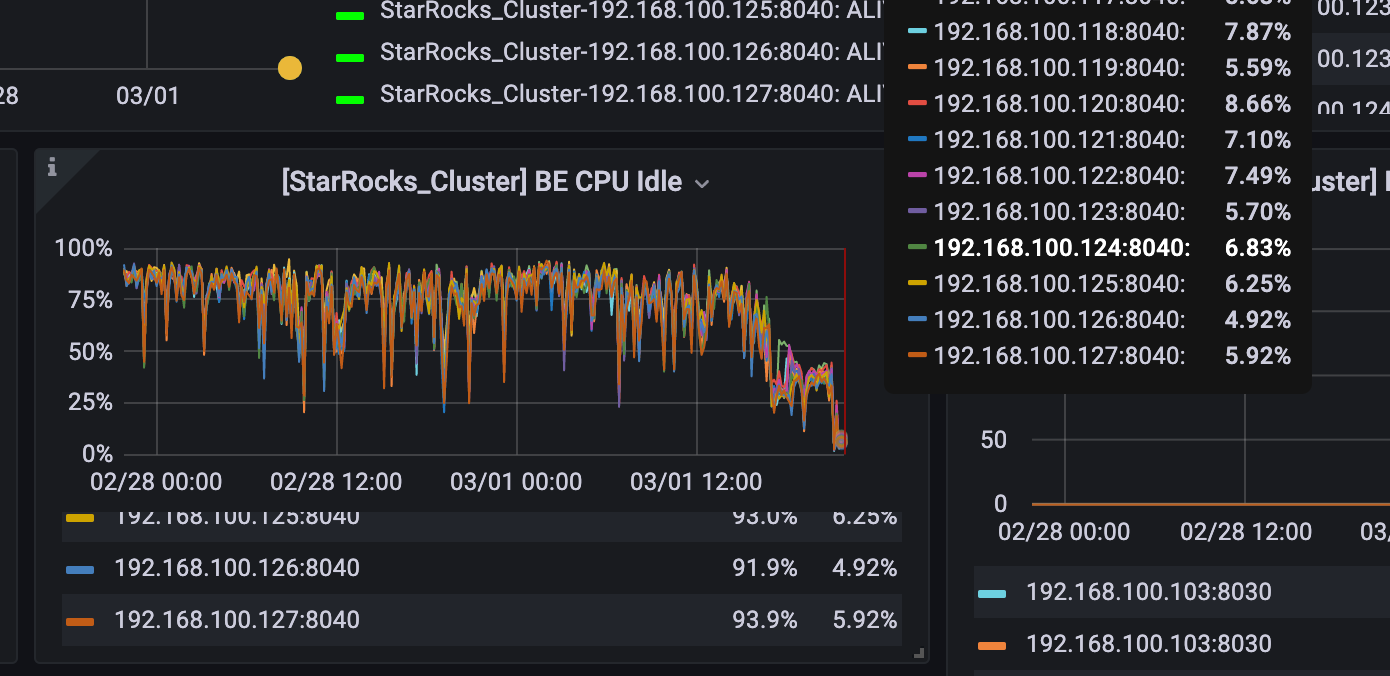
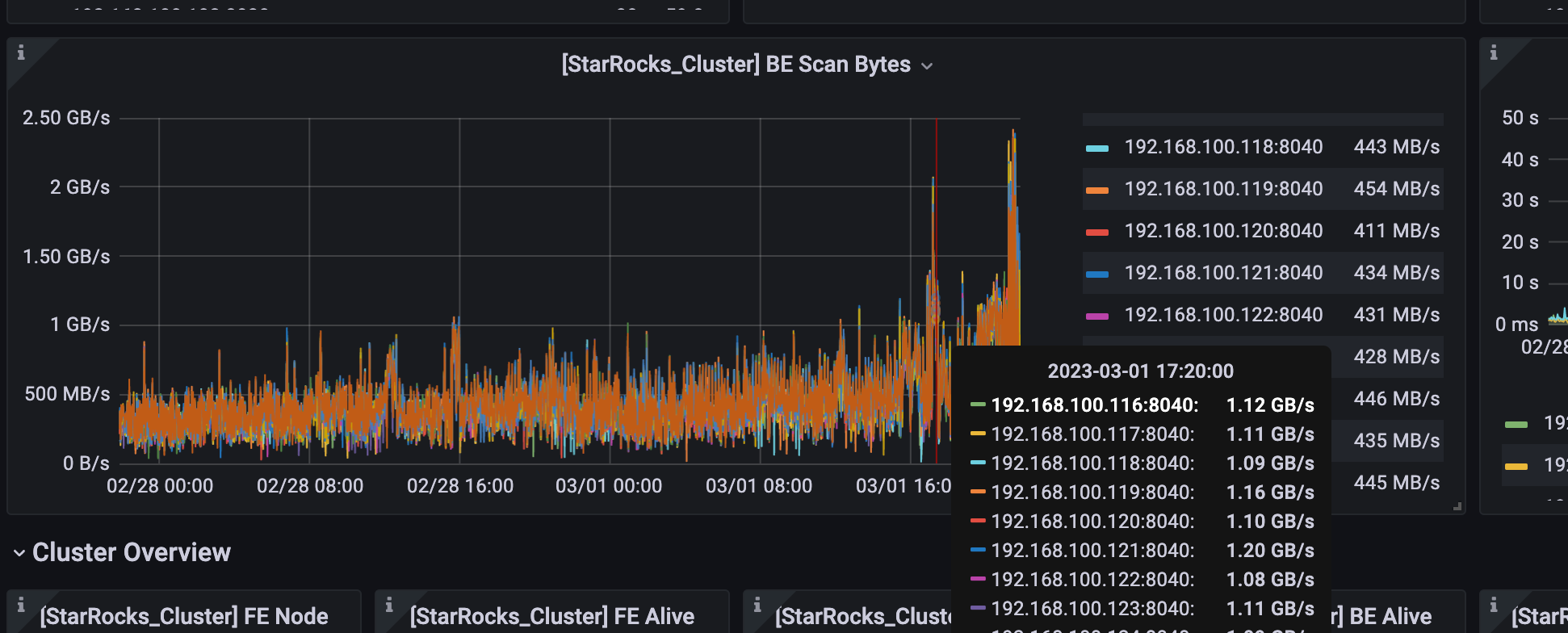
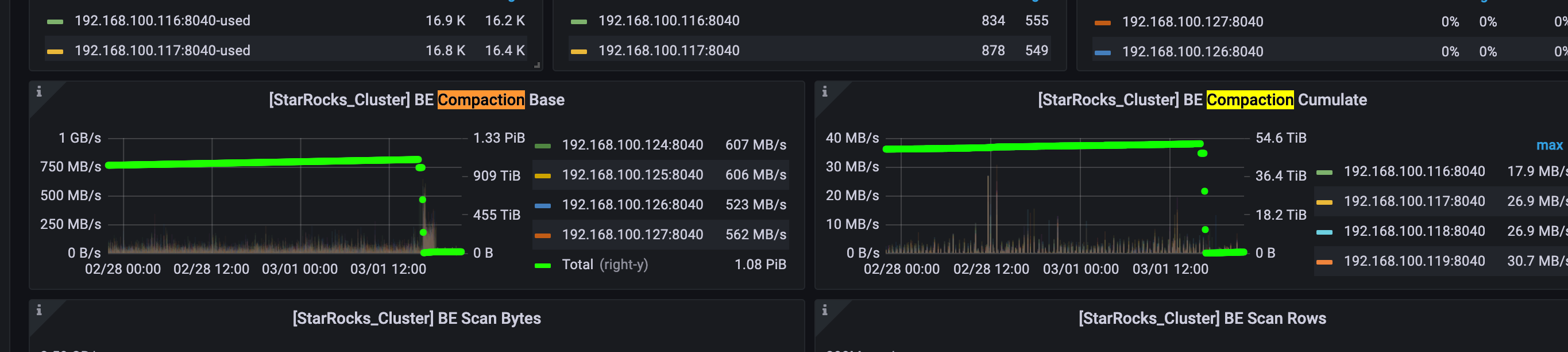
是不是查询也变快了呢?
cpu 使用率高了之后,查询反而变慢了,我今早尝试将pipeline打开,又观察了一段时间好像还是没有什么用