【详述】上周建了几个有CG属性的表,导完数据后用explain+待查询SQL确认colocate join生效,实测查询速度也比原来快了接近一倍左右,但这周再次查询相同SQL发现速度慢了很多,才发现colocate join 失效退化为了普通查询,后续发现建的三个colocate group的IsStable 全都变为false的状态
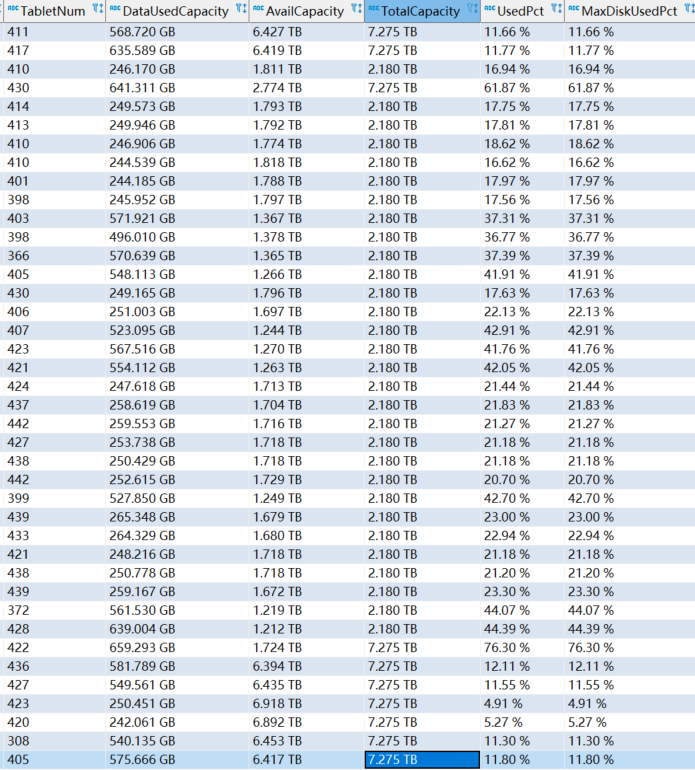
【背景】新建了几个表并导入了数据,但新建的表和已创建成功的colocate group里的表没有任何关系,导入数据后有一节点个磁盘使用量达到76%,第二多的一个节点的使用量达到68%,其他节点全都在50%以下
【业务影响】join 操作变慢
【StarRocks版本】2.1.1 arm架构 64位版
【集群规模】例如:3fe+40be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡 48C/512G/千兆
【附件】
-

- be节点cpu和内存使用率截图

- 查询报错:
- 无
各节点磁盘占用
- 无