我测试发现了一个现象 State中serializeLength()方法返回0时 会出现不同分析主体的数据混淆的现象 是否能确认下 返回0时是否会有影响
目前serializeLength必须大于0。你可以理解为ByteBuffer是一个InputStream,如果序列化长度为空,我们在反序列化的时候就不知道某个state到底对应哪一个分组了
JAVA-udf:
- “symbol” = “xxx”指定的xxx类,如果evaluate方法在xxx的父类,而不再xxx的时候。则会报找不到evalute的方法;
- 如果symbol指定的xxx类有多个evalute方法重载,会报有多个evalute方法的错误
- create function无法一个创建命令指定多个库,导致每加入一个udf,都需要写大量的创建语句
- create function其实可以根据symbol中evaluate类型去获取参数和返回值,无需指定。
问题1的案例,NvlUdf继承了DoubleInputUdf,对外的evalute方法都在DoubleInputUdf接口中。“symbol” = “cn.com.sr.udf.common.NvlUdf”,则无法找到evalute方法
DoubleInputUdf.java (1.1 KB) NvlUdf.java (321 字节)
问题2的案例:类里有不同参数重载的参数方法,但是报错说发现多个evaluate-method
``
public class NvlUdf {
public final <T> T evaluate0(T value, T defaultVal) {
if (value == null) {
value = defaultVal;
}
return value;
}
public String evaluate(String value, String defaultVal){
return evaluate0(value,defaultVal);
}
public Integer evaluate(Integer value, Integer defaultVal){
return evaluate0(value,defaultVal);
}
}
``
1赞
JAVA udf:
symbol指定http,第一次查询或者过了很久再次查询,都会有几秒延迟。能否增加操作,可以指定各个节点将udf文件缓存到本地,刷新通过命令触发刷新?
还有希望symbol支持hdfs
HDFS 这个2.5 或者是2.6 会支持
自定义udf和已有udf重名,但是类型不同的时候,如下:
drop function fx_temp.date_add(string,bigint,string);
CREATE FUNCTION fx_temp.date_add(string,bigint,string)
RETURNS string
properties (
“symbol” = “cn.com.xxx.sr.udf.date.DateAddUdf”,
“type” = “StarrocksJar”,
“file” = “file:///data1/hadoop/soft/package/StarRocks-2.2.2/udf/lib/xxx-sr-udf-1.0-SNAPSHOT.jar”
);
此时如果使用以下命令,会按照已有udf的参数去校验,报出了参数不匹配的错误:
use fx_temp;
select date_add(‘day’,3,‘2022-09-31’);

调用如下操作又是正常的:
select fx_temp.date_add(‘day’,3,‘2022-09-31’);
这个正常应该有个 函数名+参数类型的优先匹配机制把。
第三点确实很费事,不如hive好使。我都写个接口,直接实例下所有库同时更新。
这个算一个bug,可以提一个issue
希望支持C++版本,doris都支持C++版本
后面可以考虑支持,但是目前StarRocks 迭代比较快C++的 ABI/API 不能保证稳定。很容易导致升级后需要重新编写。所以如果是自己想实现C++的UDF可以尝试编写builtin函数的方式做扩展开发。
有没有计划支持类似MySQL的自定义函数的计划?比如MySQL中可以用以下语句创建
DELIMITER $$
USE database$$
DROP FUNCTION IF EXISTS GetCodeByNM$$
CREATE DEFINER=xxx@% FUNCTION GetCodeByNM(cname VARCHAR(255)) RETURNS VARCHAR(2048) CHARSET utf8mb4
BEGIN
DECLARE retName VARCHAR(255) DEFAULT ‘’;
SELECT xxx INTO retName FROM table_name WHERE xxx = cname LIMIT 1;
IF retName IS NULL || retName =’’ THEN
SET retName=‘123’;
END IF;
RETURN retName;
END$$
DELIMITER ;
1赞
你好,目前在尝试编写builtin函数的方式扩展开发,有什么相关文档吗,或者demo之类的
这几天我写一下怎么添加 scalar builtin函数
好的,尤其是聚合函数,目前FE搭建成功了,be开发环境搭建有点困难,希望有个文档吧
1赞
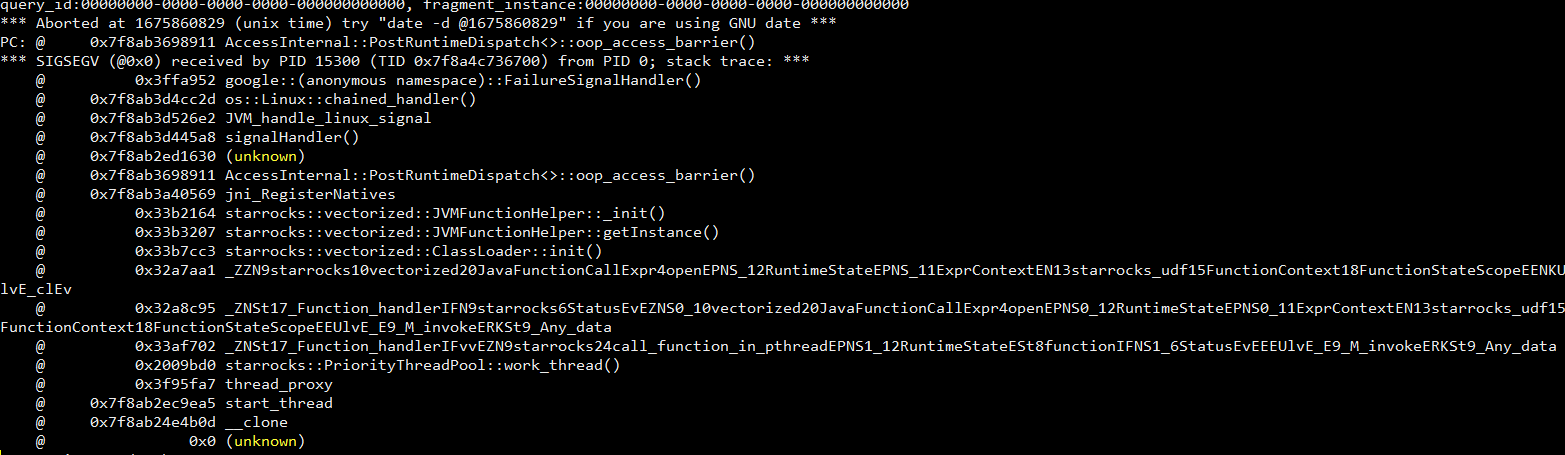
你好,新版本udf是否支持jdk11,目前2.3.3版本jdk11的udf直接导致be crash
可以详细说下吗,发下 be.out的crash堆栈?
我们先自己测试下,再给你个回复