
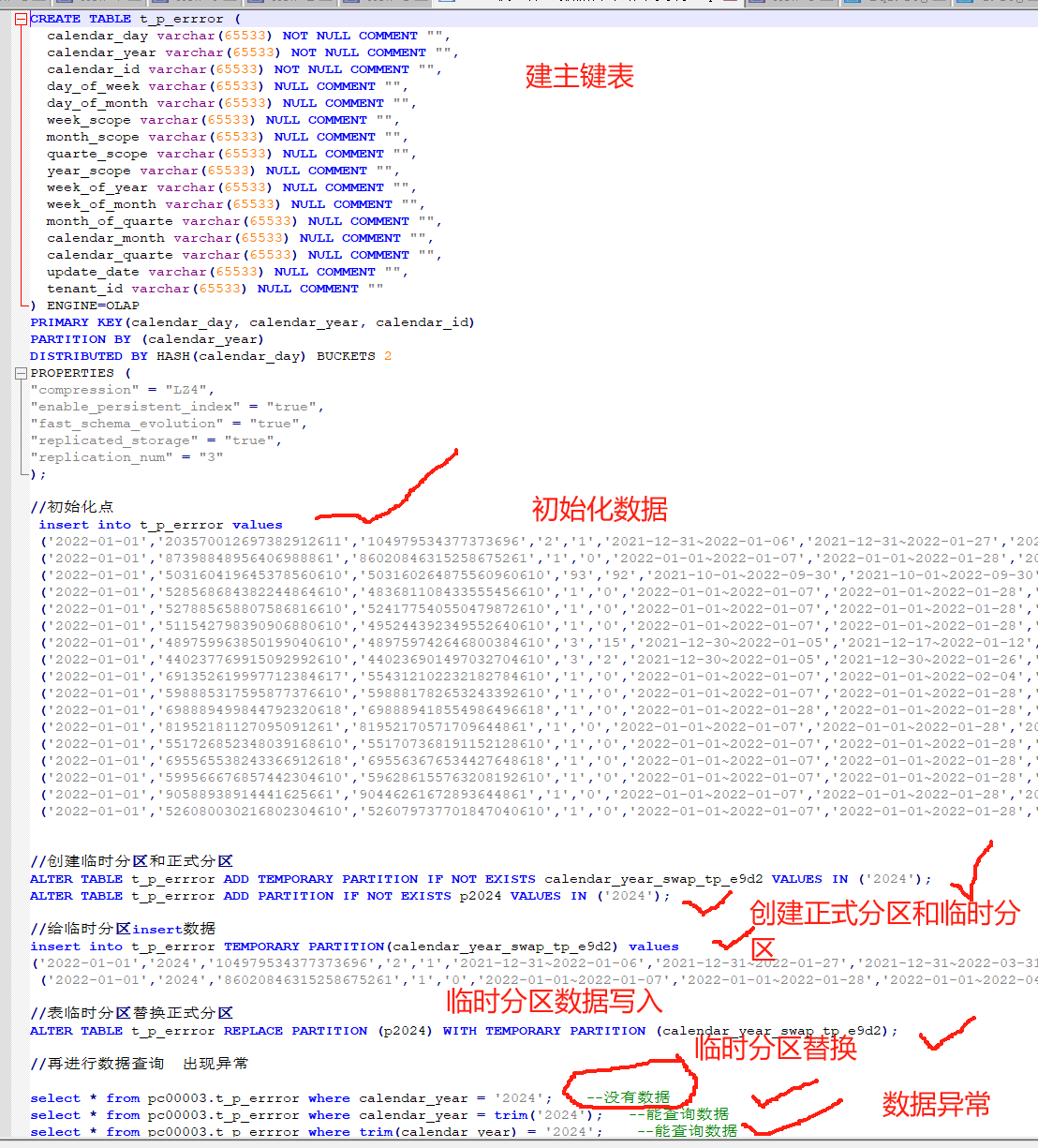
新表数据怎么导入的?下次导入的时候,将查询出现异常的字段,通过trim的方式处理一下。看一下是否还会出现异常
在fe.audit.log中确认一下,除了select之外,这张表还做了哪些操作
最近三天除了select之外,还有如下操作:
删除分区如: alter table sdp_financial_calendar drop partition if exists p551760251683065856610
数据insert如 : INSERT INTO default_catalog.pc00003.sdp_financial_calendar SELECT calendar_day,calendar_year,calendar_id,day_of_week,day_of_month,week_scope,month_scope,quarte_scope,year_scope,week_of_year,week_of_month,month_of_quarte,calendar_month,calendar_quarte,update_date,tenant_id FROM hive.pc00003_mongodbbackup.sdp_financial_calendar
表的数据里面没有空格,直接在select里面使用查询结果和查询值直接等于 返回为true,另外trim和不去除字段length也是一致的
建议写一个定时任务检测一下这个表每天什么时候会出现这种情况,然后根据时间点排查操作。什么报错都没有,也没有异常的操作,稳定复现你描述的情况。这个本身是一个不合理的情况。
@Star_Cao 老师, 问题已经复现了,五分钟一次进行sql查询定位到时间点为凌晨: 00:20:01 ~ 00:25:01之间发生的
检测SQL: select length(trim(calendar_year)) as trim_len,length(calendar_year) as len,(calendar_year = ‘224459254763868160610’) as flag,calendar_year,now() as t_time from pc00003.sdp_financial_calendar where calendar_year = ‘224459254763868160610’ limit 1;
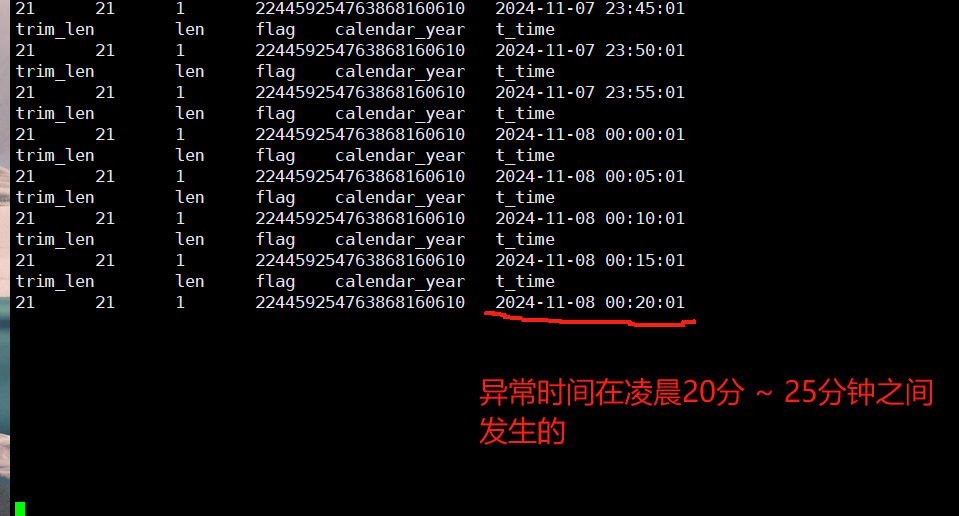
带上trim后查询正常

在00:20:00 ~ 00:30:00之间执行处理的业务逻辑有: 基于sdp_financial_calendar,如果正式分区不存在在创建正式分区,然后创建正式分区对应的临时分区,再将数据通过stream load写入临时分区中,再使用临时分区替换正式分区的方式,实现数据进行更新操作
对应时间点sql:
sql.log (309.7 KB)
对应时间点fe的log信息:
1.log (22.2 MB)
这种在常量后面加个trim也能查询出来:

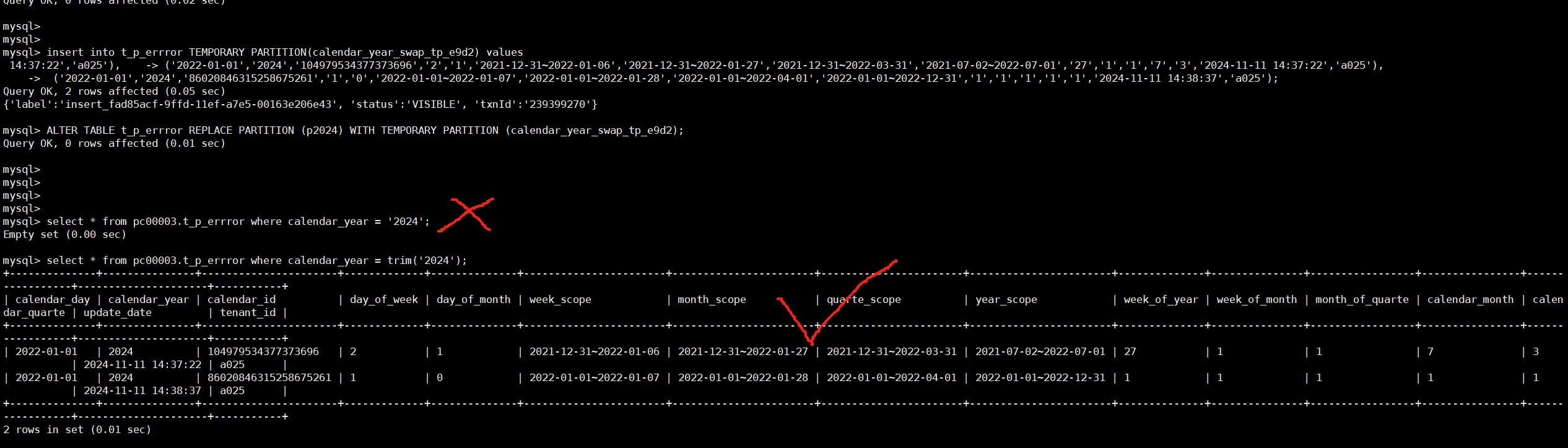
太牛了
不确定是不是使用方式不支持,直接将2024的两条数据插入原表中,自动生成新分区,查询是没有问题的。主键模型直接插入数据,相同主键会覆盖,不需要采用临时分区替换的方式来进行数据处理
临时分区替换的时候 分区出了问题,需要用的这个功能才会这么用
当前先规避这种使用方式,后续版本看一下是否能优化或者支持这种使用方式。
临时分区不是一直都支持么? 目前3.2的版本也发现这个问题,这个不仅仅是主键模型, 明细模型也存在一样的情况,其他的模型还没测试,应该和模型本身没关系,还是临时表替换正式分区后分区出现了异常
我们很多业务数据更新都是通过这种方式实现的,之前2.3的版本没问题
该问题将在3.3.7版本修复
@Star_Cao @许秀不许秀 找到原因了,是因为分区元数据的问题引起的,和临时分区替换无关,哪怕是正式分区也是一样的情况。 具体表现在创建分区的时候:
ALTER TABLE t_table ADD PARTITION IF NOT EXISTS p2024 VALUES IN ((‘2024’));
与 ALTER TABLE t_table ADD PARTITION IF NOT EXISTS p2024 VALUES IN ((2024’);
即list分区枚举值为一个的时候 带上两个括号还是一个括号的区别, 可以先在创建分区的时间带上两个括号来规避这个问题。单个括号用法非法

感谢两位社区老师支持 
他这个非list partition 有问题吗
range的没发现问题,这个主要是一个括号和两个括号引起的