为了更快的定位您的问题,请提供以下信息,谢谢
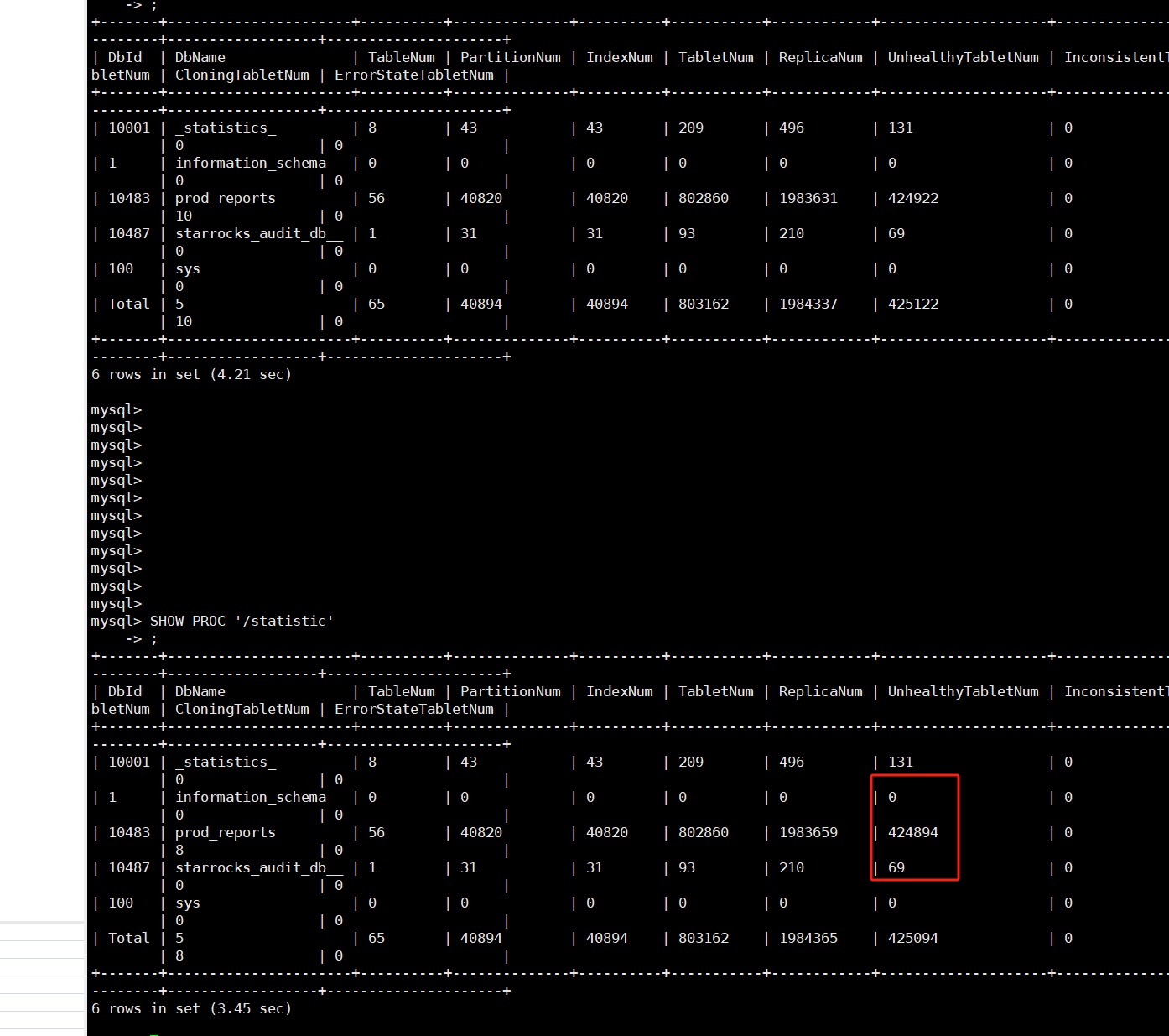
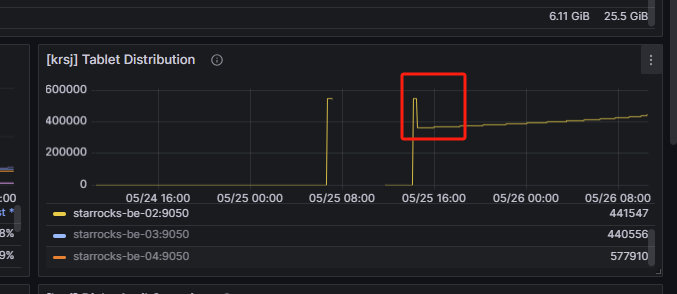
【详述】多次出现be节点重启之后,使用SHOW PROC ‘/statistic’; 会有大量UnhealthyTabletNum,等自动恢复极慢,期间表无法读写,报的错误有以下三种:
1、Caused by: java.sql.SQLSyntaxErrorException: Build Exec OlapScanNode fail, scan info is invalid;
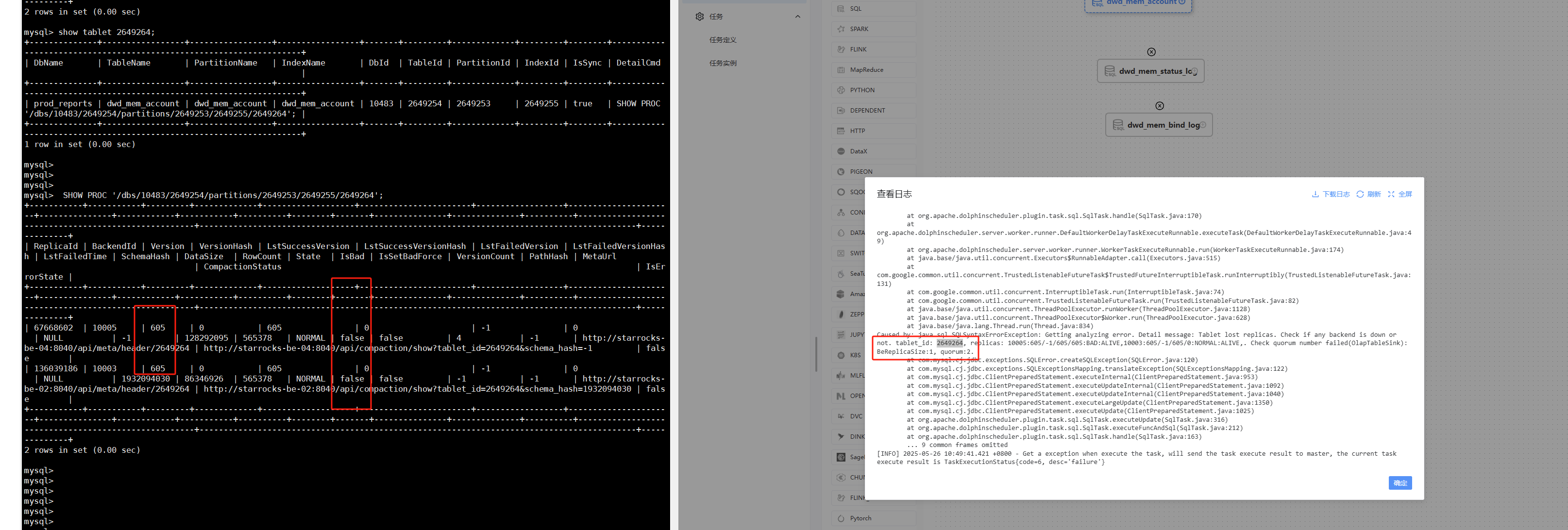
2、Caused by: java.sql.SQLSyntaxErrorException: Getting analyzing error. Detail message: Tablet lost replicas. Check if any backend is down or not. tablet_id: 42251387, replicas: 10005:613/-1/613/202:BAD:ALIVE,10003:613/-1/613/0:NORMAL:ALIVE,. Check quorum number failed(OlapTableSink): BeReplicaSize:1, quorum:2.
3、Caused by: java.sql.SQLException: Load rowset failed tablet:42251838 rowset:02000000002d8ce5eb4b841dae0bca8d88890fcbcd438ebb rssid:883 seg:0 path:/ssd/starrocks/data/572/42251838/687599445/02000000002d8ce5eb4b841dae0bca8d88890fcbcd438ebb_0.dat: /ssd/starrocks/data/572/42251838/687599445/02000000002d8ce5eb4b841dae0bca8d88890fcbcd438ebb_0.dat: No such file or directory: BE:10004
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129)
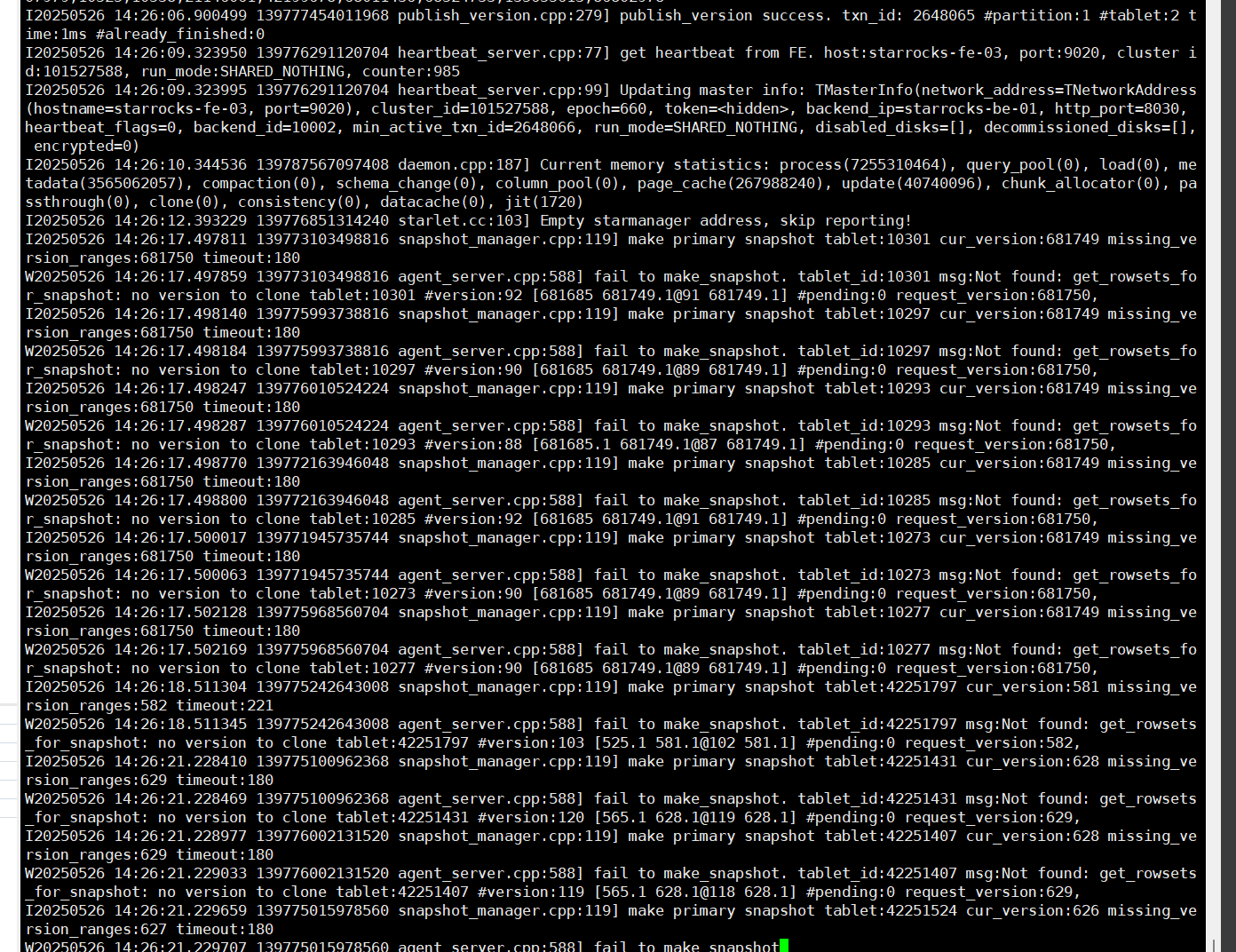
经过和社区群沟通26的韩流和wake沟通,be.conf配置load_tablet_timeout_seconds = -1 ignore_load_tablet_failure = true 解决了大量UnhealthyTabletNum的问题,但是还有第三个问题,导致任务还是无法运行,需要手工一个个set bad,量比较大,无法手工完成,最后无奈写了一个python的脚本,遍历所有的表,执行select * from 表名,报的错误里面截取tablet_id和 be_id 去自动set bad,才算基本恢复任务运行正常。但是还遗留的问题是,be.INFO还一直在刷:fail to make_snapshot. tablet_id:42251403 msg:Not found: get_rowsets_for_snapshot: no version to clone tablet:42251403 #version:124 [565.1 630.1@123 630.1] #pending:0 request_version:631,
I20250526 15:00:44.475445 139775015978560 snapshot_manager.cpp:119] make primary snapshot tablet:10301 cur_version:681758 missing_version_ranges:681759 timeout:180
【背景】关机给be的虚拟机内存由64GB增加到128GB,在之前fe节点一直无故挂,还没定位到原因,暂时没有复现。
【业务影响】无法读写,严重问题
【是否存算分离】否
【StarRocks版本】3.3.13
【集群规模】例如:3fe(2follower)+4be
【机器信息】16C/128G/万兆
【联系方式】社区群26-顽强
【附件】