
你是打算放到sr里面的一张表里吗?
是的
场景是:
目前我们根据会员,数据分配到了不同的mysql实例中(目前14个)的相同表结构的表中;
现需要将这些表存到starrocks中,并且存入sr中时添加一列dbname(该列可以从canal=》kafka中的database获取)
遇到类似问题
–源端
CREATE TABLE test1 (
app_id varchar(10) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
app_name varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
description varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
cookie_domain varchar(64) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
cookie_path varchar(400) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
index_url varchar(400) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
verify_name varchar(64) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (app_id) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin ROW_FORMAT=COMPACT
-SR 端
CREATE TABLE test1 (
app_id varchar(65533) NOT NULL COMMENT “”,
app_name varchar(65533) NOT NULL COMMENT “”,
description varchar(65533) NULL COMMENT “”,
cookie_domain varchar(65533) NULL COMMENT “”,
cookie_path varchar(65533) NULL COMMENT “”,
index_url varchar(65533) NULL COMMENT “”,
verify_name varchar(65533) NULL COMMENT “”
) ENGINE=OLAP
PRIMARY KEY(app_id)
COMMENT “OLAP”
DISTRIBUTED BY HASH(app_id) BUCKETS 1
PROPERTIES (
“replication_num” = “1”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”
);
– routine load
create routine load test.test1 on test1
columns (app_id,app_name,description,cookie_domain,cookie_path,index_url,verify_name)
PROPERTIES (
“format”=“json”,
“jsonpaths” = “[”$.data[0].app_id","$.data[0].app_name","$.data[0].description","$.data[0].cookie_domain","$.data[0].cookie_path","$.data[0].index_url","$.data[0].index_url","$.data[0].verify_name"]",
“desired_concurrent_number”=“1”,
“max_error_number”=“0”
)
FROM KAFKA (
“kafka_broker_list”= “10.0.10.12:9092”,
“kafka_topic”=“test_test1”
);
– 数据1
{
“data”: [
{
“app_id”: “123123”,
“app_name”: “4444666666”,
“description”: “23123123”,
“cookie_domain”: “2312”,
“cookie_path”: “31231”,
“index_url”: “231”,
“verify_name”: “2312312”
}
],
“database”: “test1”,
“es”: 1647347567000,
“id”: 4380,
“isDdl”: false,
“mysqlType”: {
“app_id”: “varchar(10)”,
“app_name”: “varchar(50)”,
“description”: “varchar(100)”,
“app_password”: “varchar(32)”,
“cookie_domain”: “varchar(64)”,
“cookie_path”: “varchar(400)”,
“index_url”: “varchar(400)”,
“verify_name”: “varchar(64)”
},
“old”: null,
“pkNames”: [
“app_id”
],
“sql”: “”,
“sqlType”: {
“app_id”: 12,
“app_name”: 12,
“description”: 12,
“app_password”: 12,
“cookie_domain”: 12,
“cookie_path”: 12,
“index_url”: 12,
“verify_name”: 12
},
“table”: “test1”,
“ts”: 1647347567535,
“type”: “DELETE”
}
– 数据2
{
“data”: [
{
“app_id”: “12312”,
“app_name”: “12312323423”,
“description”: “12312123”,
“cookie_domain”: “1231”,
“cookie_path”: “231”,
“index_url”: “23123”,
“verify_name”: “1231231”
}
],
“database”: “test”,
“es”: 1647346751000,
“id”: 4241,
“isDdl”: false,
“mysqlType”: {
“app_id”: “varchar(10)”,
“app_name”: “varchar(50)”,
“description”: “varchar(100)”,
“cookie_domain”: “varchar(64)”,
“cookie_path”: “varchar(400)”,
“index_url”: “varchar(400)”,
“verify_name”: “varchar(64)”
},
“old”: [
{
“app_name”: “123123”
}
],
“pkNames”: [
“app_id”
],
“sql”: “”,
“sqlType”: {
“app_id”: 12,
“app_name”: 12,
“description”: 12,
“cookie_domain”: 12,
“cookie_path”: 12,
“index_url”: 12,
“verify_name”: 12
},
“table”: “test1”,
“ts”: 1647346751924,
“type”: “UPDATE”
}
sr表中需要定义一个database的字段,然后在jsonpath和columns中映射就可以
CREATE TABLE test1 (
app_id varchar(65533) NOT NULL COMMENT “”,
app_name varchar(65533) NOT NULL COMMENT “”,
description varchar(65533) NULL COMMENT “”,
cookie_domain varchar(65533) NULL COMMENT “”,
cookie_path varchar(65533) NULL COMMENT “”,
index_url varchar(65533) NULL COMMENT “”,
verify_name varchar(65533) NULL COMMENT “”
database varchar(65533) NULL COMMENT “”
) ENGINE=OLAP
PRIMARY KEY( app_id )
COMMENT “OLAP”
DISTRIBUTED BY HASH( app_id ) BUCKETS 1
PROPERTIES (
“replication_num” = “1”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”
);
create routine load test.test1 on test1
columns (app_id,app_name,description,cookie_domain,cookie_path,index_url,verify_name,database)
PROPERTIES (
“format”=“json”,
“jsonpaths” = “[”$.data[0].app_id","$.data[0].app_name","$.data[0].description","$.data[0].cookie_domain","$.data[0].cookie_path","$.data[0].index_url","$.data[0].index_url","$.data[0].verify_name","$.database"]",
“desired_concurrent_number”=“1”,
“max_error_number”=“0”
)
FROM KAFKA (
“kafka_broker_list”= “10.0.10.12:9092”,
“kafka_topic”=“test_test1”
);
create routine load test.test1 on test1
columns (app_id,app_name,description,cookie_domain,cookie_path,index_url,verify_name, database,temp,__op=(CASE temp WHEN “DELETE” THEN 1 ELSE 0 END) )
PROPERTIES (
“format”=“json”,
“jsonpaths” = “[”$.data[0].app_id","$.data[0].app_name","$.data[0].description","$.data[0].cookie_domain","$.data[0].cookie_path","$.data[0].index_url","$.data[0].index_url","$.data[0].verify_name" ,"$.database","$.type" ]",
“desired_concurrent_number”=“1”,
“max_error_number”=“0”
)
FROM KAFKA (
“kafka_broker_list”= “10.0.10.12:9092”,
“kafka_topic”=“test_test1”
);
“jsonpaths” = “[”$.data[0].app_id","$.data[0].app_name","$.data[0].description","$.data[0].cookie_domain","$.data[0].cookie_path","$.data[0].index_url","$.data[0].index_url","$.data[0].verify_name" ,"$.database", “$.type” ]",
如果canal json过来的 data节点数据是多条,比如:“data”: [
{
“app_id”: “12312”,
“app_name”: “12312323423”,
“description”: “12312123”,
“cookie_domain”: “1231”,
“cookie_path”: “231”,
“index_url”: “23123”,
“verify_name”: “1231231”
},
{
“app_id”: “12312”,
“app_name”: “4444444”,
“description”: “12312123”,
“cookie_domain”: “1231”,
“cookie_path”: “231”,
“index_url”: “23123”,
“verify_name”: “1231231”
}
],
“database”: “test”,
“es”: 1647346751000,
“id”: 4241,
“isDdl”: false,
“mysqlType”: {
“app_id”: “varchar(10)”,
“app_name”: “varchar(50)”,
“description”: “varchar(100)”,
“cookie_domain”: “varchar(64)”,
“cookie_path”: “varchar(400)”,
“index_url”: “varchar(400)”,
“verify_name”: “varchar(64)”
},
“old”: [
{
“app_name”: “123123”
}
],
“pkNames”: [
“app_id”
],
“sql”: “”,
“sqlType”: {
“app_id”: 12,
“app_name”: 12,
“description”: 12,
“cookie_domain”: 12,
“cookie_path”: 12,
“index_url”: 12,
“verify_name”: 12
},
“table”: “test1”,
“ts”: 1647346751924,
“type”: “UPDATE”
}
如何设置这个jsonpath ?
当时不支持data中是一个array的数据格式
当时不支持? 现在支持了吗?
现在不支持data中是一个array格式
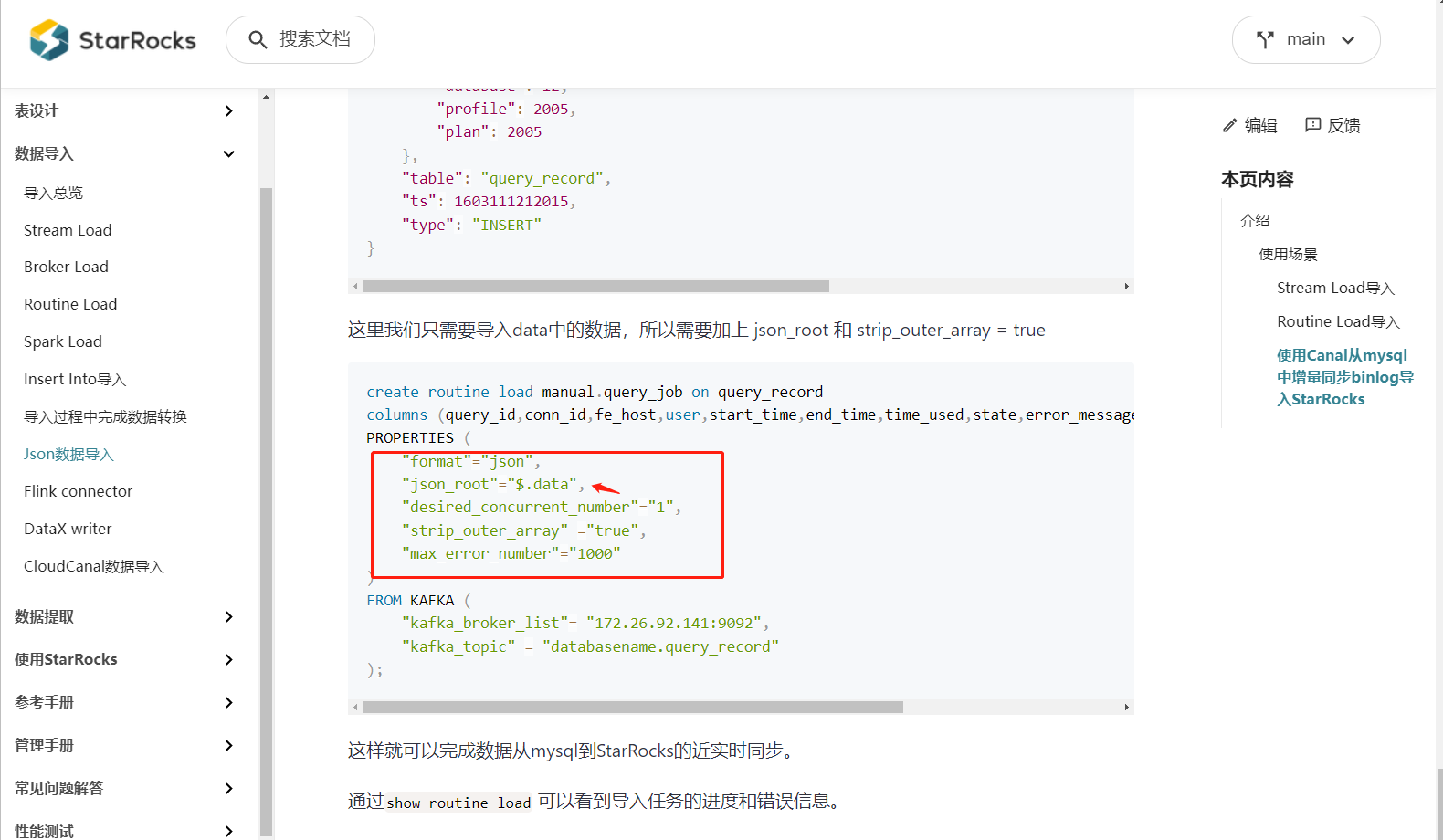
发下routine load配置

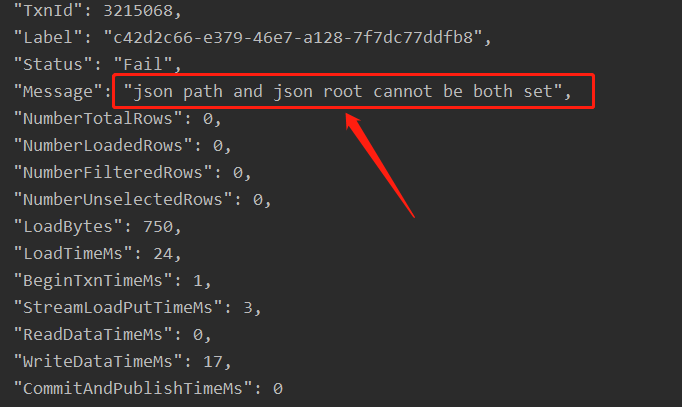
是的,当前不支持json path和json root同时指定,咱们可以使用flink-cdc的方案吗?可以读取kafka中canal的数据然后同步到starrocks
请问有没有flink-cdc 和kafka的完整列子?
本来表就多,如果在引入flink-cdc感觉不好维护,是否稳定可靠?
flink-cdc 会锁表,flink-sql生成 job 异常中断后无法恢复,表一多,表结构变更多的场景下维护很麻烦
你们在数据同步这块没可靠稳定的易维护的方案吗?
可参考https://forum.mirrorship.cn/t/topic/1815
请问下这个json path和json root同时指定的问题,以后版本会修复嘛,如果会的话,大概是什么版本,现在我遇到是2.1版本貌似都有这个问题,2.0貌似不会