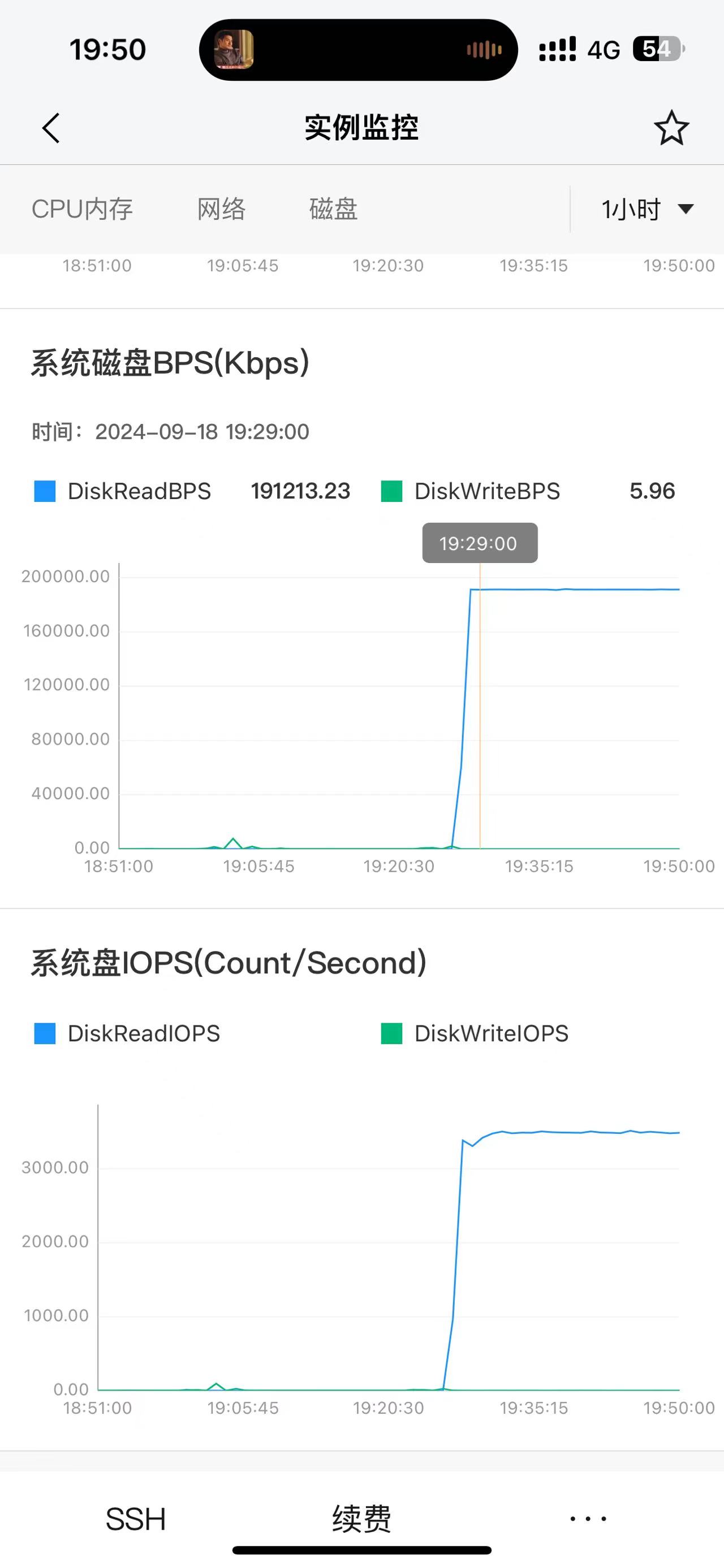
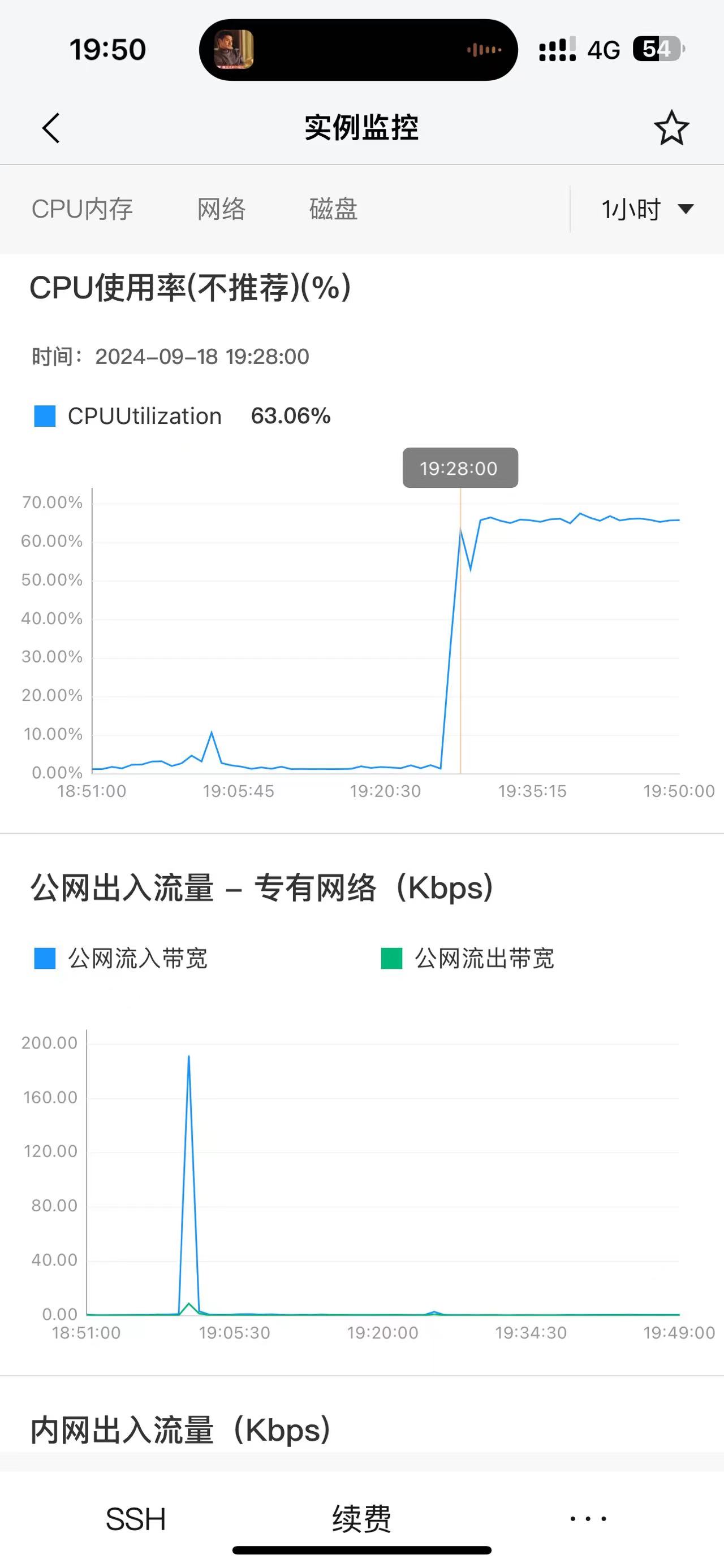
【详述】新集群连续入库4次,基本没有查询,其中一台机器有部分连接其他两个机器的超时,接着该机器磁盘和cpu就基本满了的状态,机器本身ssh也连接不上,半小时后直接重启机器恢复,我理解如果只是和其他机器连接不上,那么该机器应该只是重复请求连接,而不会做其他的时候,所以磁盘读写和cpu打满就有问题。
【背景】新集群连续入库4次,基本没有查询
【业务影响】其中一台机器直接资源飙升,假死状态,只能重启机器
【是否存算分离】存算一体
【StarRocks版本】例如:3.3.2
【集群规模】例如:3fe(1 follower+2observer)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】249848535@qq.com
【附件】
fe.log
W20240918 19:21:30.320805 139932347942464 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
W20240918 19:21:30.320805 139932347942464 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
W20240918 19:21:30.422335 139931495958080 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
W20240918 19:21:30.422335 139931495958080 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
W20240918 19:22:18.792342 139932364727872 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
W20240918 19:22:18.792342 139932364727872 thrift_rpc_helper.cpp:135] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=172.21.177.52, port=9020), reason=No more data to read.
BE日志
I20240918 19:24:53.838824 139931244176960 task_worker_pool.cpp:719] Report tablets successfully, report version: 17246517549411
I20240918 19:24:55.643950 139934558574144 daemon.cpp:199] Current memory statistics: process(5072169248), query_pool(0), load(0), metadata(582222457), compaction(0), schema_change(0), column_pool(0), page_cache(1193631008), update(110732752), chunk_allocator(2147147976), clone(0), consistency(0), datacache(0), jit(0)
I20240918 19:25:10.647630 139934558574144 daemon.cpp:199] Current memory statistics: process(5072169248), query_pool(0), load(0), metadata(582222457), compaction(0), schema_change(0), column_pool(0), page_cache(1193631008), update(110732752), chunk_allocator(2147147976), clone(0), consistency(0), datacache(0), jit(0)
I20240918 19:25:10.779276 139930818250304 starlet.cc:103] Empty starmanager address, skip reporting!
I20240918 19:25:25.650960 139934558574144 daemon.cpp:199] Current memory statistics: process(5072169248), query_pool(0), load(0), metadata(582222457), compaction(0), schema_change(0), column_pool(0), page_cache(1193631008), update(110732752), chunk_allocator(2147147976), clone(0), consistency(0), datacache(0), jit(0)
I20240918 19:25:38.568217 139904474371648 agent_server.cpp:441] Submit task success. type=CREATE, signature=1602704, task_count_in_queue=1
I20240918 19:25:38.568326 139904474371648 agent_server.cpp:441] Submit task success. type=CREATE, signature=1602708, task_count_in_queue=2
I20240918 19:25:38.568374 139931403638336 tablet_manager.cpp:169] Creating tablet 1602704
I20240918 19:25:38.568454 139931403638336 tablet_manager.cpp:1387] creating tablet meta. next_unique_id:108
I20240918 19:25:38.568543 139904474371648 agent_server.cpp:441] Submit task success. type=CREATE, signature=1602712, task_count_in_queue=3
I20240918 19:25:38.568783 139904306517568 tablet_manager.cpp:169] Creating tablet 1602708
I20240918 19:25:38.568934 139904230983232 tablet_manager.cpp:169] Creating tablet 1602712
I20240918 19:25:38.569012 139904306517568 tablet_manager.cpp:1387] creating tablet meta. next_unique_id:108
I20240918 19:25:38.569068 139904230983232 tablet_manager.cpp:1387] creating tablet meta. next_unique_id:108
I20240918 19:25:38.570805 139931403638336 tablet_manager.cpp:238] Created tablet 1602704
I20240918 19:25:38.571312 139904230983232 tablet_manager.cpp:238] Created tablet 1602712
I20240918 19:25:38.571378 139904306517568 tablet_manager.cpp:238] Created tablet 1602708
I20240918 19:25:38.597262 139932549367360 internal_service.cpp:437] exec plan fragment, fragment_instance_id=bb201328-75b0-11ef-b3ef-00163e30e21f, coord=TNetworkAddress(hostname=172.21.177.52, port=9020), backend=0, is_pipeline=1, chunk_size=4096
I20240918 19:25:38.604924 139932389905984 pipeline_driver_executor.cpp:354] [Driver] Succeed to report exec state: fragment_instance_id=bb201328-75b0-11ef-b3ef-00163e30e21f, is_done=1
I20240918 19:25:39.745455 139919837963840 heartbeat_server.cpp:77] get heartbeat from FE. host:172.21.177.52, port:9020, cluster id:419155877, run_mode:SHARED_NOTHING, counter:401389
I20240918 19:25:40.654067 139934558574144 daemon.cpp:199] Current memory statistics: process(5072164344), query_pool(0), load(0), metadata(582236733), compaction(0), schema_change(0), column_pool(0), page_cache(1193631008), update(110732752), chunk_allocator(2147147976), clone(0), consistency(0), datacache(0), jit(0)
I20240918 19:31:07.139901 139930818250304 starlet.cc:103] Empty starmanager address, skip reporting!
W20240918 19:28:42.832978 139931185428032 global.cpp:251] GlobalUpdate is too busy!
W20240918 19:28:42.832978 139931185428032 global.cpp:251] GlobalUpdate is too busy!
W20240918 19:28:43.382034 139931168642624 server.cpp:358] UpdateDerivedVars is too busy!
W20240918 19:28:43.382034 139931168642624 server.cpp:358] UpdateDerivedVars is too busy!
I20240918 19:38:43.299205 139931086816832 storage_engine.cpp:1023] start to sweep trash
I20240918 19:36:16.201925 139931111994944 primary_index.cpp:1068] primary index released table:11068 tablet:11070 memory: 10811964
I20240918 19:25:52.033285 139932499011136 internal_service.cpp:437] exec plan fragment, fragment_instance_id=bcd8236a-75b0-11ef-b3ef-00163e30e21f, coord=TNetworkAddress(hostname=172.21.177.52, port=9020), backend=0, is_pipeline=1, chunk_size=4096
I20240918 19:39:13.166733 139930944140864 olap_server.cpp:908] begin to do tablet meta checkpoint:/data/data/starrocks/be/storage
I20240918 19:47:33.082531 139930818250304 starlet.cc:103] Empty starmanager address, skip reporting!
I20240918 20:05:50.018972 140554112083712 daemon.cpp:292] version 3.3.2-857dd73
| enable_pipeline_engine | true |
|---|---|
| enable_pipeline_level_multi_partitioned_rf | false |
| max_pipeline_dop | 64 |
| pipeline_dop | 0 |
| pipeline_profile_level | 1 |
| pipeline_sink_dop | 0 |
parallel_fragment_exec_instance_num 1