【详述】由于阿里云ECS的物理机CPU问题,导致ECS服务器重启,这台ECS上面的tablet查询报错,所以从凌晨0点10分执行的 ```
ALTER SYSTEM DECOMMISSION backend “be_host:be_heartbeat_service_port”;
【StarRocks版本】例如:2.3.4

【详述】由于阿里云ECS的物理机CPU问题,导致ECS服务器重启,这台ECS上面的tablet查询报错,所以从凌晨0点10分执行的 ```
ALTER SYSTEM DECOMMISSION backend “be_host:be_heartbeat_service_port”;
【StarRocks版本】例如:2.3.4
tablet从7万多下降到192用了2个小时,到了凌晨3点时候剩下192个,直到现在13:18分的时候还剩下140个,请问下怎么才能让其快速结束,我现在执行 ```
ALTER SYSTEM DROP backend
现在执行ALTER SYSTEM DROP backend 会让其快速结束吗?会产生什么别的影响?
麻烦去fe master节点 fe.log日志里面搜下Decommission关键字结果发出来,我们分析下原因.然后您先尝试CANCEL DECOMMISSION 等tabletnum上涨的时候 再执行ALTER SYSTEM DECOMMISSION 的命令 重新调度下是否可以
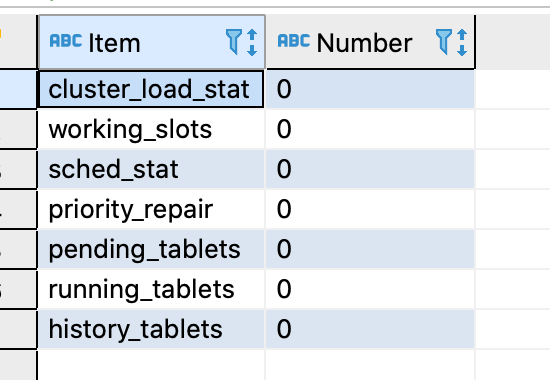
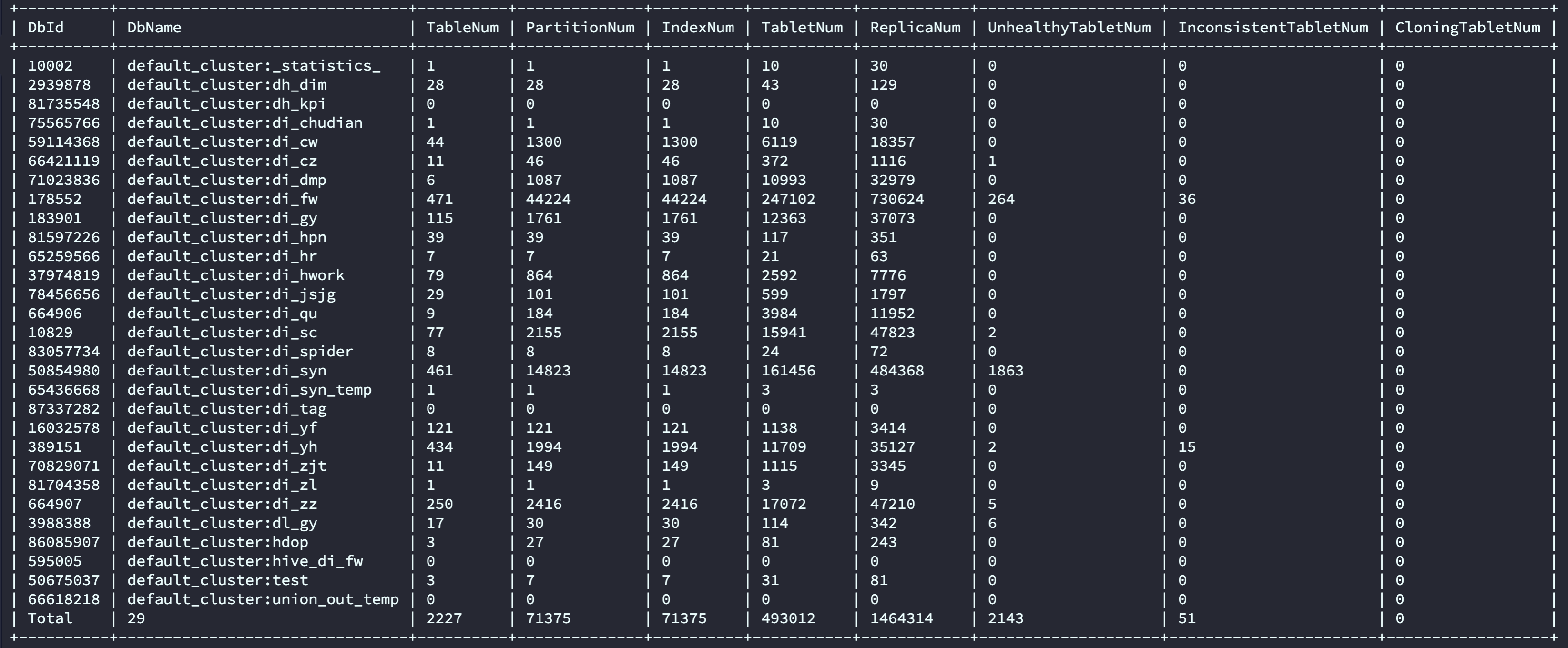
请问show proc “/cluster_balance” 这个是在master fe看的吗?
OK 请问目前下线成功了吗?麻烦在昨天fe.log里面搜下Decommission关键字把日志发出来,我们排查下原因.
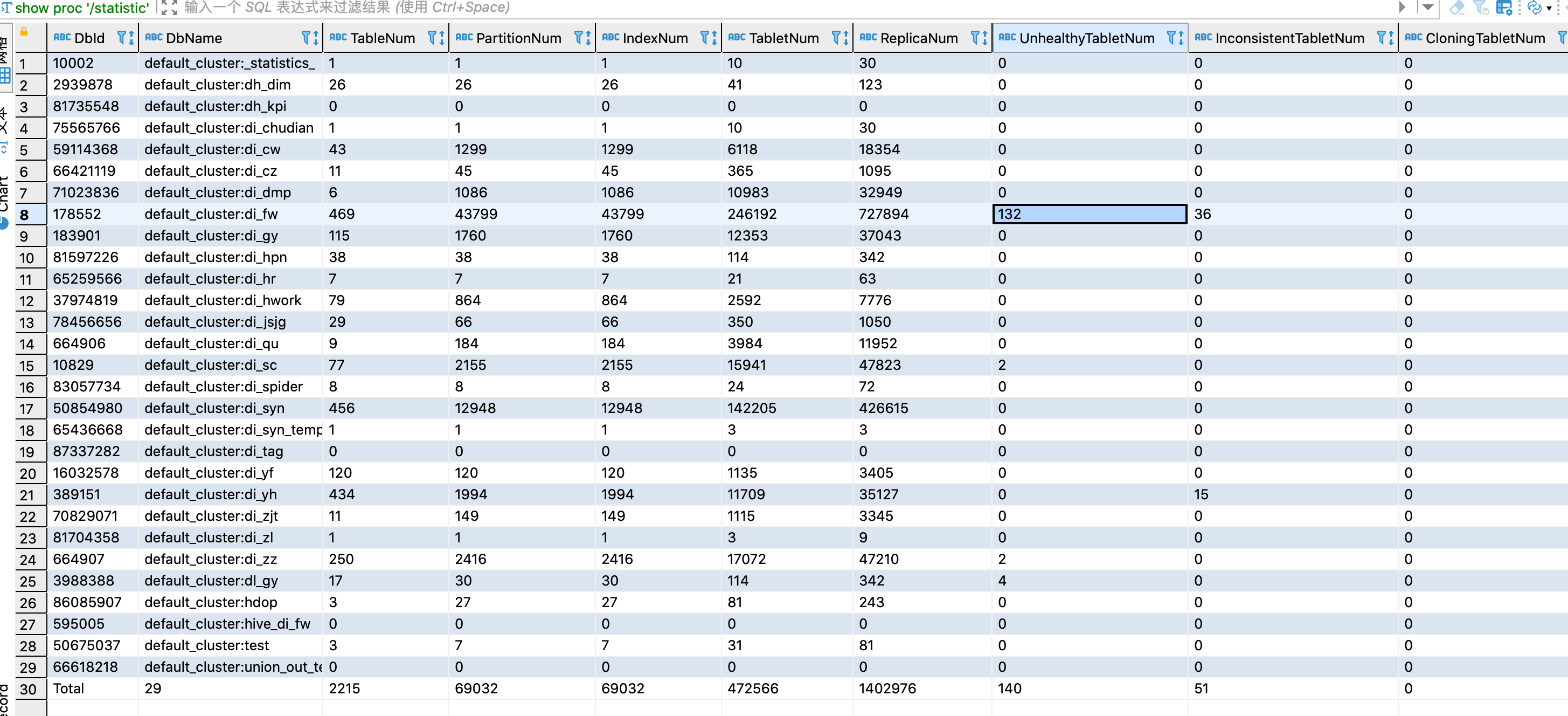
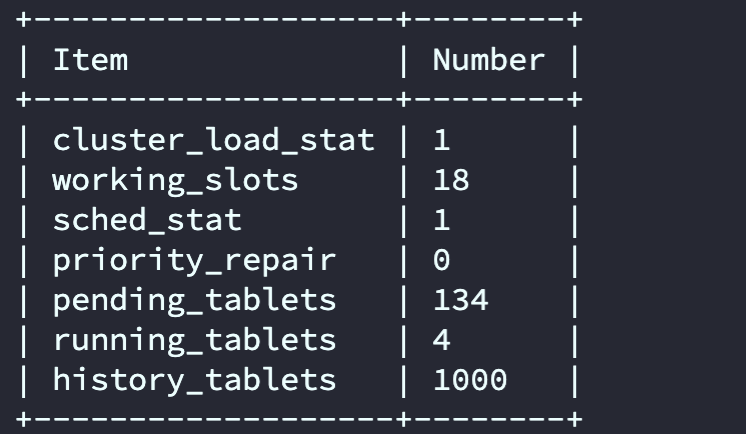
show proc ‘/statistic’ 麻烦也在master执行下吧
收到 您按照说的重试了吗 结果怎么样?昨天fe日志也上传下定位下原因
刚才取消之后,tabletnum上涨了,接着执行命令重新调度还是卡住
您在 fe master 执行grep -i “decommission|clone|TabletScheduler” fe.log ,日志发来看下迁移失败的原因
你好,我刚才执行drop的时候发现有张表没有三副本,我就给加上了,之后这台服务器就能正常卸载了