Profile分析及优化指南(pipline 版本StarRocks 2.3+)
背景
我们时常遇到sql执行时间不及预期的情况,为了优化sql达到预期查询时延,我们能够做哪些优化。本文旨在分析查询profile各阶段耗时是否合理以及对应优化方式。
准备
打开profile分析上报。
使用mysqlclient连接starrocks集群,
mysql -h ip -P9030 -u root -p xxx
然后输入
##该参数开启的是session变量,若想开启全局变量可以set global is_report_success=true;一般不建议全局开启,会略微影响查询性能
mysql> set is_report_success=true;
该参数会打开profile上报,后续可以查看sql对应的profile,从而分析sql瓶颈在哪。如何进一步优化。
如何获取profile?
如上设置打开profile上报后,打开fe的http界面(http://ip:8030),如下点击queries后,点击相应sql后的profile即可查看对应信息。

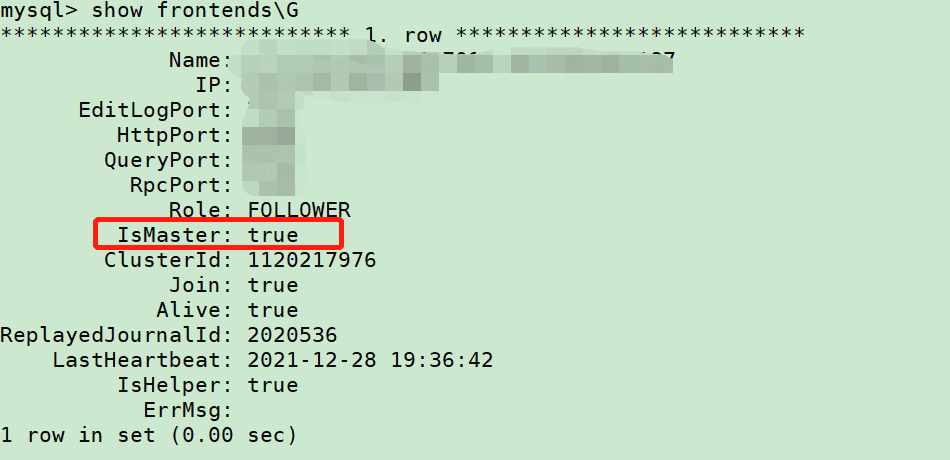
注:此处需要进master的http页面。如不确定集群哪台是master,可以show frontends查看IsMaster值为true的ip
explain分析
Explain sql获取执行计划,如下
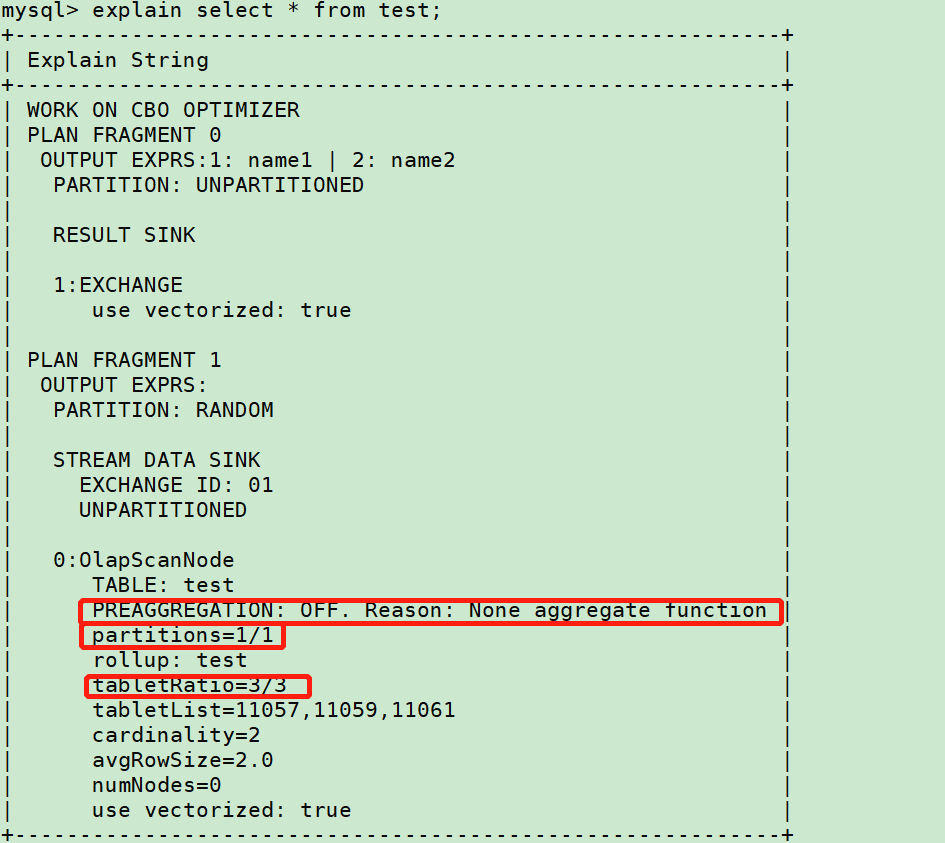
分区分桶
上图中
partitions字段x/xx表示 查询分区/总分区
tabletRatio字段x/xx表示 查询分桶/总分桶
查看对应查询sql是否包含分区字段,是否正确裁剪。如未正常裁剪,确认是否有以下问题:
- 字段类型不一致
- 字段有函数 eg:
date_format('2009-10-04 22:23:00', '%W %M %Y')
存储层聚合
何时需要存储层聚合?
- 聚合表的聚合发⽣在导⼊
- Compaction
- 查询时
PREAGGREGATION 是On 表⽰存储层可以直接返回数据, 存储层⽆需进⾏聚合
PREAGGREGATION 是 OFF 表⽰存储层必须聚合, 可以关注下 OFF的原因是否符合预期
是否命中物化视图
通过执行计划可以看到命中的物化视图的名称以及是否进行了预聚合
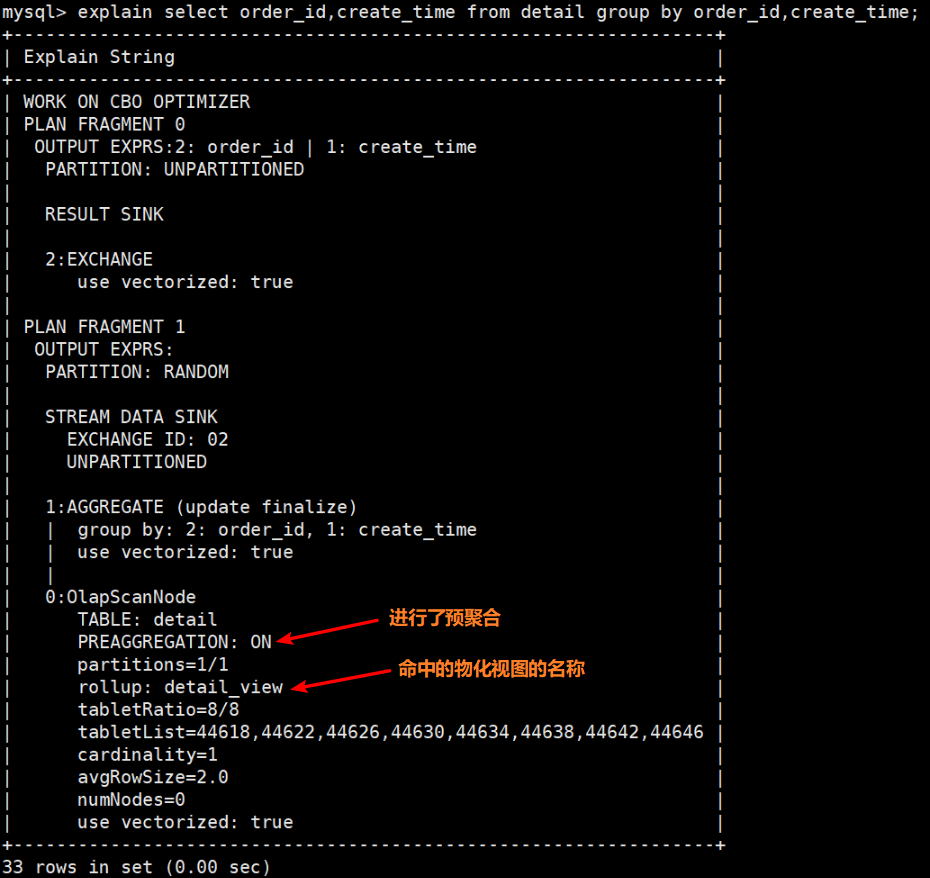
关于pipline Profile
在pipeline执行引擎中,查询的profile的结构如下,总共有五个层级,分别是:
- Fragment
- FragmentInstance
- Pipeline
- PipelineDriver
- Operator
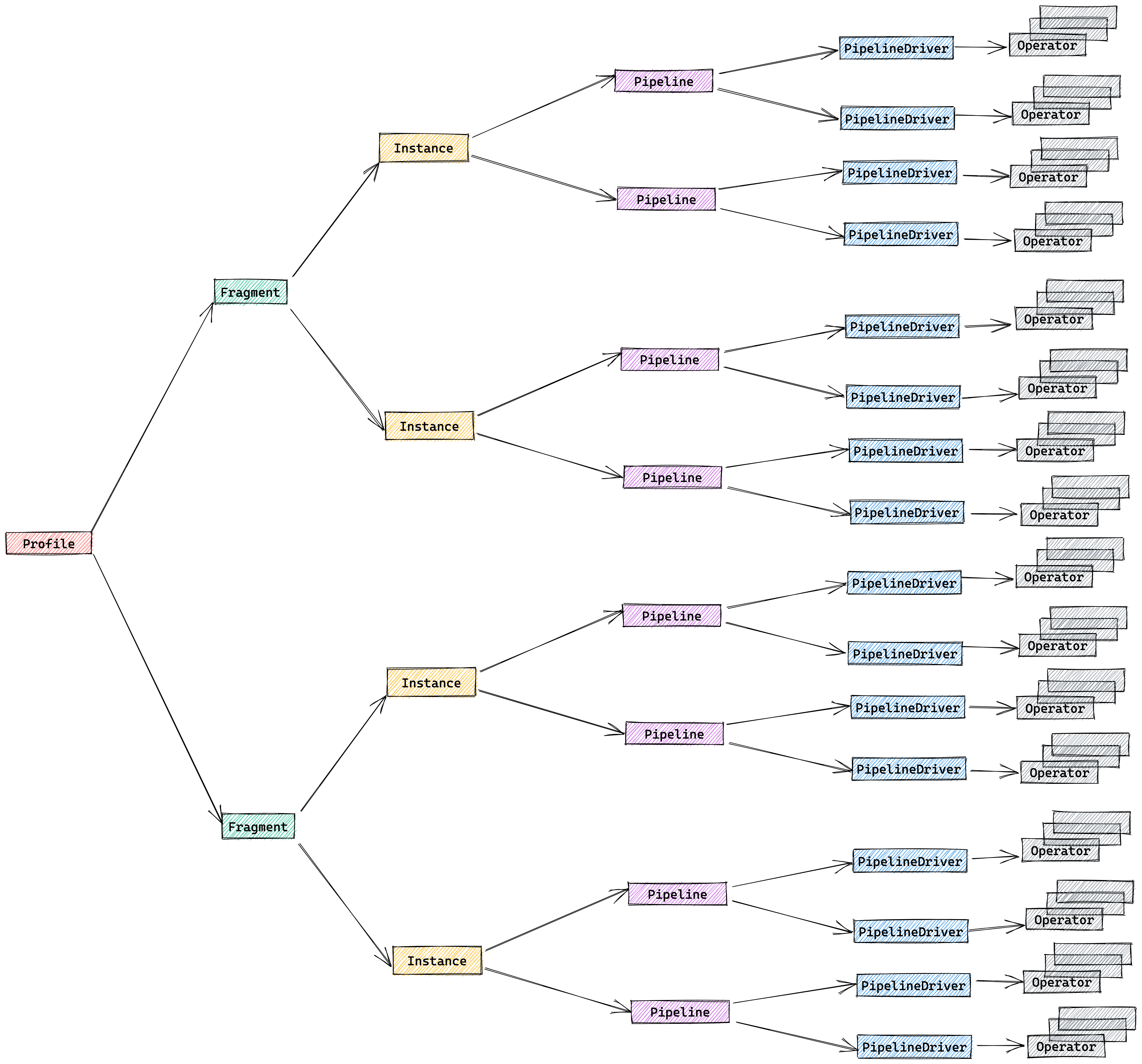
Pipeline的dop自适应策略会保证 FragmentInstance * Dop = 核数的一半 ,对于复杂查询,比如TPC-DS中的查询,其产生的profile多达几十万行,除非借助分析脚本,肉眼很难直接分析
- TPCH Q1的profile如下,大约7000行
暂时无法在文档外展示此内容
因此,profile在2.3版本即pipline默认打开的版本(StarRocks 2.3+)进行了简化处理
- 即压缩profile的整体大小,整个profile的行数最好不好超过100行。对于复杂sql而言,例如tcp-ds,尽量不要超过500行。简化profile的另一个好处是,可以减少BE-FE之间传输的profile的开销
- 对指标进行分类,突出核心指标,方便进行问题排查
- 给出fragment维度的时间线以及pipeline维度的时间线,便于分析fragment之间或者pipeline之间的依赖关系
profile级别
提供新的session变量 pipeline_profile_level ,总共包含3个层级
-
Level 0:合并同构profile,只包含几个核心指标,包括 - 算子维度
1. OperatorTotalTime - Pipeline维度
1. ActiveTime
2. PendingTime
3. DriverTotalTime -
Level 1:合并同构profile,保留所有指标。 默认级别 -
Level 2:保留所有层级的profile,不做任何简化
以TPC-H-Q1为例,分别给出 Level 0 、 Level 1 、 Level 2 三个等级下的profile格式
Level 0
行数:123
level0.txt (4.8 KB)
Level 1
行数:568
level1.txt (22.6 KB)
Level 2
level2.txt (1.0 MB)
暂时无法在文档外展示此内容
核心指标关系图
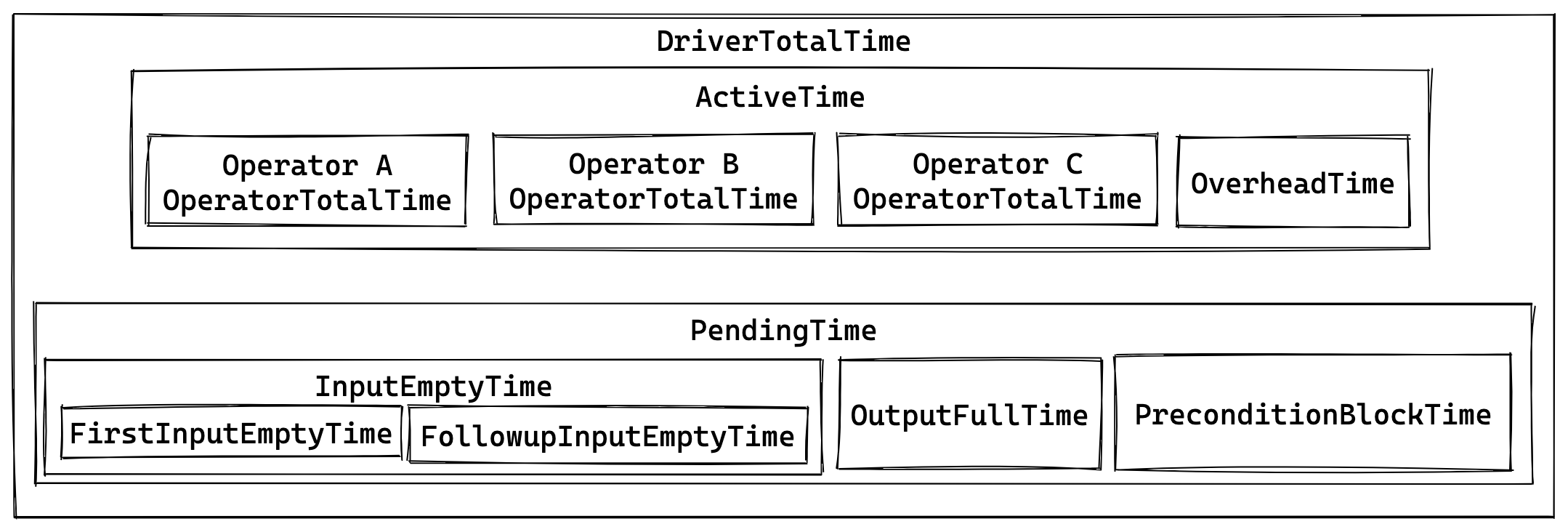
- Pipeline::Active = Σ Operator::OperatorTotalTime + Pipeline::OverheadTime
- InputEmptyTime = FirstInputTime + FollowupInputEmptyTime
- PendingTime = InputEmptyTime + OutputFullTime + PreconditionBlockTime
- DriverTotalTime = ActiveTime + PendingTime
指标含义说明
对于 pipeline_profile_level=0 或 pipeline_profile_leve=1 ,指标会进行合并,合并方式取决于类型
- 时间类型:求平均
- 非时间类型:求和
PS:对于耗时类型的合并操作(求均值),若均值和最大最小值偏差太大,会额外给出该指标的最大值和最小值
- 目前的判断条件是
max - min > 2* avg - 示例如下
... 其他
Pipeline (id=1):
- ActiveTime: 19.221us
- __MAX_OF_ActiveTime: 459.246us
- __MIN_OF_ActiveTime: 1.902us
... 其他
Execution维度
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 指标名称 | 指标含义 |
|---|---|
| ExecutionTotalTime | 执行总耗时,用于计算每个节点的时间占比 |
Fragment维度
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 指标名称 | 指标含义 |
|---|---|
| BackendNum | 参与执行该fragment的be数量 |
| InstanceNum | Fragment Instance 实例的数量 |
| MemoryLimit | 内存限制 |
| PeakMemoryUsage | 峰值内存 |
Pipeline维度
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 二级指标 | 三级指标 | 指标含义 |
|---|---|---|---|
| Pipeline ID | |||
| ActiveTime | Pipeline整个生命周期,占用执行线程的时间 | ||
| Pipeline::ActiveTime = ∑Operator::OperatorTotalTime + OverheadTime | |||
| DegreeOfParallelism | Pipeline的并发度(合并后不会累加) | ||
| TotalDegreeOfParallelism | Pipeline的总并发度(合并后会累加) | ||
| DriverTotalTime | PushRowNum | ||
| LocalRfWaitingSet | |||
| OverheadTime | Pipeline执行框架的开销,包括调用has_output、need_input、is_finished等方法的总耗时 |
计算公式如下:
Pipeline::ActiveTime - ∑Operator::OperatorTotalTime|
|PendingTime|||Pipeline在Pending队列中的时间。可以细分为 InputEmptyTime、OutputFullTime、PreconditionBlockTime
各时间关系如下:
PendingTime = InputEmpty + OutputFullTime + PreconditionBlockTime
InputEmpty = FirstInputEmptyTime + FollowupInputEmptyTime|
||InputEmptyTime||由于输入队列为空导致的等待时间|
|||FirstInputEmptyTime|第一次由于输入队列为空导致的等待的时间。单独把第一次提出来是因为,第一次等待,大概率是由于Pipeline的依赖关系产生的|
|||FollowupInputEmptyTime|后续(第二次开始)所有因为输入队列为空导致的等待的时间|
||OutputFullTime||由于输出队列为空导致的等待时间|
||PreconditionBlockTime||由于Pipeline依赖关系导致的等待时间|
|ScheduleTime|||调度时间。从pending队列中移出,放入就绪队列,并被成功调度的这段时间|
Operator维度
公共指标
td {white-space:pre-wrap;border:1px solid #dee0e3;}| ScanTime | 指标含义 |
|---|---|
| CloseTime | Operator::close 方法的耗时 |
| JoinRuntimeFilterEvaluate | Join Runtime Filter 执行的次数 |
| JoinRuntimeFilterInputRows | Join Runtime Filter 输入的行数 |
| JoinRuntimeFilterOutputRows | Join Runtime Filter 输出的行数 |
| JoinRuntimeFilterTime | Join Runtime Filter 的耗时 |
| OperatorTotalTime | 算子计算耗时(Operator::push_chunk、Operator::pull_chunk) |
| PullChunkNum | 算子输出的总Chunk数 |
| PullRowNum | 算子输出的总行数 |
| PullTotalTime | Operator::pull_chunk 方法的耗时 |
| PushChunkNum | 算子输入的总Chunk数 |
| PushRowNum | 算子输入的总行数 |
| PushTotalTime | Operator::push_chunk 方法的耗时 |
| RuntimeBloomFilterNum | Bloom Filter过滤的行数 |
| RuntimeInFilterNum | In Filter过滤的行数 |
| SetFinishedTime | Operator::set_finished 方法的耗时 |
| SetFinishingTime | Operator::set_finishing 方法的耗时 |
OlapScan
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 二级指标 | 指标含义 |
|---|---|---|
| Table | 表名称 | |
| Predicates | 谓词 | |
| Rollup | ||
| BytesRead | 读入的字节数量 | |
| CachedPagesNum | ||
| CompressedBytesRead | ||
| CreateSegmentIter | ||
| DictDecode | ||
| ScanTime | Scan总耗时(Scan在异步线程中执行,该时间不会体现在算子的OperatorTotalTime中) | |
| IOTime | 执行IO的耗时 | |
| LateMaterialize | ||
| PushdownPredicates | ||
| RawRowsRead | ||
| ReadPagesNum | ||
| SegmentInit | ||
| BitmapIndexFilter | ||
| BitmapIndexFilterRows | ||
| BloomFilterFilterRows | ||
| ShortKeyFilterRows | ||
| ZoneMapIndexFilterRows | ||
| SegmentRead | ||
| BlockFetch | ||
| BlockFetchCount | ||
| BlockSeek | ||
| BlockSeekCount | ||
| ChunkCopy | ||
| DecompressT | ||
| DelVecFilterRows | ||
| IndexLoad | ||
| PredFilter | ||
| PredFilterRows | ||
| RowsetsReadCount | ||
| SegmentsReadCount | ||
| TotalColumnsDataPageCount |
HDFSScan
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| Table | 表名称 |
| BytesReadDataNodeCache | 从DataNode Cache读取数据量 |
| BytesReadFromDisk | 从Disk读取数据量 |
| BytesReadLocal | 从本地DataNode读取数据量 |
| BytesReadRemote | 从远端DataNode读取数据量 |
| BytesReadShortCircuit | 从本地DataNode的本地磁盘读取数据量 |
| BytesTotalRead | 总的读取数据量 |
| ColumnConvertTime | ORC: 读取数据上来拷贝/转换成为Chunk时间 |
| ColumnReadTime | ORC: 读取ORC文件里面Column的时间 |
| ExprFilterTime | 执行表达式谓词过滤时间 |
| GroupChunkRead | Parquet:读取Parquet文件里面Column的时间 |
| GroupDictDecode | Parquet:对Parquet文件里面dict code进行decode |
| GroupDictFilter | Parquet:根据dict code进行过滤 |
| IoCounter | 执行IO的次数 |
| IoTime | 执行IO的时间 |
| LevelDecodeTime | ORC:在Chunk上进行类型转换时间 |
| Parquet:解析Parquet里面Level的时间 | |
| OpenFile | 打开所有HDFS文件的时间 |
| PageReadTime | Parquet: 读取Parquet里面Page的时间 |
| RawRowsRead | 从文件上直接读取出来行数 |
| ReaderInit | Parquet:初始化reader时间 |
| ReaderInitColumnReaderInit | Parquet:初始化column reader时间 |
| ReaderInitFooterRead | Parquet:初始化footer reader时间 |
| RowsReturned | 向上返回chunk的行数(多个scanner并行执行) |
| RowsReturnedRate | 向上返回chunk的速率(多个scanner并行执行) |
| ScanTime | 单个scanner执行get_next的耗时 |
| ValueDecodeTime | ORC: 原始数据拷贝到Chunk时间 |
| Parquet:解析Parquet里面Value的时间 |
上面许多指标都有更新,比较重要的一级指标有下面这些
| 指标 | 含义 | |
|---|---|---|
| 1 | Table | 表名 |
| 2 | Predicates | 相关谓词 |
| 3 | BytesRead | 读取数据总量 |
| 4 | IoCounter | IO累计次数 |
| 5 | IoTime | IO累计时间 |
| 6 | RowsRead | 读取记录条数 |
| 7 | RowsReturned | 返回记录条数 |
| 8 | ScanFiles | 扫描文件数量 |
| 9 | ScanRanges | 扫描文件切片数量 |
| 10 | ScanTime | 扫描时间 |
profile常见如下格式:
- Table: lineitem
- Predicates: 11: l_shipdate <= '1998-12-01'
- PredicatesMinMax: 27: l_shipdate <= '1998-12-01'
- PredicatesPartition:
- BytesRead: 719.75 MB
- ColumnConvertTime: 2s775ms
- ColumnReadTime: 58s850ms
- ExprFilterTime: 58.503ms
- IoCounter: 1.468K (1468)
- IoTime: 58s120ms
- NumDiskAccess: 0
- OpenFile: 25.288us
- PeakMemoryUsage: 0.00
- ReaderInit: 9s306ms
- RowsRead: 74.081656M (74081656)
- RowsReturned: 74.081656M (74081656)
- RowsReturnedRate: 25.511989M /sec
- ScanFiles: 38
- ScanRanges: 38
- ScanTime: 1m1s
- ScannerQueueCounter: 9.76K (9760)
- ScannerQueueTime: 3m29s
- TotalReadThroughput: 98.29647254943848 MB/sec
Exchange
无法复制加载中的内容
Aggregate
无法复制加载中的内容
Join
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| HashJoinBuild | |
| JoinPredicates | |
| JoinType | |
| BuildBuckets | |
| BuildConjunctEvaluateTime | |
| BuildHashTableTime | |
| CopyRightTableChunkTime | |
| RuntimeFilterBuildTime | |
| RuntimeFilterNum | |
| HashJoinProbe | |
| OtherJoinConjunctEvaluateTime | |
| OutputBuildColumnTimer | |
| OutputProbeColumnTimer | |
| OutputTupleColumnTimer | |
| ProbeConjunctEvaluateTime | |
| SearchHashTableTimer | |
| WhereConjunctEvaluateTime | |
| CrossJoinLeft(无) | |
| CrossJoinRight(无) |
Window
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| ComputeTime | 窗口计算耗时 |
| PartitionKeys | 分区列 |
| AggregateFunctions | 聚合函数 |
| RowsReturned | PullRowNum |
Sort
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| BuildingTime | |
| SortingTime | |
| MergingTime | |
| OutputTime | |
| SortKeys | 排序键 |
| SortType | All or TopN |
| SortFilterCost | |
| SortFilterRows |
TableFunction
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| TableFunctionTime | Table Function的计算耗时 |
LocalExchange
td {white-space:pre-wrap;border:1px solid #dee0e3;}| 一级指标 | 指标含义 |
|---|---|
| Type | 类型,可选值包括 Passthrough / Partition / Broadcast |
SCAN环节分析及优化
再porifle中搜索OLAP_SCAN,如下是一个典型的scan慢节点。
OLAP_SCAN (plan_node_id=0):
CommonMetrics:
- CloseTime: 362.301us
- OperatorTotalTime: 4s952ms
- __MAX_OF_OperatorTotalTime: 7s914ms
- __MIN_OF_OperatorTotalTime: 1s140ms
- PeakMemoryUsage: 0.00
- PullChunkNum: 1.466019M (1466019)
- PullRowNum: 5.999989425B (5999989425)
- PullTotalTime: 4s952ms
- __MAX_OF_PullTotalTime: 7s914ms
- __MIN_OF_PullTotalTime: 1s140ms
- PushChunkNum: 0
- PushRowNum: 0
- PushTotalTime: 0ns
- SetFinishedTime: 353ns
- SetFinishingTime: 115ns
UniqueMetrics:
- Rollup: lineitem
- Table: lineitem
- BytesRead: 0.00
- CachedPagesNum: 0
- CompressedBytesRead: 2.25 GB
- CreateSegmentIter: 44.855us
- IOTime: 6s382ms
- __MAX_OF_IOTime: 8s361ms
- __MIN_OF_IOTime: 4s759ms
- PushdownPredicates: 0
- RawRowsRead: 5.999989425B (5999989425)
- ReadPagesNum: 366.588K (366588)
- RowsRead: 5.999989425B (5999989425)
- ScanTime: 7s917ms
- __MAX_OF_ScanTime: 10s725ms
- __MIN_OF_ScanTime: 2s67ms
- SegmentInit: 1s220ms
- BitmapIndexFilter: 0ns
- BitmapIndexFilterRows: 0
- BloomFilterFilterRows: 0
- ShortKeyFilterRows: 0
- ZoneMapIndexFilterRows: 0
- __MAX_OF_SegmentInit: 2s30ms
- __MIN_OF_SegmentInit: 722.290ms
- SegmentRead: 6s684ms
- BlockFetch: 56.340ms
- __MAX_OF_BlockFetch: 71.932ms
- __MIN_OF_BlockFetch: 40.425ms
- BlockFetchCount: 1.465127M (1465127)
- BlockSeek: 6s623ms
- __MAX_OF_BlockSeek: 8s616ms
- __MIN_OF_BlockSeek: 4s967ms
- BlockSeekCount: 1.465127M (1465127)
- ChunkCopy: 0ns
- DecompressT: 0ns
- DelVecFilterRows: 0
- IndexLoad: 0ns
- PredFilter: 0ns
- PredFilterRows: 0
- RowsetsReadCount: 397
- __MAX_OF_RowsetsReadCount: 25
- __MIN_OF_RowsetsReadCount: 3
- SegmentsReadCount: 1.069K (1069)
- TotalColumnsDataPageCount: 366.588K (366588)
- __MAX_OF_SegmentRead: 8s681ms
- __MIN_OF_SegmentRead: 5s26ms
- UncompressedBytesRead: 2.24 GB
其中Table =x可以看到对应的所扫描的表名信息。
数据倾斜问题
查看某表OLAP_SCAN部分的profile,如上所示,观察 ScanTime 子节点
是否该OLAP_SCAN节点的 MAX_OF_ScanTime 和 MIN_OF_ScanTime 差距很大,如果存在个别节点耗时是其他节点数据量倍数,
例如:
- ScanTime: 7s917ms
- __MAX_OF_ScanTime: 10s725ms
- __MIN_OF_ScanTime: 2s67ms
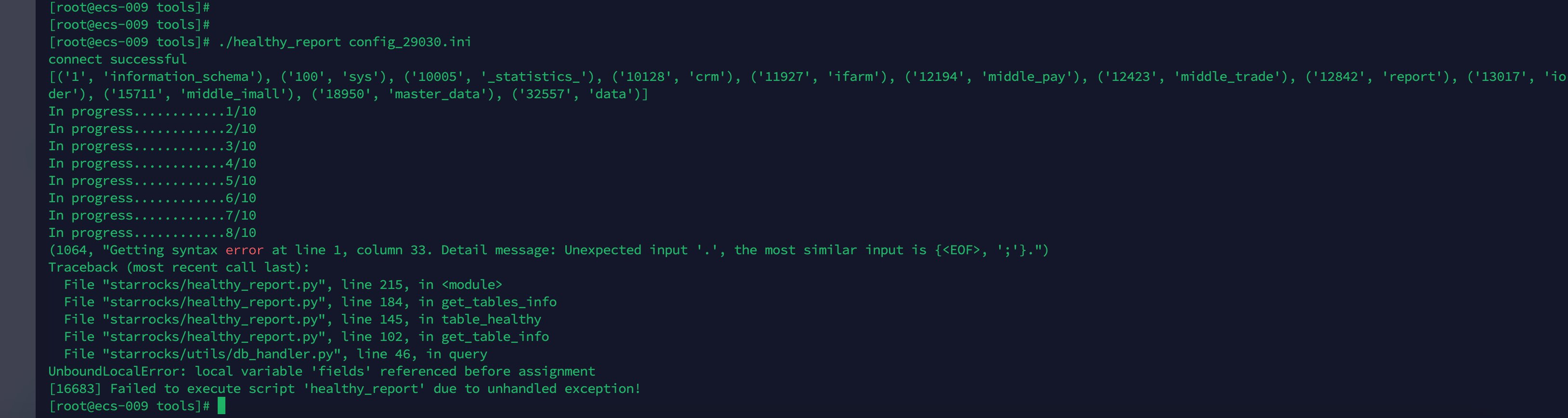
则有数据倾斜的问题。可以运行一下tabelt分析工具。
https://starrocks-public.oss-cn-zhangjiakou.aliyuncs.com/tools-20230413.tar.gz
下载完成后编辑config.ini信息,然后执行
./healthy_report config.ini
暂时无法在文档外展示此内容
可以获取以下信息:
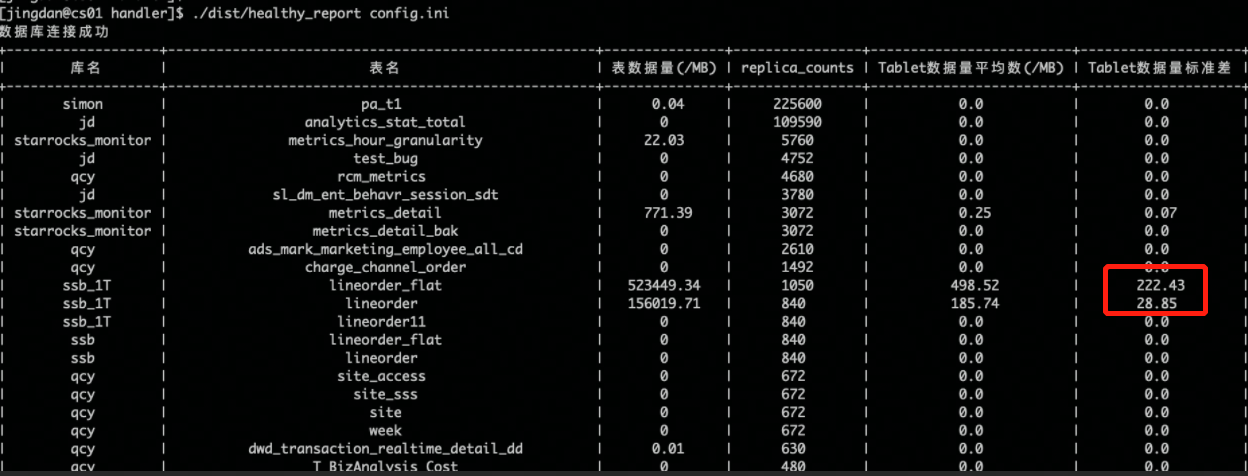
以上信息中关注下标准差那列,如果异常高,则表示该表需要重新选取hash键,建表不合理有严重的数据倾斜问题。
除此还可以关注下tablet数据平均值是否合理,一般建议该值在100MB-1GB之间,对于表总体数据量比较小时可以容忍小一点,数据量大的表建议在1G左右,如果该值与建议值差异较大,可以适当调整建表语句的bucket数量大小。
关键指标解读
以下对scan的关键指标做一些解读,如果对应字段的值占比总查询时间很高,可以针对该阶段进行分析。
- BytesRead
读取tablet数据量大小,该值太大或者太小表示tablet设置的均不合理,可以参考视频内容,简单说明了分桶数的作用以及使用注意事项:
https://www.bilibili.com/video/BV1SX4y1c7i4?p=2
- RowsReturned
扫描返回符合要求的行数,如果BytesRead很大,而RowsReturned很小。但是scan占比挺久,可以考虑将过滤条件中的字段建表时设置为key列,对点查效果有很好的加速效果,关于排序列的使用可以参考以下内容:
https://www.bilibili.com/video/BV1SX4y1c7i4?p=1
- MergingTime
如果mergingtime比较大,如下:
UniqueMetrics:
- SortKeys: 1: c_custkey ASC
- SortType: TopN
- BuildingTime: 4.905ms
- MergingTime: 4s154ms
- OutputTime: 5s123s
- SortFilterCost: 4.316ms
- SortFilterRows: 29.950848M (29950848)
- SortingTime: 0ns
该问题常见于unique表和aggregate表,在于内部存在多个rowset没有合并,导致查询时内部需要做相应操作,从而影响结果集输出。可以通过以下步骤去排查rowset是否太多:
Show tablet from table\G
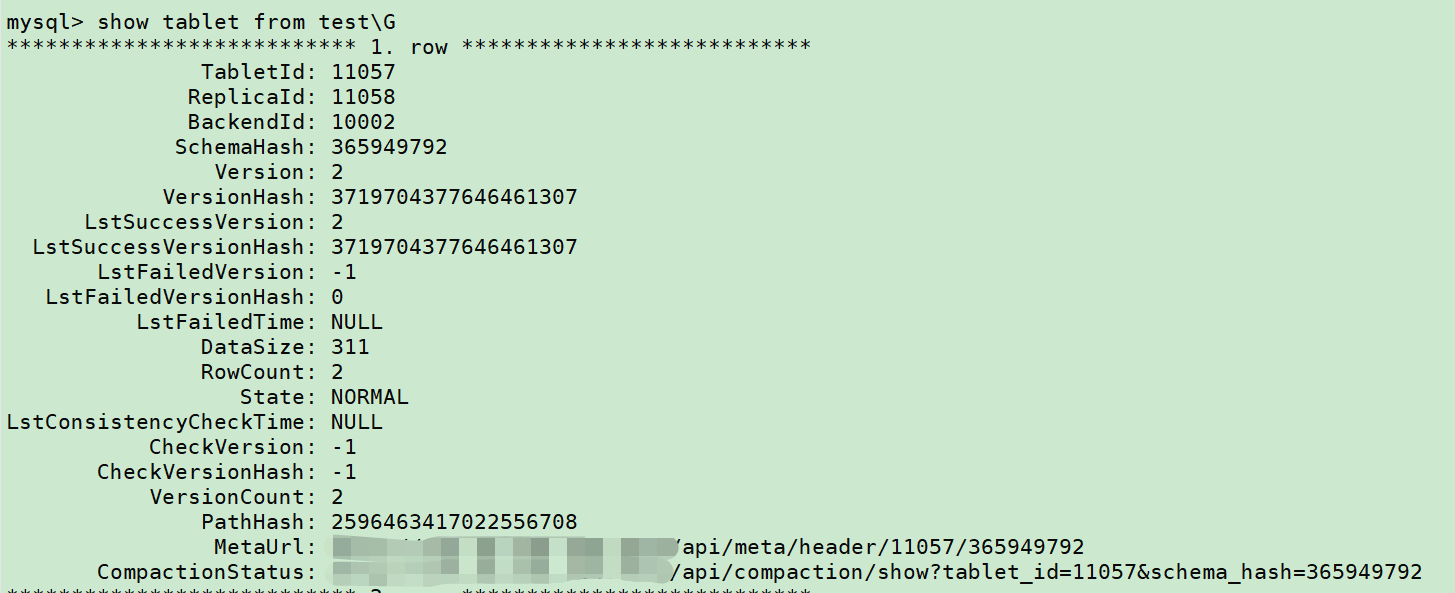
找到version比较大的tablet,此处举例取11057,接着
Show tablet 11057\G
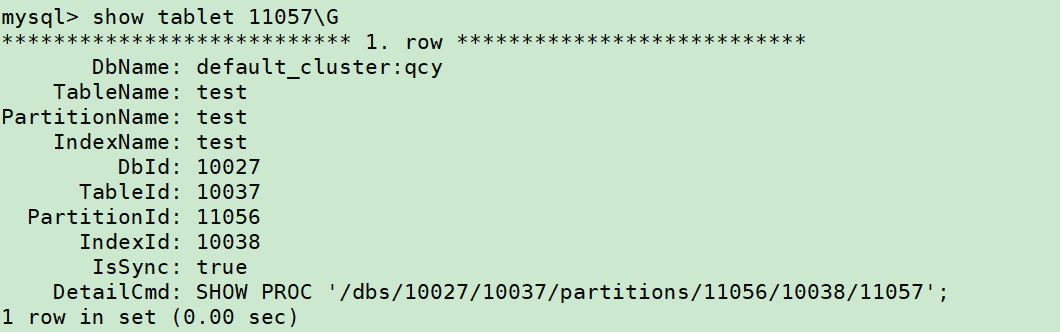
可以用 「DetailCmd」的命令,来进一步展示详细信息:
SHOW PROC '/dbs/10027/10037/partitions/11056/10038/11057'\G
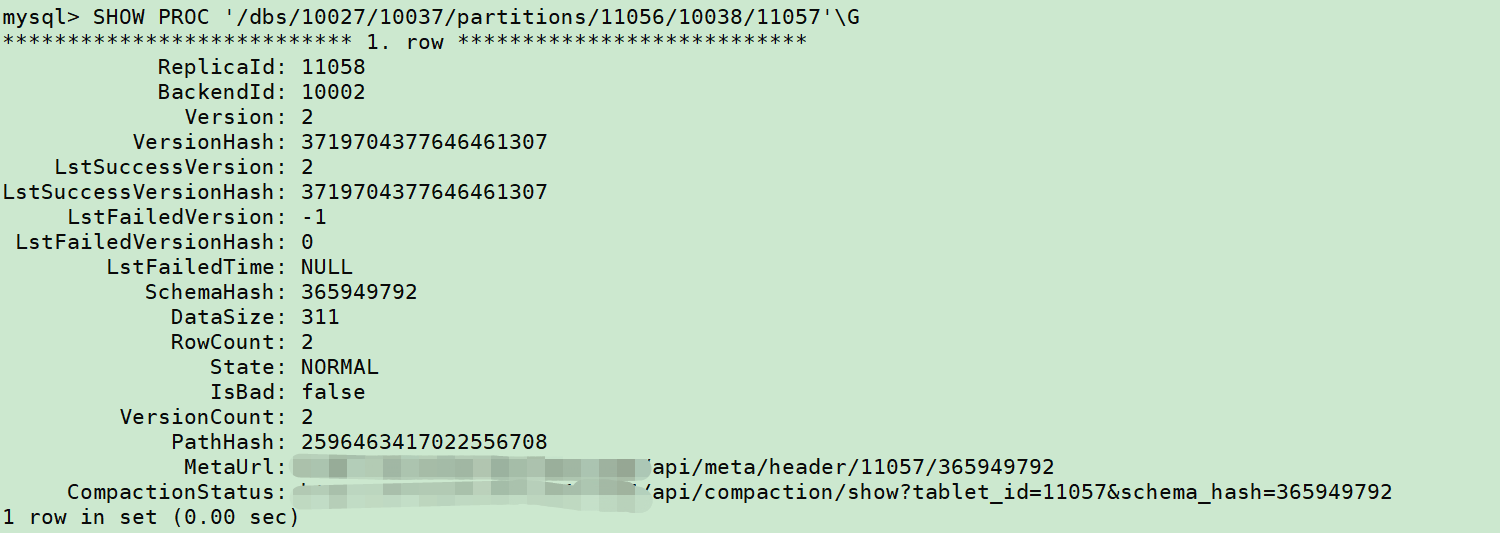
访问「CompactionStatus」中的 URL,会展示分片的几个副本(replica)的具体信息,包括可以查看每个副本更多元数据信息。
会出现如下信息:
{
"cumulative point": 40716,
"last cumulative failure time": "2021-05-28 14:28:07.695",
"last base failure time": "1970-01-01 08:00:00.000",
"last cumulative success time": "2021-05-27 18:30:59.385",
"last base success time": "2021-05-27 18:30:59.385",
"rowsets": [
"[0-40603] 1 DATA NONOVERLAPPING",
"[40604-40635] 0 DATA NONOVERLAPPING",
"[40636-40674] 1 DATA NONOVERLAPPING",
"[40675-40715] 0 DATA NONOVERLAPPING"
],
"stale version path": []
}
此处有4个rowset说明数据还没充分做compaction。(其中 NONOVERLAPPING 只是表示一个 rowset 内部,如果有多个 segment 时,是否有重叠部分)。
可以通过修改 BE 的 conf/be.conf 中的配置,加快 compaction,以减少版本数:
# 加快做 cumulative compaction 的检查,能减少版本数(rowset 的数量)
cumulative_compaction_check_interval_seconds = 2
cumulative_compaction_num_threads_per_disk = 2
base_compaction_num_threads_per_disk = 2
如果想要进一步合并 2 个 rowset 为 1 个 rowset,可以做如下配置,但一般不建议,因为会导致增加大量 base compaction。
# Cumulative文件数目要达到设定数值,就进行 base compaction
base_compaction_num_cumulative_deltas = 1
注:聚合和更新表key列过多时,会极大影响merge时间,可以根据业务合适选取key列,如果必要的key列实在很多,可以考虑以下几种方案:
- 聚合表可以考虑用明细表+物化视图替代
- 更新表如果符合主键模型的场景,可以使用主键模型替代,详情参考文档主键模型使用部分内容:https://docs.starrocks.com/zh-cn/main/table_design/Data_model#主键模型
- IOTime
磁盘io所用时间,和上述MERGE和RowsReturnedRate有关,排查见如上所示。
注:如果有谓词下推异常或者分区分桶裁剪不正常的情况可以检查是否包含以下问题:
- 字段类型不一致
- 过滤条件中左边字段有函数 eg:
date_format('2009-10-04 22:23:00', '%W %M %Y')
JOIN环节分析及优化
名词解释
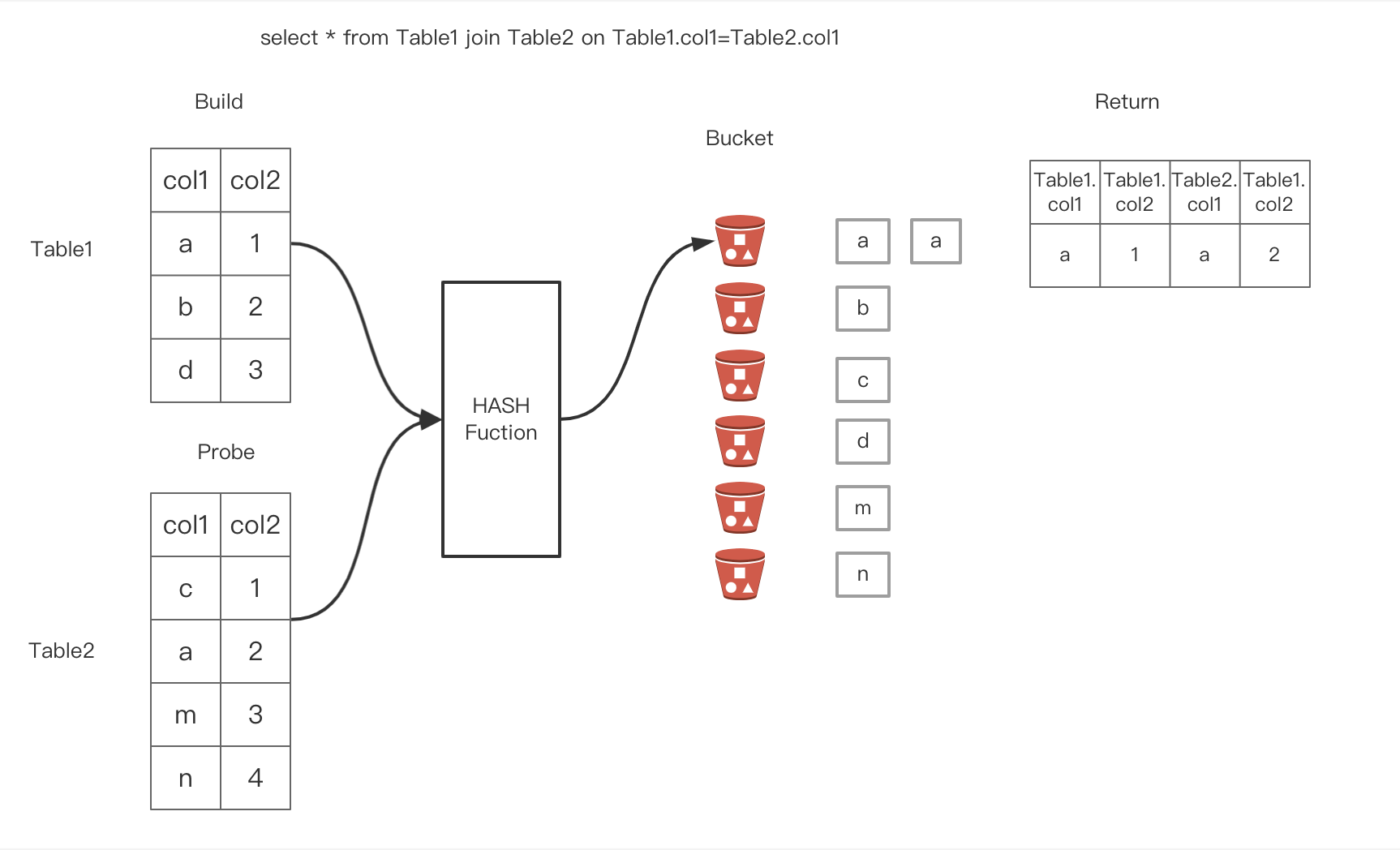
关于HashJoin :两个阶段,Build+Probe
Build阶段 :将其中一个表(一般是较小的那个)中的每一个条经过 Hash 函数的计算都放到不同的Hash Bucket中。
Probe阶段 :对于另外一个表,经过Hash函数,确定其所在的Hash Bucket,然后和上一步构建的Hash Bucket中的每一行进行匹配,如果匹配到就返回对应的行。
如下图所示两个表经过Hash join之后应该返回的分别是第1和第2行。
Join 左右表调整 : StarRocks 是用右表构建 Hash 表,所以右表应该是小表,StarRocks 可以基于 cost 自动调整左右表顺序,也会自动把 left join 转 right join。
Join 多表 Reorder :多表Join 如何选择出正确的Join 顺序,是 CBO 优化器的核心,当 Join 表的数量小于等于5时,StarRocks 会基于 Join 交换律和结合律进行 Join Reorder,大于5时,StarRocks 会基于贪心算法和动态规划进行 Join Reorder。
Join分布式执行选择 :
- BroadCast Join:将右表全量发送到左表的HashJoinNode
- Shuffle Join:将左右表的数据根据哈希计算分散到集群的节点之中
- Colocate Join:两个表的数据分布都是一样的,只需要本地join即可,没有网络传输开销。
- Bucket Shuffle Join:join的列是左表的数据分布列(分桶键),所以相比于shuffle join只需要将右表的数据发送到左表数据存储计算节点。
- Replicated Join:右表的全量数据是分布在每个节点上的(也就是副本个数和BE节点数量一致),不管左表怎么分布,都是走本地Join。没有网络传输开销。
RunetimeFilter: 基本原理是通过在join操作之前提前过滤掉那些不会命中join的输入数据来大幅减少join中的数据传输和计算,从而减少整体的执行时间。
注:下图是企业版profile可视化界面
Join节点的Profile
Pipeline (id=0):
- LocalRfWaitingSet: 1
- ActiveTime: 32.155us
- BlockByInputEmpty: 1
- __MAX_OF_BlockByInputEmpty: 1
- __MIN_OF_BlockByInputEmpty: 0
- BlockByOutputFull: 0
- BlockByPrecondition: 0
- DegreeOfParallelism: 1
- DriverTotalTime: 314.142ms
- __MAX_OF_DriverTotalTime: 512.989ms
- __MIN_OF_DriverTotalTime: 114.675ms
- OverheadTime: 32.155us
- PendingTime: 313.653ms
- InputEmptyTime: 8.143ms
- FirstInputEmptyTime: 8.143ms
- __MAX_OF_FirstInputEmptyTime: 97.716ms
- __MIN_OF_FirstInputEmptyTime: 0ns
- FollowupInputEmptyTime: 0ns
- __MAX_OF_InputEmptyTime: 97.716ms
- __MIN_OF_InputEmptyTime: 0ns
- OutputFullTime: 0ns
- PendingFinishTime: 0ns
- PreconditionBlockTime: 305.511ms
- __MAX_OF_PreconditionBlockTime: 418.213ms
- __MIN_OF_PreconditionBlockTime: 114.207ms
- __MAX_OF_PendingTime: 511.889ms
- __MIN_OF_PendingTime: 114.206ms
- ScheduleCount: 13
- ScheduleTime: 456.371us
- TotalDegreeOfParallelism: 12
- YieldByTimeLimit: 0
LOCAL_EXCHANGE_SINK (pseudo_plan_node_id=-100):
CommonMetrics:
- CloseTime: 533ns
- OperatorTotalTime: 1.426us
- PeakMemoryUsage: 0.00
- PullChunkNum: 0
- PullRowNum: 0
- PullTotalTime: 0ns
- PushChunkNum: 1
- __MAX_OF_PushChunkNum: 1
- __MIN_OF_PushChunkNum: 0
- PushRowNum: 1
- __MAX_OF_PushRowNum: 1
- __MIN_OF_PushRowNum: 0
- PushTotalTime: 582ns
- SetFinishedTime: 32ns
- SetFinishingTime: 279ns
UniqueMetrics:
- Type: Partition
OLAP_SCAN (plan_node_id=0):
CommonMetrics:
- CloseTime: 50.783us
- JoinRuntimeFilterEvaluate: 1
- JoinRuntimeFilterInputRows: 1
- JoinRuntimeFilterOutputRows: 1
- JoinRuntimeFilterTime: 12.480us
- OperatorTotalTime: 74.359us
- PeakMemoryUsage: 0.00
- PullChunkNum: 3
- __MAX_OF_PullChunkNum: 3
- __MIN_OF_PullChunkNum: 0
- PullRowNum: 1
- __MAX_OF_PullRowNum: 1
- __MIN_OF_PullRowNum: 0
- PullTotalTime: 23.222us
- PushChunkNum: 0
- PushRowNum: 0
- PushTotalTime: 0ns
- RuntimeBloomFilterNum: 1
- SetFinishedTime: 104ns
- SetFinishingTime: 249ns
UniqueMetrics:
- BitmapIndexFilter: 0ns
- BitmapIndexFilterRows: 0
- BlockFetch: 13.815us
- BlockFetchCount: 5
- BlockSeek: 68.837us
- BlockSeekCount: 5
- BloomFilterFilterRows: 0
- BytesRead: 0.00
- CachedPagesNum: 0
- ChunkCopy: 1.938us
- CompressedBytesRead: 209.29 KB
- CreateSegmentIter: 38.965us
- DecompressT: 111.629us
- DelVecFilterRows: 0
- IOTime: 93.659us
- IndexLoad: 0ns
- LateMaterialize: 446.149us
- PredFilter: 3.675us
- PredFilterRows: 16.383K (16383)
- RawRowsRead: 16.384K (16384)
- ReadPagesNum: 12
- RowsRead: 1
- RowsetsReadCount: 2
- ScanTime: 95.642ms
- SegmentInit: 95.65ms
- SegmentRead: 94.188us
- SegmentsReadCount: 1
- ShortKeyFilterRows: 0
- TotalColumnsDataPageCount: 3.055K (3055)
- UncompressedBytesRead: 256.83 KB
- ZoneMapIndexFilterRows: 2.483994M (2483994)
当满足RuntimeFilter的条件时,会触发Runtime Filter下推到左表,达到提前过滤。可以关注下左表 OLAP_SCAN_NODE 节点是否有“JoinRuntimeFilter”关键字
OLAP_SCAN (plan_node_id=0):
CommonMetrics:
- CloseTime: 50.783us
- JoinRuntimeFilterEvaluate: 1
- JoinRuntimeFilterInputRows: 1
- JoinRuntimeFilterOutputRows: 1
- JoinRuntimeFilterTime: 12.480us
- OperatorTotalTime: 74.359us
- PeakMemoryUsage: 0.00
- PullChunkNum: 3
- __MAX_OF_PullChunkNum: 3
- __MIN_OF_PullChunkNum: 0
- PullRowNum: 1
- __MAX_OF_PullRowNum: 1
- __MIN_OF_PullRowNum: 0
- PullTotalTime: 23.222us
- PushChunkNum: 0
- PushRowNum: 0
- PushTotalTime: 0ns
- RuntimeBloomFilterNum: 1
- SetFinishedTime: 104ns
- SetFinishingTime: 249ns
执行计划:explain + sql
HASH JOIN |
join op: INNER JOIN (BROADCAST) |
hash predicates: |
colocate: false, reason: |
equal join conjunct: 3: lo_custkey = 35: c_custkey |
use vectorized: true
分析和优化
是否有收集统计信息?
1.19.0及其之后的版本默认开启了cbo,之前的版本如果没有开启cbo,可能就会没有统计信息
如果下面的sql有查询结果,表示有统计信息收集(table_name为参与join的表名)。如果没有查询结果,可参考analyze命令手动触发统计信息收集
select * from _statistics_.table_statistic_v1 where table_name like '%table_name';
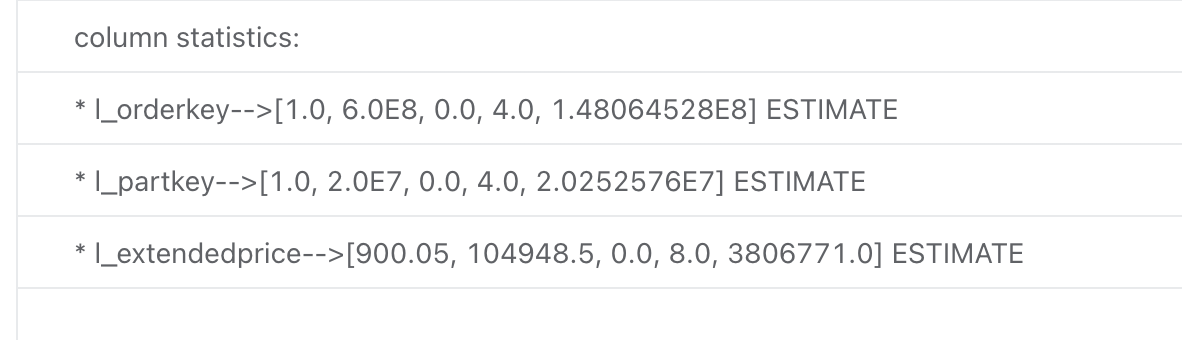
explain costs + sql
不合理:各个列的数据是默认值0.0,1.0等

合理:有统计信息输出
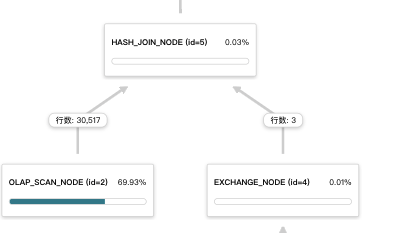
怎么判断瓶颈点?
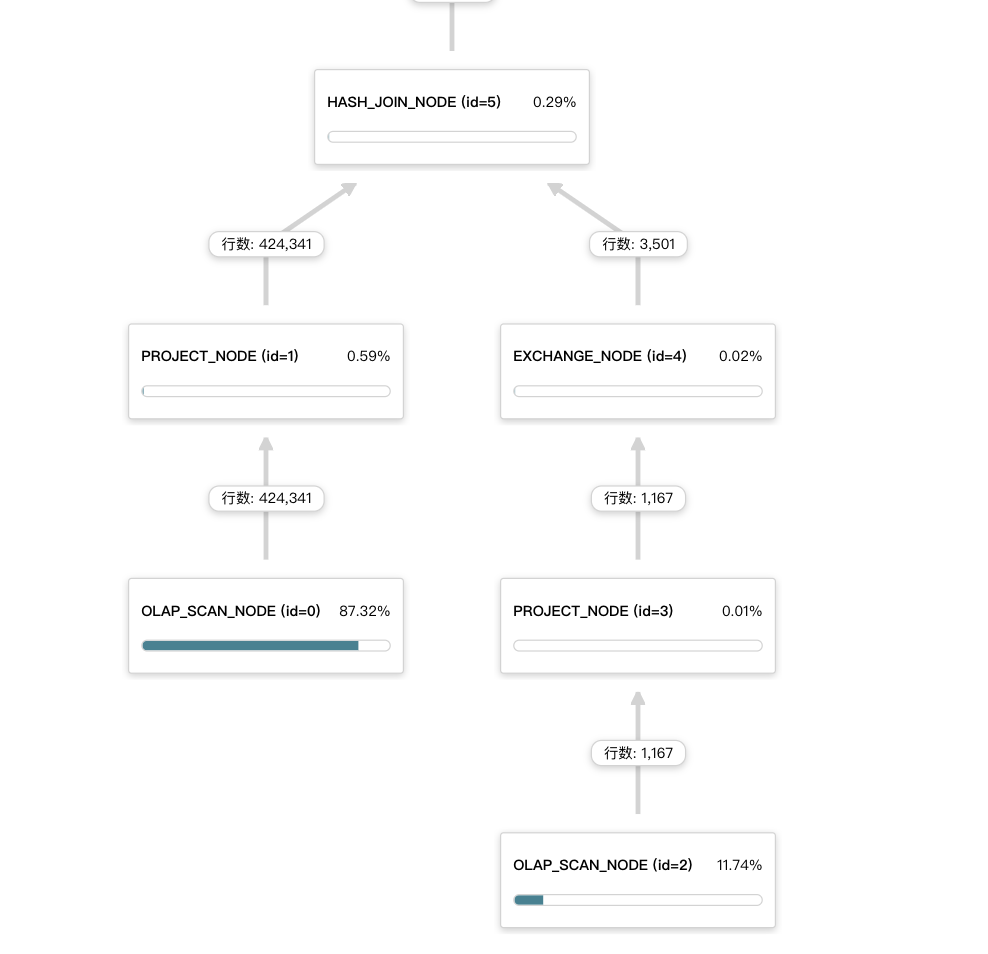
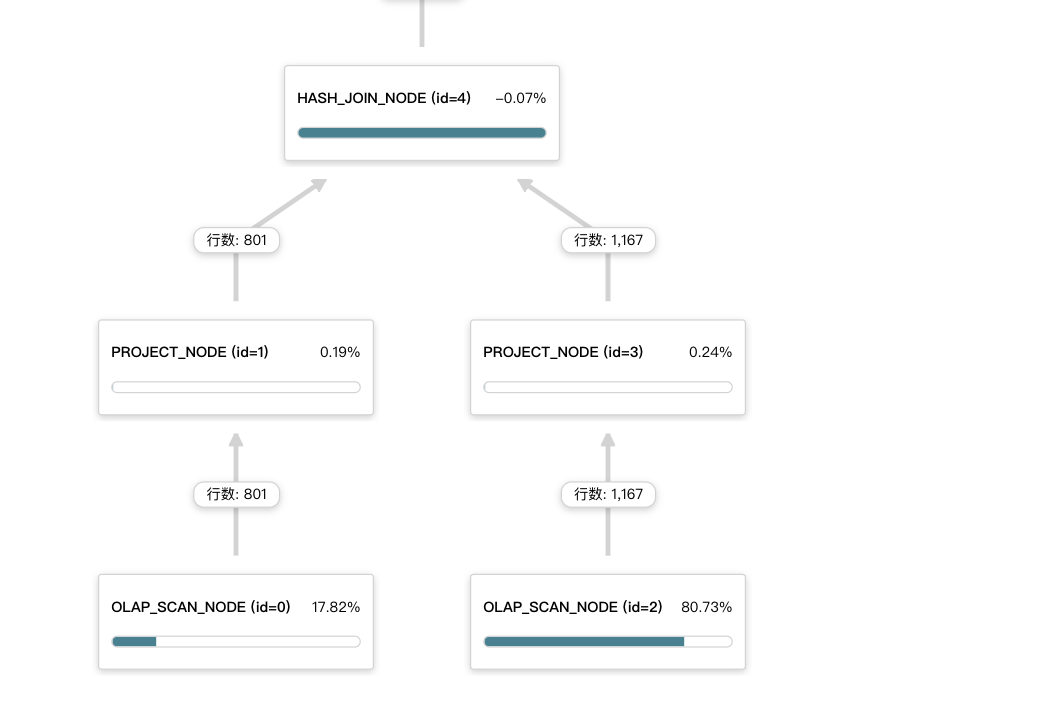
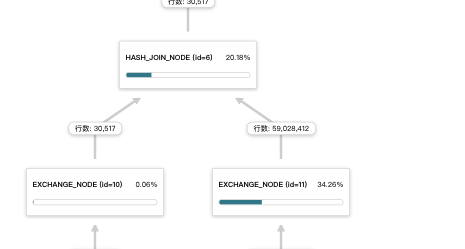
下图表示的是合理的方式,右表是小表,采用的broadcast join方式。
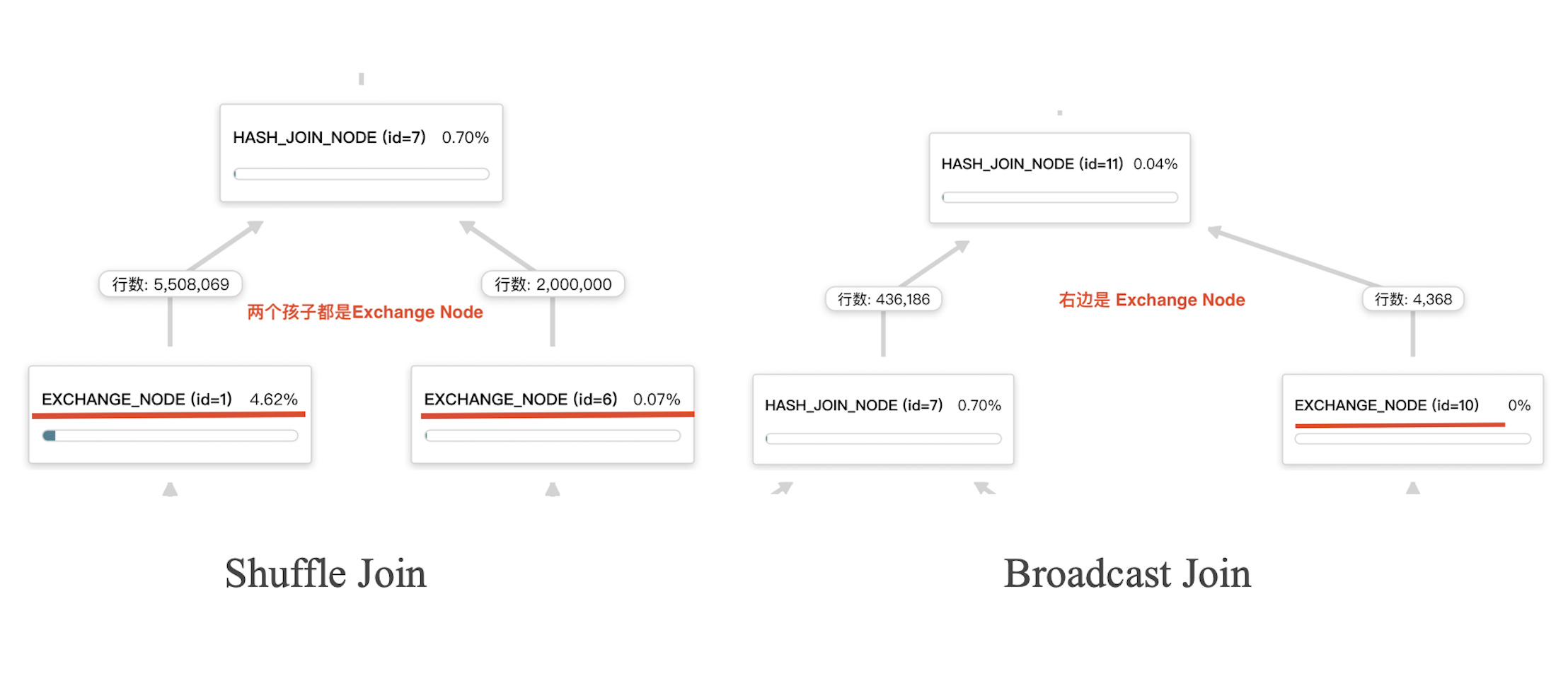
下图表示的是不合理的方式,右表是大表,采用的broadcast join方式,会将右表的数据拷贝 BE 数量* parallel_fragment_exec_instance_num (并行度)份,导致 JOIN 节点的右子节点的 EXCHANGE 节点花费很多的执行时间。
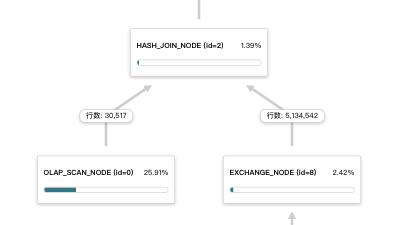
下图表示的是不合理的方式,两个表数据量相差比较大,现在采用的是shuffle join(两个孩子节点都是EXCHANGE NODE),这种情况下建议可以尝试采用broadcast join,调整下左右表顺序,小表在左边。例如加hint方式:
select 右表.x,左表.y from 右表 join [broadcast] 左表 on 左表.x1 = 右表.x1
常见优化方法
当前启用了CBO优化器,一般情况下不需要人为触发优化,不过在一些场景下可以采用下面的方法尝试优化下:
- join condition 的列,更应该使用 int、DATE 等简单类型
- 在join之前尽量添加一些where条件,能够充分发挥谓词下推,减少后续的数据shuffle和join节点处理的数据量
- 大表join,能够使用colocate join的尽量使用,能够减少网络传输,极大的提升性能,具体请参考Colocate Join
- 大小表join,左右表顺序有问题,可以通过[broadcast] hint方式调整小表为右表方式。例如:select a.x,b.y from a join [broadcast] b on a.x1 = b.x1
- 两个相差不多的表(一般几百k行)join,有些情况下默认会选用broadcast join,这个时候可以尝试采用[shuffle] hint的方式强制走shuffle join。例如:select a.x,b.y from a join [shuffle] b on a.x1 = b.x1