
【详述】spark-connect数据导出,批处理数据量大小导致导出失败
【背景】使用spark时调整了starrocks.batch.size的参数
【业务影响】
【StarRocks版本】1.19.1
【集群规模】:3fe(1 follower+2observer)+6be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/256G/万兆
【附件】
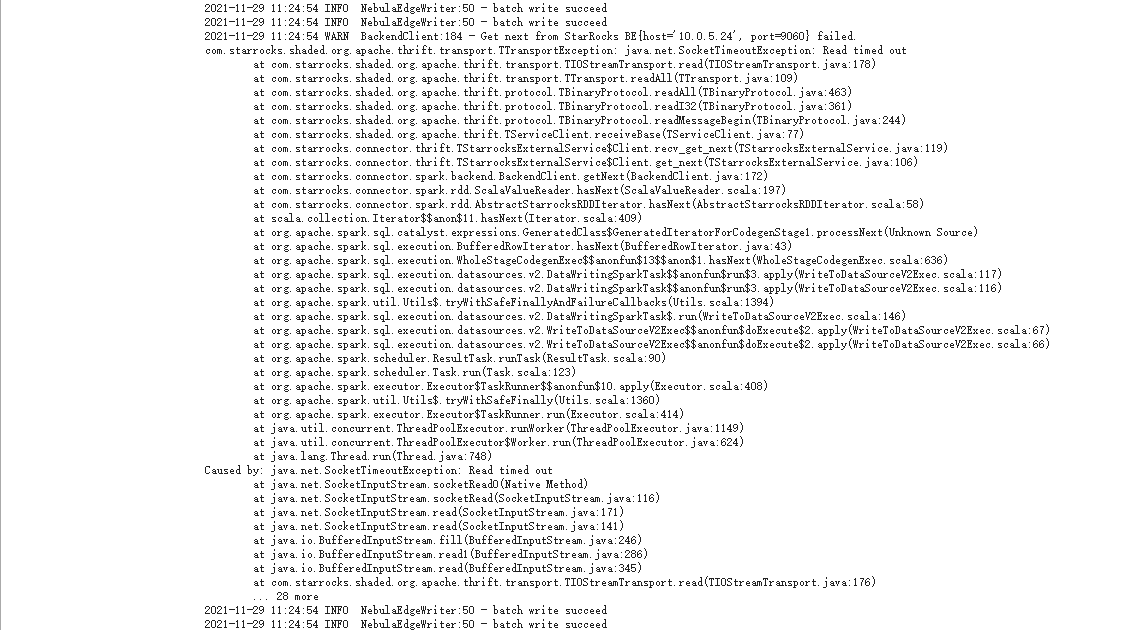
调整starrocks.batch.size为1024,导出报错,read time out
调整starrocks.batch.size为20480,导出报错,MaxMessageSize reached
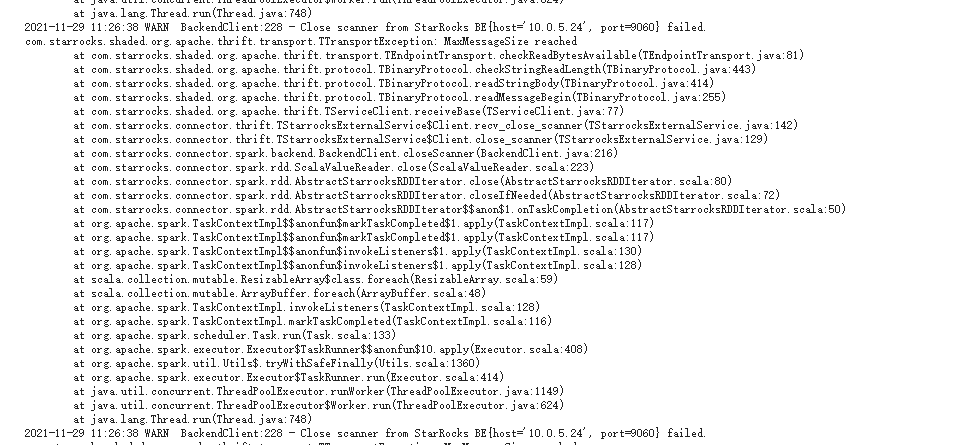
be是否有参数可以调整MaxMessageSize的最大值?