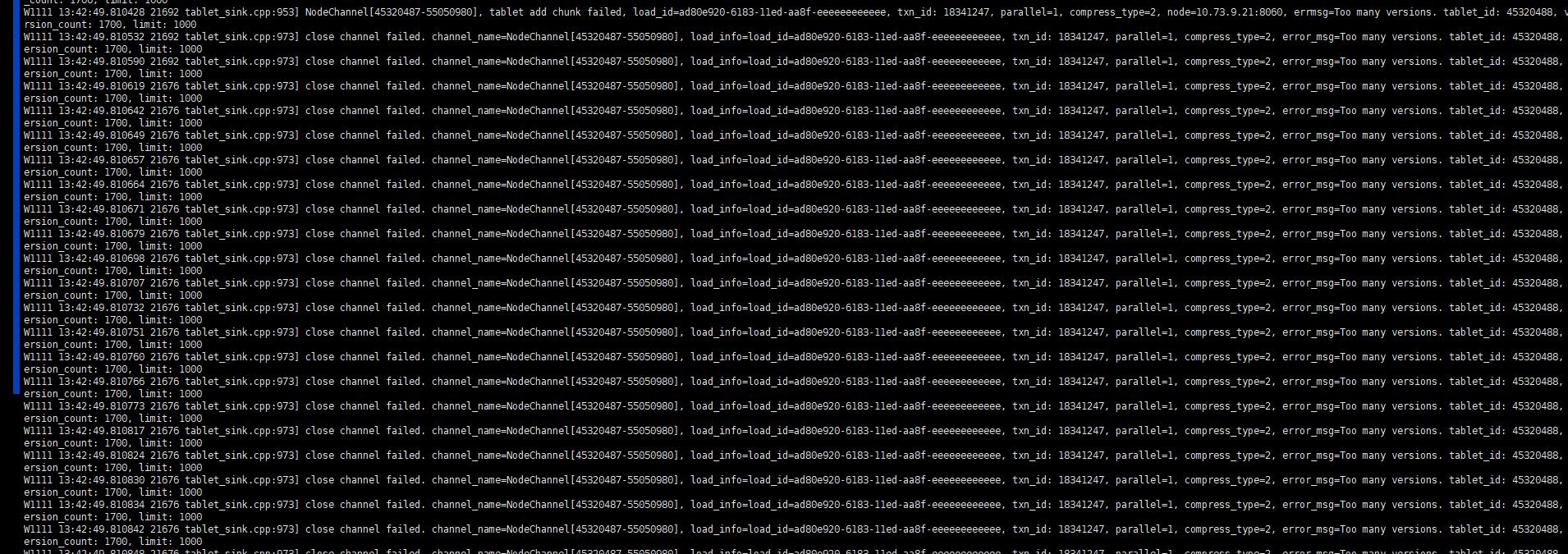
日志中经常出现: version超过1000 是column_statistics 这个表
另外还有好些这样的日志:
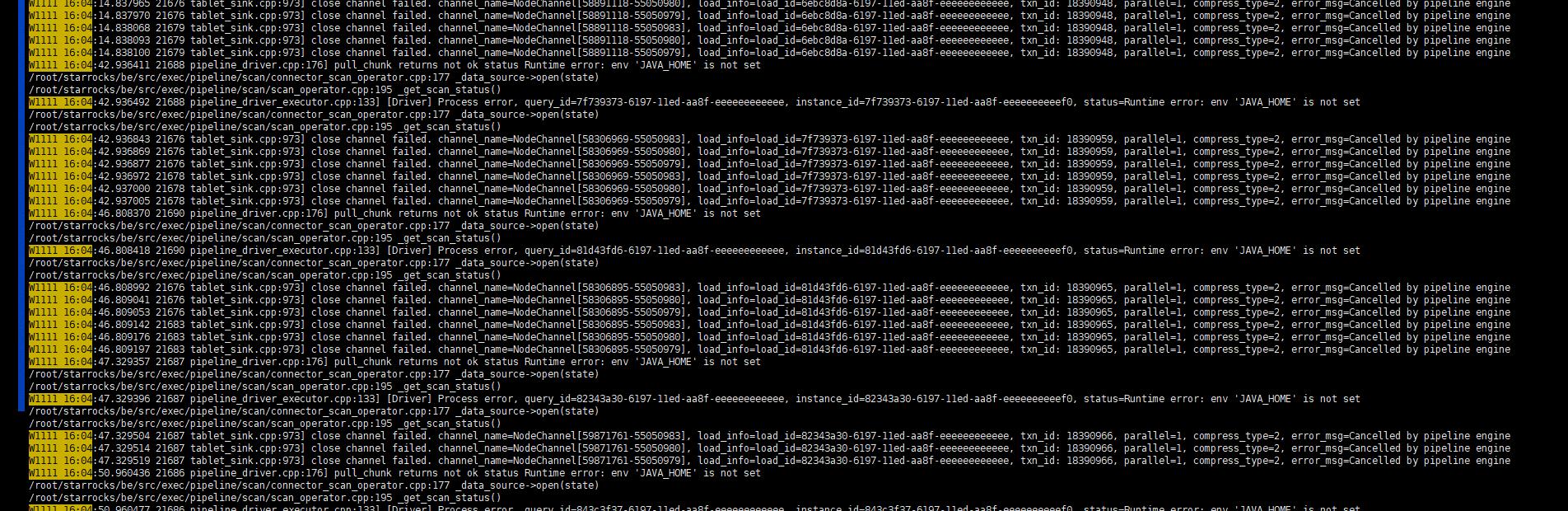
这些错误信息需要怎么处理

column_statistics是统计信息收集的表,您使用的是什么版本?集群中有什么导入任务吗?
用的是2.4.0版本,集群是有比较多的stream和broker load任务
报错信息打的都是超版本数限制的错误,您可以提高compaction的速度或者修改默认版本数1000,这个报错一般都是由于导入频率过快导致的,建议导入频率10s一次
增加compaction的并发数以及缩短check间隔? 另外version是这两个tablet_max_pending_versions=1000
tablet_max_versions=1000 参数都需要调整么? 调整大了会有什么影响不?
close index channel failed/too many tablet versions 参考这里提供的几个compaction参数,一般不建议打开1000版本(tablet_max_versions=1000 )的限制,会对集群造成压力。
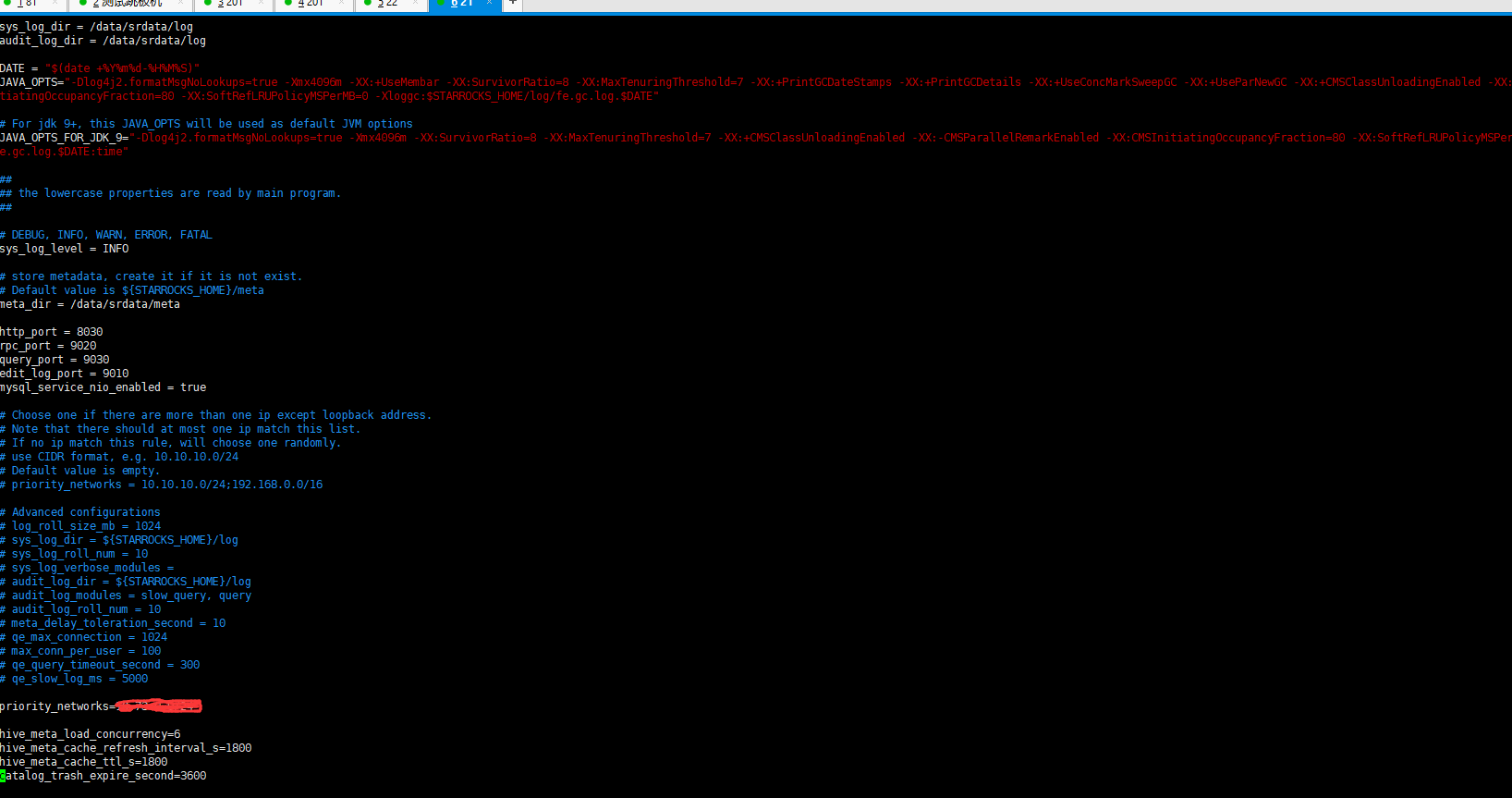
另外检查一下java_home的配置,看日志里面有打印未设置JAVA_HOME
java_home这边是有问题,在启动be的时候没有配置JAVA_HOME变量,已经处理了,
控制到10s一次导入我们这场景不太好弄, 对了 问下有没有办法控制多个fe的jdbc连接,控制查询sql只查master节点(因为查看tablet的version号需要到master节点才行。follower节点有分钟级别的延迟)?另外mater节点也有可能切换。
另外我先参考下compaction的参数信息吧,version打开限制估计对查询的影响会比较大,
分钟级延迟这个是怎么看的,有相关日志吗?目前没办法控制,但是正常情况下fe的leader和follower之间信息的同步在ms级别,基本上不会影响查询才最对,如果像您说的有分钟级别的延迟,这个需要日志好好看看才行。
特意写了个脚本,同一条数据stream load插入差不多两千次,前后测试了三次结果都差不多,master节点“show tablet from tableName "能快速反应出来,但是fllower节点观测差不多等了一两分钟VersionCount的值才增加上来。所以才问问有没有办法控制某个sql查询jdbc时只去master节点提交。想如果stream load因为 “Too many versions”错误的时候,等待一会去查询version是否恢复,恢复了再重写一次
当时的leader节点和follower节点日志您这边方便提供下吗?另外问下您这边导入的目标表是什么模型的表呢?
我再写一次再拿下日志,目标表是主键模型,不过目前cumulative_compaction_check_interval_seconds这个时候默认配置60
好的,感谢,集群的配置麻烦您也提供一下,几fe(标注follower还是observer)几be等相关信息
集群配置: 1 LEADER 2 FOLLOWER 没有observer,
集群目前:是3台16core * 64G
磁盘: 500G SSD的阿里云服务器,
FE、BE混合部署
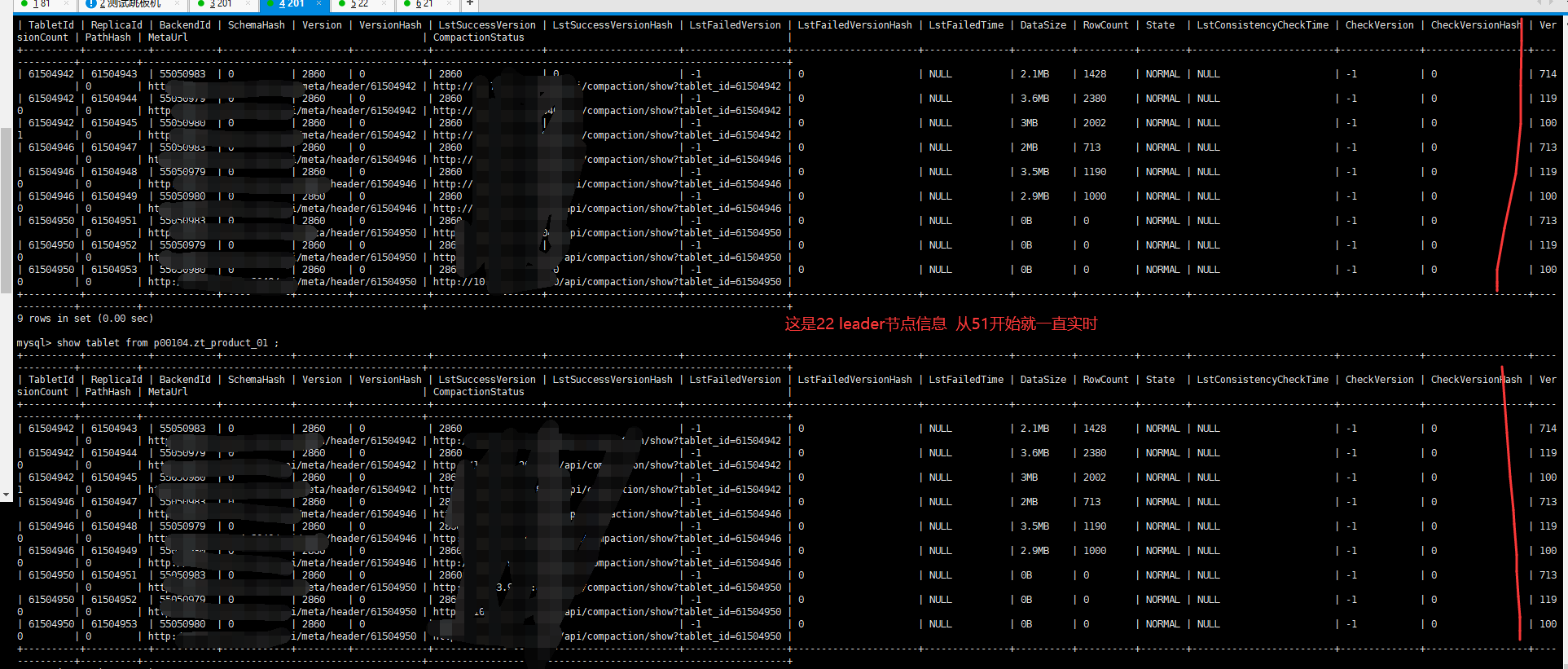
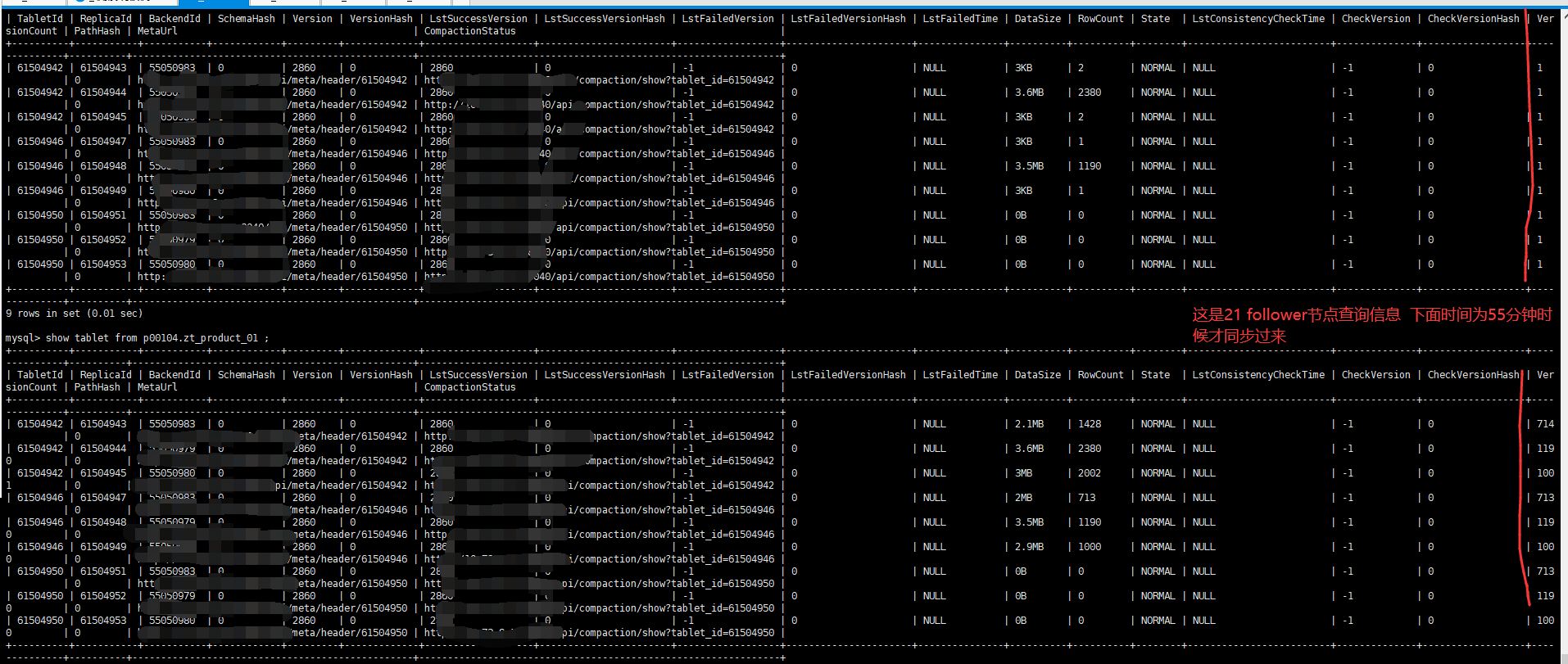
这次试了时间更长了 从15:51开始直接到了15:55 ,21(follower)节点 versionCount信息才同步过来,前面一直为1。
这是FE配置:
这是loader fe.log
22_master.fe.log (9.7 MB)
这是fllower fe.log
21.fllower.log (4.5 MB)
这里的versionCount是未合并的版本数,并不是导入版本,version是导入版本。version的同步是ms级的。versionCount是每个fe定时去be上获取的,这个可能会有分钟级的延时。
需要的没合并的版本数才行,请问下有没有办法能控制某个sql只往leader节点提交, 在多fe的jdbc连接下?
目前没有,导入请求会定向到leader节点,读不会。
那基于没合并的版本差数进行等待,这个思路还行不通