
好的,那等你们最新消息
请问大佬有解决方案了吗?
改代码, 需要等一段时间. 没什么临时解决方案, 看上去主要是导入压力大了之后, 有一些重试的 RPC 导致的竞争 crash.
我们的场景是每分钟同步完近400张线上mysql主键表,导入压力会来自这块吗?
其它基本就是sr本地数据加工场景,SQL也比较复杂,我做了最大内存使用上限为48G(没限制之前有超48G内存占用的SQL)
还有从常规资源上看,cpu、内存、磁盘io都没有处于高位,监控上看这些资源都充足。这个导入压力能帮忙解释一下吗?
可能是网络带宽压力, 可以看看监控. 日志里有一些节点超时, 失败之类的
好的,那就等修复版本吧
等 3.5.18 发版本, 带上对应的代码修复.
好的。
另外再问一下,从五一以后,fe jvm使用也出问题,出现一次oom故障。故障前jvm配置的是16G内存,后改为64G,现在看使用率增长比较快,已经超过80%了,截图是 fe leader 节点
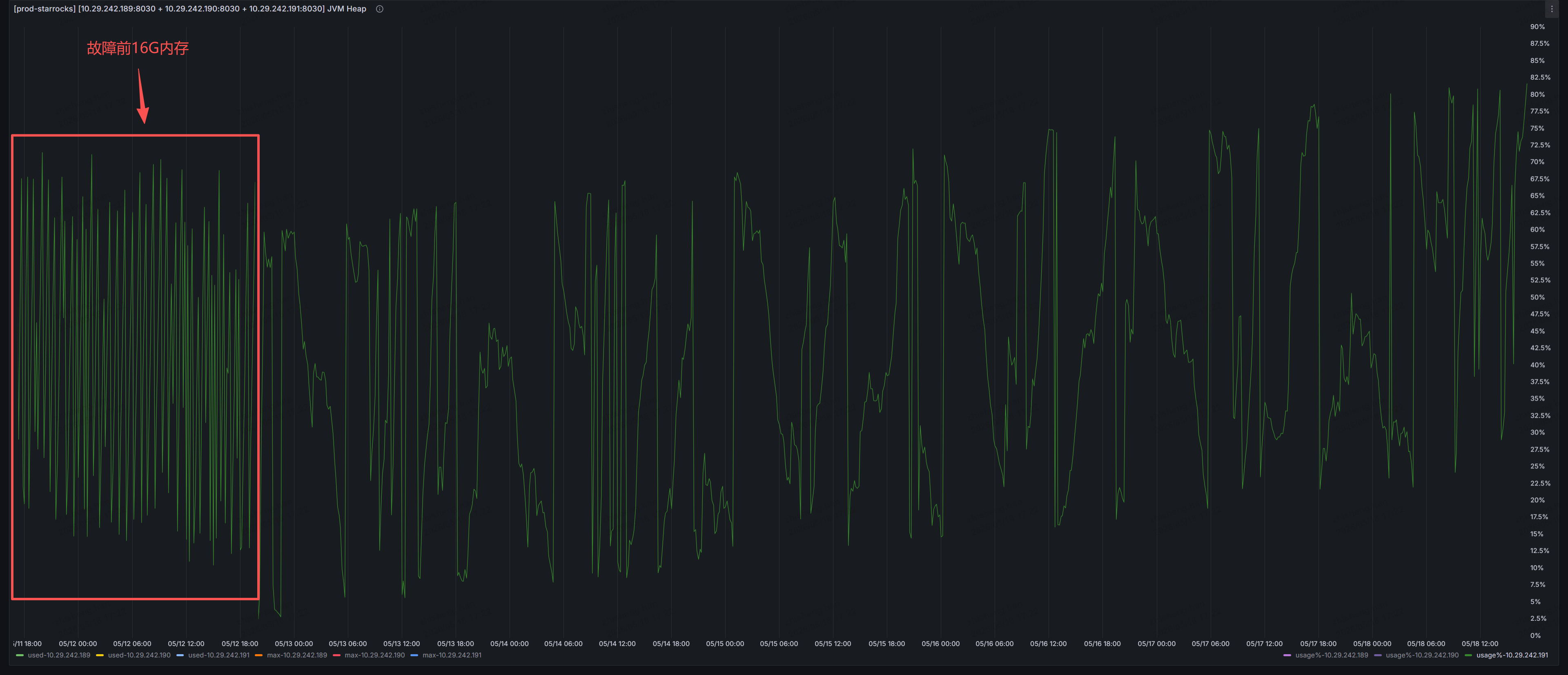
故障前
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xms16384m -Xmx16384m -XX:+UseG1GC -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time -XX:ErrorFile=${LOG_DIR}/hs_err_pid%p.log -Djava.security.policy=${STARROCKS_HOME}/conf/udf_security.policy"
故障后改为64G
JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xms64g -Xmx64g -XX:+UseG1GC -XX:G1HeapRegionSize=32m -XX:MaxGCPauseMillis=200 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR}/ -Xlog:gc*:${LOG_DIR}/fe.gc.log.$DATE:time -XX:ErrorFile=${LOG_DIR}/hs_err_pid%p.log -Djava.security.policy=${STARROCKS_HOME}/conf/udf_security.policy"
帮忙看下这个配置有问题吗?还是说与be节点bug存在关联?
- gc 日志观察 gc 回收与 region 使用增长情况. 2. 用 jmap -histo:all 和 jmap-histo:live dump 内存对象, 对比哪些对象回收慢, 再决定下一步动作.
大佬,3.5.18版本修复了be节点频繁宕机的问题了吗?我这边准备进行升级
建议升级验证