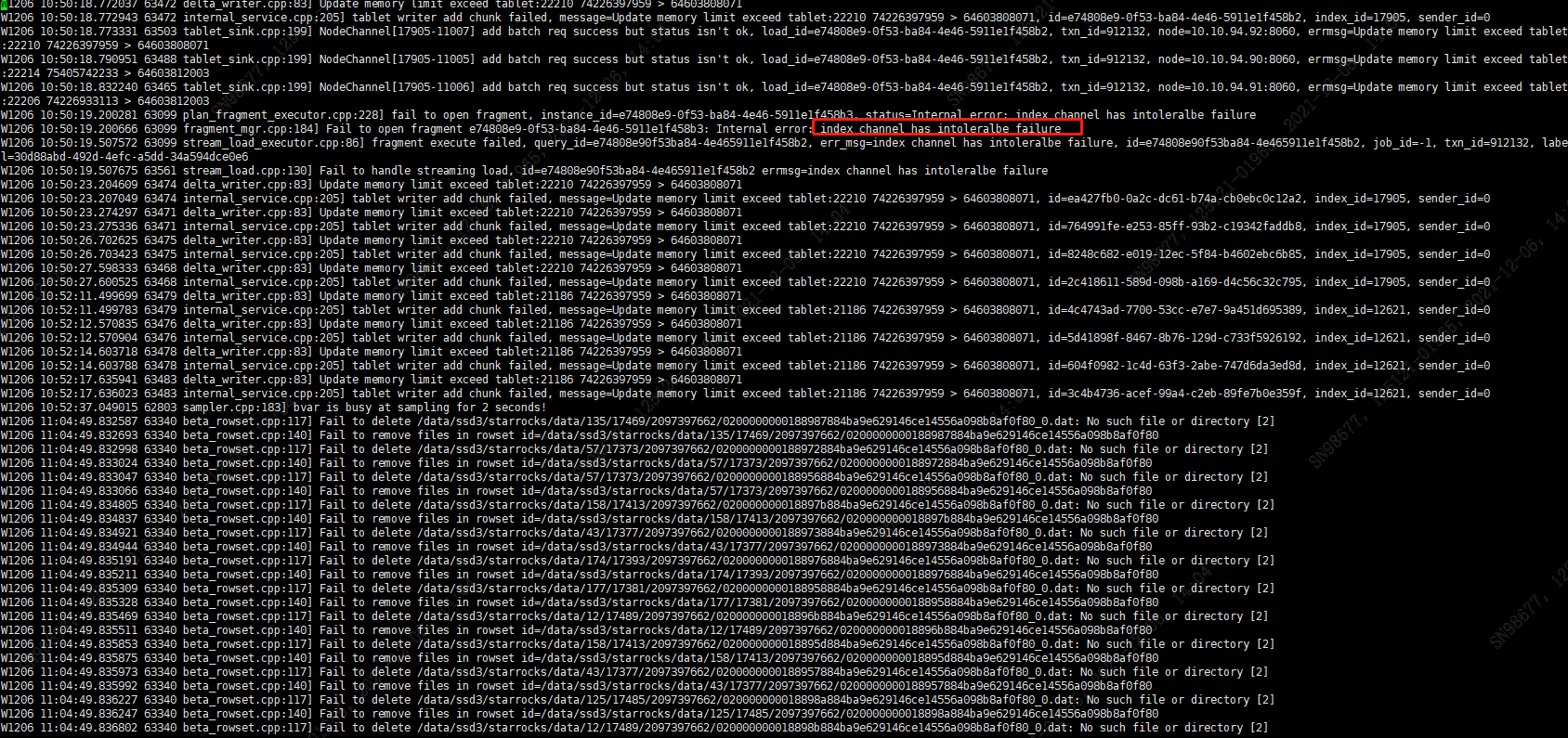
【详述】通过flink从ckp处重做任务,执行一段时间后任务报错
flink sql 配置
WITH (
‘connector’ = ‘starrocks’,
‘jdbc-url’ = ‘jdbc:mysql://10.10.xx.xx:9030?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2b8&useSSL=true&tinyInt1isBit=false’,
‘load-url’ = ‘10.10.xx.xx:8030’,
‘database-name’ = ‘ODS’,
‘table-name’ = ‘EBS_WIP_WIP_DISCRETE_JOBS’,
‘username’ = ‘it’,
‘password’ = ‘xxxxxx’,
‘sink.semantic’ = ‘at-least-once’,
‘sink.buffer-flush.interval-ms’ = ‘30000’,
‘sink.max-retries’ = ‘3’,
‘sink.properties.column_separator’ = ‘\x01’,
‘sink.properties.row_delimiter’ = ‘\x02’
任务并发度为1 ,一共有78个任务在执行导入
【背景】采用的是primary key数据模型,通过flink导入数据
【业务影响】
【StarRocks版本】例如:1.19.1
【集群规模】例如:3fe(1 follower+2observer)+7be
【附件】