
【详述】使用spark-connector从聚合表中按分区读取数据后入库es
【集群规模】3fe+5be(fe与be混部)
【附件】
读取配置:
starrocks.batch.size:51200
starrocks.request.tablet.size:1
部分task报错
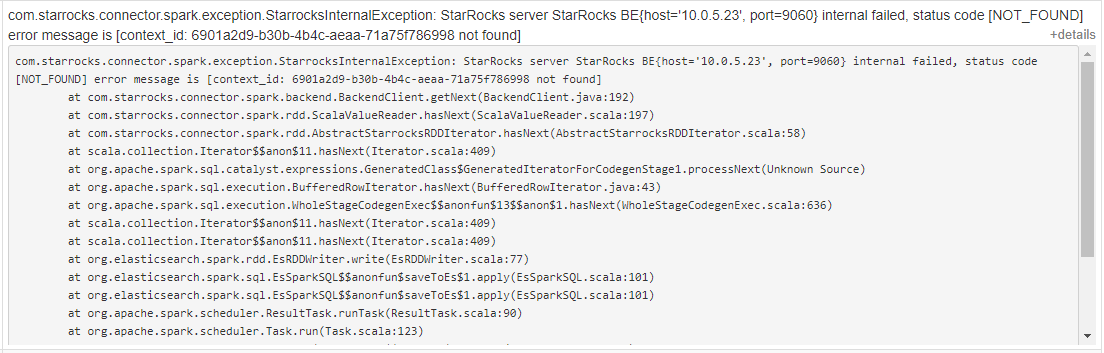
be的状态都是正常的么?请问基于什么需求需要将starrocks数据导出呢?
be状态都是正常的,是利用starrocks的去重表做upsert,然后将数据同步到另一个图数据库。
其他表数据量不超过10亿都是正常的。
只有这张表数据量40亿,经常会报错。