【StarRocks版本】例如:2.1.4
【集群规模】例如:1fe +2be(fe与be混部)
【机器信息】32核32G
使用的主键表,routine load消费kafka同步数据。
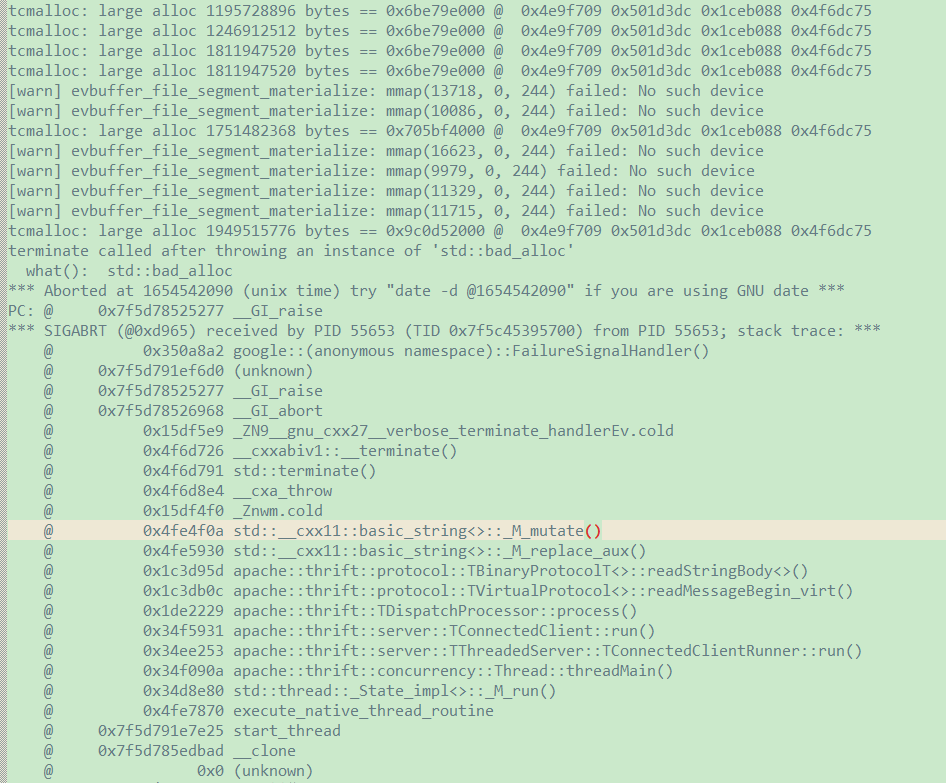
be.out 日志如下,2个be都是同样的堆栈:
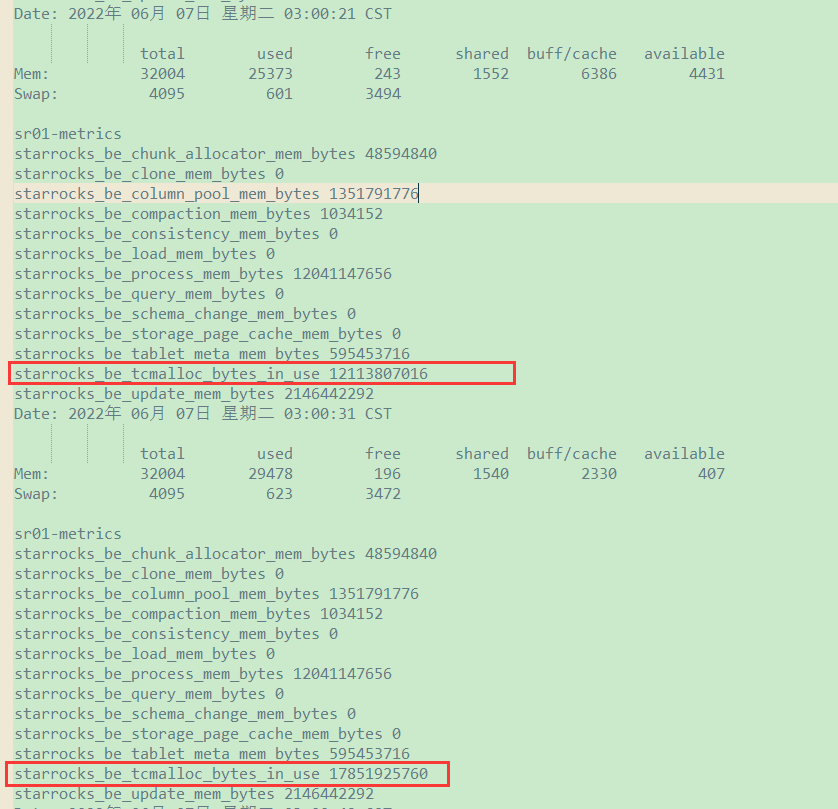
自己跑的内存监控输出如下,不明白的是starrocks_be_tcmalloc_bytes_in_use这块为啥突然暴涨很多,而starrocks_be_process_mem_bytes反而不是最大的,有啥方式可以限制或者优化嘛?

【StarRocks版本】例如:2.1.4
【集群规模】例如:1fe +2be(fe与be混部)
【机器信息】32核32G
使用的主键表,routine load消费kafka同步数据。
be.out 日志如下,2个be都是同样的堆栈:
自己跑的内存监控输出如下,不明白的是starrocks_be_tcmalloc_bytes_in_use这块为啥突然暴涨很多,而starrocks_be_process_mem_bytes反而不是最大的,有啥方式可以限制或者优化嘛?
有大查询吧,申请的内存,可以通过exec_mem_limit参数限制单线程查询的内存使用量
这个有方式可以追溯那时什么SQL占用的内存吗,audit.log里应该不会记录到把?
exec_mem_limit我没设置过,应该是默认的2G配置,这个不算高把
当前aduit没有统计sql使用的内存,不过你看看下sql查询的时间,一般使用内存比较大的sql耗时都会比其他小查询久