
【是否存算分离】否
【StarRocks版本】2.5.13
【集群规模】3fe(1 follower+2observer)+3be(fe与be混部)
【机器信息】128C/256G/万兆
【联系方式】社区群13-麦咪
技术老师们,主键模型表在导入数据之后针对某条数据能看到表的数据更新几次吗,能从日志看到记录吗?
这个当前看不到的,没有数据行维度的日志或者其他信息的
好的,现在就是遇到一个问题,flink读取kafka数据往StarRocks写数据,发现数据量太大任务就不行了,数量小的话就可以,我不知道问题出在哪里,组长说是不是每次读取来一条数据之后就会插入全量数据?


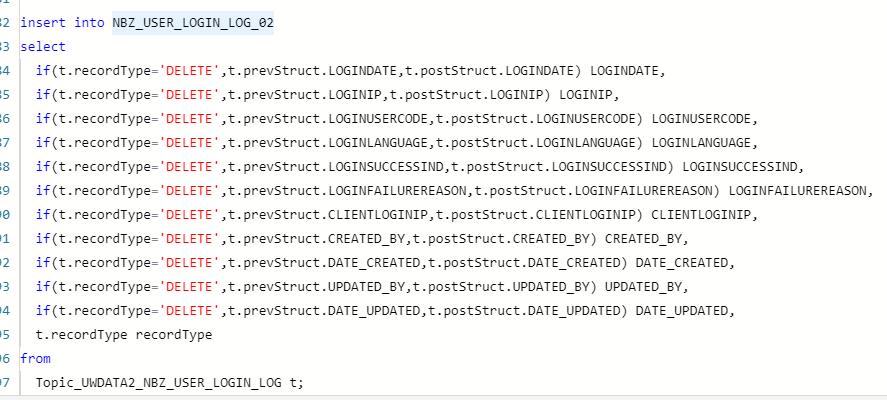
建表时没有加水位线,现在就是没法确定是不是这个原因引起资源问题的,要是能看StarRocks的记录经历多少次更新就好了,技术老师你了解这个问题吗?
数据量太大任务就不行了,这个是哪里不行呢
大佬 想问下,SR内表 创建的主键模型,然后使用 show index 怎么查不到不到主键索引呢
主键索引当前是看不到的,你是想看索引的什么信息吗
flink反压报错了
是这样的 我有一个 主键模型的表,然后 基于primary key 做where 查询 发现效率不高,感觉 好像没有走 主键索引 ,我就试了 show idnexes 看下 ,然后发现没有;
然后我在另一个 帖子发现 这个回答
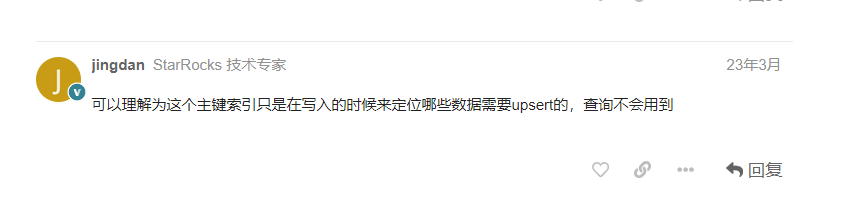
我现在 有点蒙了
嗯嗯主键模型的主键当前还只是为了快速进行upsert标记的,查询暂时还不会用到,这块后续在做开发,后续版本会支持主键索引用于加速查询。如果排序键和主键是一样的话,基于主键做where查询是可以使用到前缀索引加速的
反压是因为flink sink到sr太慢导致的吗?
不是,是source是kafka,我这flinkSQL有什么问题吗
source是kafka的反压是读取变慢了吗?因为sr消费写入太快了吗?flink sink到主键模型表的话,写入一条数据并不会插入全量
flinksql不是来一条数据就执行一遍sql吗,如果我insert into table select *的话不就相当于选取该表历史所有数据吗?
好的 谢谢大佬
大佬 我遇到一个新的问题:

创建语句如下:
CREATE MATERIALIZED VIEW sr_dw_customfield_key_value
COMMENT ‘customfield_key_value异步物化视图’
DISTRIBUTED BY HASH(issue)
REFRESH ASYNC
AS
SELECT b.issue,STR_TO_MAP(b.valueconcat,’{;}’,’{:}’) as valuemap FROM (
SELECT a.issue, GROUP_CONCAT(customfield,’{:}’,groupconcat SEPARATOR ‘{;}’) as valueconcat FROM (
SELECT issue,customfield,GROUP_CONCAT (IFNULL(stringvalue,IFNULL(numbervalue,IFNULL(textvalue,datevalue))) SEPARATOR ‘{#}’) as groupconcat
from sr_ods_customfieldvalue GROUP BY issue,customfield
) AS a GROUP BY a.issue
) AS b
我创建 这个物化视图的 query sql ,里面包含 str_map 函数,然后 视图创建成功了,但是使用 select * from information_schema.task_runs where task_name = ‘mv-48770’; 查询这个物化视图的任务,发现 写入失败了 ,一直在报这个错
,大佬帮看下是啥问题呢?是视图里面不给用 str_map 函数吗,里面对应 的 任务状态的 DEFINITION 如下: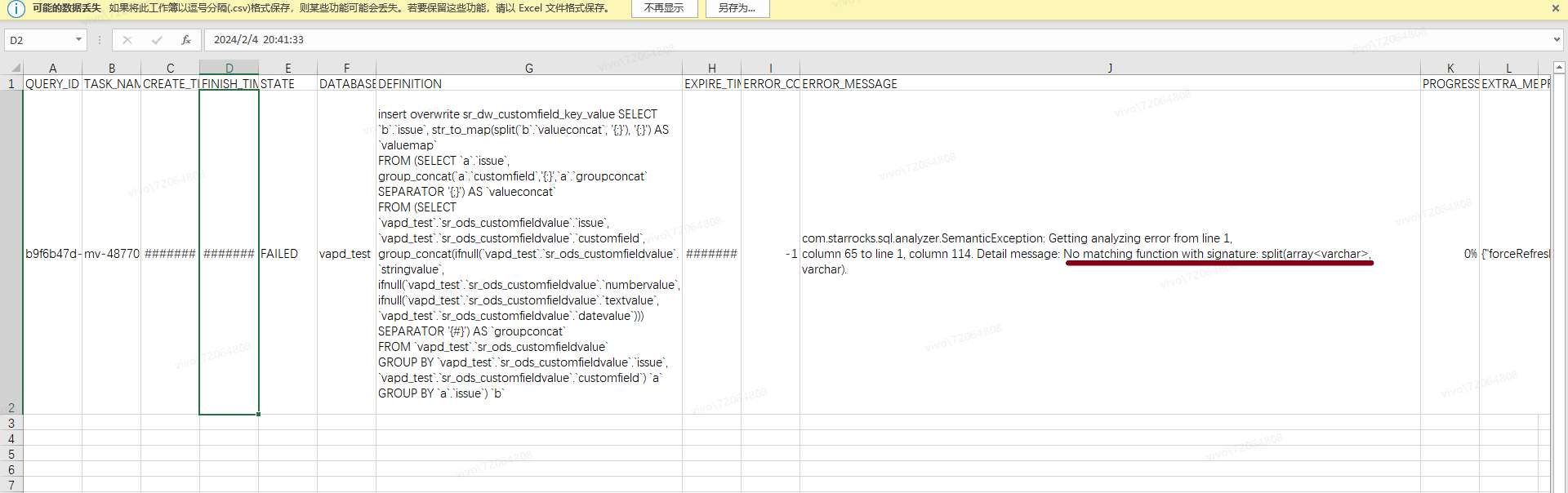
insert overwrite sr_dw_customfield_key_value SELECT
b.issue, str_to_map(split(b.valueconcat, ‘{;}’), ‘{:}’) AS valuemapFROM (SELECT
a.issue, group_concat(a.customfield,’{:}’,a.groupconcat SEPARATOR ‘{;}’) AS valueconcatFROM (SELECT
vapd_test.sr_ods_customfieldvalue.issue, vapd_test.sr_ods_customfieldvalue.customfield, group_concat(ifnull(vapd_test.sr_ods_customfieldvalue.stringvalue, ifnull(vapd_test.sr_ods_customfieldvalue.numbervalue, ifnull(vapd_test.sr_ods_customfieldvalue.textvalue, vapd_test.sr_ods_customfieldvalue.datevalue))) SEPARATOR ‘{#}’) AS groupconcatFROM
vapd_test.sr_ods_customfieldvalueGROUP BY
vapd_test.sr_ods_customfieldvalue.issue, vapd_test.sr_ods_customfieldvalue.customfield) aGROUP BY
a.issue) b;
报错信息如下:
com.starrocks.sql.analyzer.SemanticException: Getting analyzing error from line 1,
column 65 to line 1, column 114. Detail message: No matching function with signature: split(array, varchar).
谢谢大佬
额没太理解,你flink sql里insert into 的table为什么是个kafka source的表,不是写到sr的表里吗
什么版本,你explain 一下看看
explain SELECT b.issue,STR_TO_MAP(b.valueconcat,’{;}’,’{:}’) as valuemap FROM (
SELECT a.issue, GROUP_CONCAT(customfield,’{:}’,groupconcat SEPARATOR ‘{;}’) as valueconcat FROM (
SELECT issue,customfield,GROUP_CONCAT (IFNULL(stringvalue,IFNULL(numbervalue,IFNULL(textvalue,datevalue))) SEPARATOR ‘{#}’) as groupconcat
from sr_ods_customfieldvalue GROUP BY issue,customfield
) AS a GROUP BY a.issue
) AS b
3.1版本,explain 如下
_explain_SELECT_b_issue_STR_TO_MAP_b_valueconcat_as_valuemap_FRO_202402051052.csv (1.8 KB)
对了,我今早试了 很简单的 sql来创建 物化视图,我发现只要创建物化视图的 sql包含 str_to_map ,就会必现上面的写入错误
task_runs_202402051014.csv (928 字节)
版本是3.1的,explain 如下
_explain_SELECT_b_issue_STR_TO_MAP_b_valueconcat_as_valuemap_FRO_202402051052.csv (1.8 KB)
对了,我今早试了 很简单的 sql来创建 物化视图,我发现只要创建物化视图的 sql包含 str_to_map ,就会必现上面的写入错误
task_runs_202402051014.csv (928 字节)
我也在另一个帖子 发了下 复现的 demo-
sink insert是sr的表里,source读的是kafka